Concepts in text processing¶
Corpora¶
Corpus is a large collection of texts. It is a body of written or spoken material upon which a linguistic analysis is based.
A corpus provides grammarians, lexicographers, and other interested parties with better discriptions of a language. Computer-procesable corpora allow linguists to adopt the principle of total accountability, retrieving all the occurrences of a particular word or structure for inspection or randomly selcted samples.
Corpus analysis provide lexical information, morphosyntactic information, semantic information and pragmatic information.
Tokens¶
A token is the technical name for a sequence of characters, that we want to treat as a group.
The vocabulary of a text is just the set of tokens that it uses, since in a set, all duplicates are collapsed together. In Python we can obtain the vocabulary items with the command:
set().
Stopwords¶
Stopwords are common words that generally do not contribute to the meaning of a sentence, at least for the purposes of information retrieval and natural language processing.
These are words such as the and a. Most search engines will filter out stopwords from search queries and documents in order to save space in their index.
Stemming¶
Stemming is a technique to remove affixes from a word, ending up with the stem. For example, the stem of cooking is cook , and a good stemming algorithm knows that the ing suffix can be removed.
Stemming is most commonly used by search engines for indexing words. Instead of storing all forms of a word, a search engine can store only the stems, greatly reducing the size of index while increasing retrieval accuracy.
Frequency Counts¶
- Frequency Counts the number of hits.
- Frequency counts require finding all the occurences of a particular feature in the corpus.
- So it is implicit in concordancing. Software is used for this purpose. Frequency counts can be explained statistically.
Word Segmenter¶
Word segmentation is the problem of dividing a string of written language into its component words.
In English and many other languages using some form of the Latin alphabet, the space is a good approximation of a word divider (word delimiter). (Some examples where the space character alone may not be sufficient include contractions like can't for can not.)
However the equivalent to this character is not found in all written scripts, and without it word segmentation is a difficult problem. Languages which do not have a trivial word segmentation process include Chinese, Japanese, where sentences but not words are delimited, Thai and Lao, where phrases and sentences but not words are delimited, and Vietnamese, where syllables but not words are delimited.
Part-Of-Speech Tagger¶
In corpus linguistics, part-of-speech tagging (POS tagging or POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e. relationship with adjacent and related words in a phrase, sentence, or paragraph.
A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
Named Entity Recognizer¶
- Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify elements in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages.
Word embeddings¶
- Word frequency based
- Prediction based
Word embeddings¶
This is a word embedding for the word “king” (GloVe vector trained on Wikipedia, see here):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
King¶

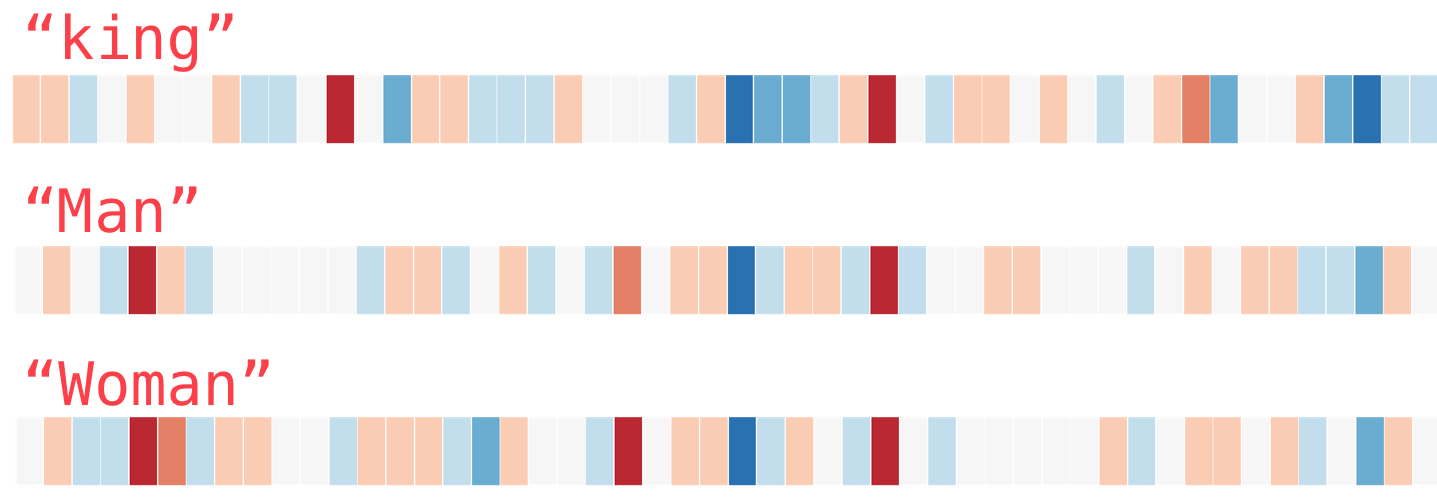

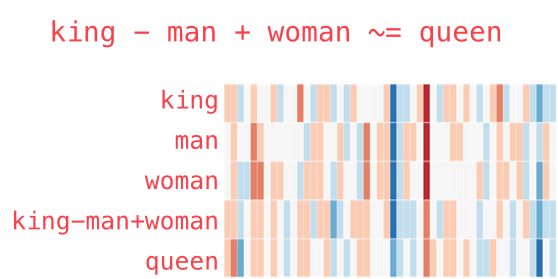
Analogy¶
Text Feature Extractors¶
import findspark
findspark.init('/opt/apps/SPARK3/spark-current')
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Python Spark with TM").getOrCreate()
from pyspark.ml.feature import Tokenizer
sentenceData = spark.createDataFrame([
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
], ["label", "sentence"])
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
tokenizer
Tokenizer_2393f7477061
wordsData = tokenizer.transform(sentenceData)
wordsData.show()
[Stage 5:==============> (1 + 3) / 4]
+-----+--------------------+--------------------+ |label| sentence| words| +-----+--------------------+--------------------+ | 0.0|Hi I heard about ...|[hi, i, heard, ab...| | 0.0|I wish Java could...|[i, wish, java, c...| | 1.0|Logistic regressi...|[logistic, regres...| +-----+--------------------+--------------------+
Count vectorizer¶
Denote a term by $t$, a document by $d$, and the corpus by $D$. Term frequency $TF(t,d)$ is the number of times that term $t$ appears in document $d$.
# CountVectorizer can be used to get term frequency vectors
from pyspark.ml.feature import CountVectorizer
cv = CountVectorizer(inputCol="words", outputCol="rawFeatures")
model = cv.fit(wordsData)
result = model.transform(wordsData)
result.show(truncate=False)
+-----+-----------------------------------+------------------------------------------+----------------------------------------------------+ |label|sentence |words |rawFeatures | +-----+-----------------------------------+------------------------------------------+----------------------------------------------------+ |0.0 |Hi I heard about Spark |[hi, i, heard, about, spark] |(16,[0,1,2,3,5],[1.0,1.0,1.0,1.0,1.0]) | |0.0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes]|(16,[0,4,7,8,9,10,13],[1.0,1.0,1.0,1.0,1.0,1.0,1.0])| |1.0 |Logistic regression models are neat|[logistic, regression, models, are, neat] |(16,[6,11,12,14,15],[1.0,1.0,1.0,1.0,1.0]) | +-----+-----------------------------------+------------------------------------------+----------------------------------------------------+
IDF¶
- If we only use term frequency to measure the importance, it is very easy to over-emphasize terms that appear very often but carry little information about the document, e.g., “a”, “the”, and “of”. If a term appears very often across the corpus, it means it doesn’t carry special information about a particular document.
- IDF (Inverse document frequency) is a numerical measure of how much information a term provides: $$IDF(t, D) = \log \frac{|D| + 1}{DF(t, D) + 1},$$ where $|D|$ is the total number of documents in the corpus, and document frequency $DF(t,D)$ is the number of documents that contains term $t$.
- Since logarithm is used, if a term appears in all documents, its IDF value becomes 0. Note that a smoothing term is applied to avoid dividing by zero for terms outside the corpus.
IDF¶
IDFis anEstimatorwhich is fit on a dataset and produces anIDFModel.The
IDFModeltakes feature vectors (generally created fromHashingTForCountVectorizer) and scales each feature.Intuitively, it down-weights features which appear frequently in a corpus.
TF-IDF measure is simply the product of TF and IDF.
from pyspark.ml.feature import HashingTF, IDF
# We use IDF to rescale the feature vectors
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(result)
rescaledData = idfModel.transform(result)
rescaledData.select("label", "features").show(truncate=False)
+-----+--------------------------------------------------------------------------------------------------------------------------------------------------------------+ |label|features | +-----+--------------------------------------------------------------------------------------------------------------------------------------------------------------+ |0.0 |(16,[0,1,2,3,5],[0.28768207245178085,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453]) | |0.0 |(16,[0,4,7,8,9,10,13],[0.28768207245178085,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453])| |1.0 |(16,[6,11,12,14,15],[0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453]) | +-----+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
HashingTF¶
# Alternatively, we can use hashingTF to extract features
from pyspark.ml.feature import HashingTF, IDF
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(wordsData)
featurizedData.show(featurizedData.count(), truncate=False)
+-----+-----------------------------------+------------------------------------------+-----------------------------------------------+ |label|sentence |words |rawFeatures | +-----+-----------------------------------+------------------------------------------+-----------------------------------------------+ |0.0 |Hi I heard about Spark |[hi, i, heard, about, spark] |(20,[6,8,13,16],[1.0,1.0,1.0,2.0]) | |0.0 |I wish Java could use case classes |[i, wish, java, could, use, case, classes]|(20,[0,2,7,13,15,16],[1.0,1.0,2.0,1.0,1.0,1.0])| |1.0 |Logistic regression models are neat|[logistic, regression, models, are, neat] |(20,[3,4,6,11,19],[1.0,1.0,1.0,1.0,1.0]) | +-----+-----------------------------------+------------------------------------------+-----------------------------------------------+
Word2Vec¶
Word2Vec is an Estimator which takes sequences of words representing documents and trains a Word2VecModel.
The model maps each word to a unique fixed-size vector.
The Word2VecModel transforms each document into a vector using the average of all words in the document; this vector can then be used as features for prediction, document similarity calculations, etc. Please refer to the MLlib user guide on Word2Vec for more details.
from pyspark.ml.feature import Word2Vec
# Input data: Each row is a bag of words from a sentence or document.
documentDF = spark.createDataFrame([
("Hi I heard about Spark".split(" "), ),
("I wish Java could use case classes".split(" "), ),
("Logistic regression models are neat".split(" "), )
], ["text"])
# Learn a mapping from words to Vectors.
word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result")
model = word2Vec.fit(documentDF)
result = model.transform(documentDF)
for row in result.collect():
text, vector = row
print("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector)))
Text: [Hi, I, heard, about, Spark] => Vector: [-0.03650839794427157,-0.06438489258289337,0.009828132763504983] Text: [I, wish, Java, could, use, case, classes] => Vector: [0.029274502636066502,-0.06429682578891516,0.01661697286181152] Text: [Logistic, regression, models, are, neat] => Vector: [0.06004725620150567,0.005438234098255635,0.017221370339393617]
Remove stop words¶
from pyspark.ml.feature import StopWordsRemover
sentenceData = spark.createDataFrame([
(0, ["I", "saw", "the", "red", "balloon"]),
(1, ["Mary", "had", "a", "little", "lamb"])
], ["id", "raw"])
remover = StopWordsRemover(inputCol="raw", outputCol="filtered")
remover.transform(sentenceData).show(truncate=False)
+---+----------------------------+--------------------+ |id |raw |filtered | +---+----------------------------+--------------------+ |0 |[I, saw, the, red, balloon] |[saw, red, balloon] | |1 |[Mary, had, a, little, lamb]|[Mary, little, lamb]| +---+----------------------------+--------------------+
$n$-gram¶
An $n$-gram is a sequence of $n$ tokens (typically words) for some integer $n$. The
NGramclass can be used to transform input features into $n$-grams.NGramtakes as input a sequence of strings (e.g. the output of aTokenizer).The parameter
nis used to determine the number of terms in each $n$-gram.The output will consist of a sequence of $n$-grams where each $n$-gram is represented by a space-delimited string of $n$ consecutive words. If the input sequence contains fewer than $n$ strings, no output is produced.
from pyspark.ml.feature import NGram
wordDataFrame = spark.createDataFrame([
(0, ["Hi", "I", "heard", "about", "Spark"]),
(1, ["I", "wish", "Java", "could", "use", "case", "classes"]),
(2, ["Logistic", "regression", "models", "are", "neat"]),
(3, ["I", "like", "regression", "models"]),
], ["id", "words"])
ngram = NGram(n=2, inputCol="words", outputCol="ngrams")
ngramDataFrame = ngram.transform(wordDataFrame)
ngramDataFrame.select("ngrams").show(truncate=False)
+------------------------------------------------------------------+ |ngrams | +------------------------------------------------------------------+ |[Hi I, I heard, heard about, about Spark] | |[I wish, wish Java, Java could, could use, use case, case classes]| |[Logistic regression, regression models, models are, are neat] | |[I like, like regression, regression models] | +------------------------------------------------------------------+
Topic modelling with LDA¶
LDA is an unsupervised method that models documents and topics based on Dirichlet distribution, wherein each document is considered to be a distribution over various topics and each topic is modeled as a distribution over words.
Therefore, given a collection of documents, LDA outputs a set of topics, with each topic being associated with a set of words.
To model the distributions, LDA also requires the number of topics (often denoted by $k$) as an input. For instance, the following are the topics extracted from a random set of tweets from Canadian users where $k = 3$:
- Topic 1: great, day, happy, weekend, tonight, positive experiences
- Topic 2: food, wine, beer, lunch, delicious, dining
- Topic 3: home, real estate, house, tips, mortgage, real estate
from pyspark.ml.clustering import LDA
# Loads data.
dataset = spark.read.format("libsvm").load("file:///opt/apps/SPARK3/spark-3.3.1-hadoop3.2-1.0.4/data/mllib/sample_lda_libsvm_data.txt")
dataset.head(10)
23/12/20 09:20:23 WARN [Thread-6] LibSVMFileFormat: 'numFeatures' option not specified, determining the number of features by going though the input. If you know the number in advance, please specify it via 'numFeatures' option to avoid the extra scan.
[Row(label=0.0, features=SparseVector(11, {0: 1.0, 1: 2.0, 2: 6.0, 4: 2.0, 5: 3.0, 6: 1.0, 7: 1.0, 10: 3.0})),
Row(label=1.0, features=SparseVector(11, {0: 1.0, 1: 3.0, 3: 1.0, 4: 3.0, 7: 2.0, 10: 1.0})),
Row(label=2.0, features=SparseVector(11, {0: 1.0, 1: 4.0, 2: 1.0, 5: 4.0, 6: 9.0, 8: 1.0, 9: 2.0})),
Row(label=3.0, features=SparseVector(11, {0: 2.0, 1: 1.0, 3: 3.0, 6: 5.0, 8: 2.0, 9: 3.0, 10: 9.0})),
Row(label=4.0, features=SparseVector(11, {0: 3.0, 1: 1.0, 2: 1.0, 3: 9.0, 4: 3.0, 6: 2.0, 9: 1.0, 10: 3.0})),
Row(label=5.0, features=SparseVector(11, {0: 4.0, 1: 2.0, 3: 3.0, 4: 4.0, 5: 5.0, 6: 1.0, 7: 1.0, 8: 1.0, 9: 4.0})),
Row(label=6.0, features=SparseVector(11, {0: 2.0, 1: 1.0, 3: 3.0, 6: 5.0, 8: 2.0, 9: 2.0, 10: 9.0})),
Row(label=7.0, features=SparseVector(11, {0: 1.0, 1: 1.0, 2: 1.0, 3: 9.0, 4: 2.0, 5: 1.0, 6: 2.0, 9: 1.0, 10: 3.0})),
Row(label=8.0, features=SparseVector(11, {0: 4.0, 1: 4.0, 3: 3.0, 4: 4.0, 5: 2.0, 6: 1.0, 7: 3.0})),
Row(label=9.0, features=SparseVector(11, {0: 2.0, 1: 8.0, 2: 2.0, 4: 3.0, 6: 2.0, 8: 2.0, 9: 7.0, 10: 2.0}))]
# Trains a LDA model.
lda = LDA(k=10, maxIter=10)
model = lda.fit(dataset)
ll = model.logLikelihood(dataset)
lp = model.logPerplexity(dataset)
print("The lower bound on the log likelihood of the entire corpus: " + str(ll))
print("The upper bound on perplexity: " + str(lp))
The lower bound on the log likelihood of the entire corpus: -813.4248831661522 The upper bound on perplexity: 3.1285572429467394
# Describe topics.
topics = model.describeTopics(3)
print("The topics described by their top-weighted terms:")
topics.show(truncate=False)
The topics described by their top-weighted terms: +-----+-----------+---------------------------------------------------------------+ |topic|termIndices|termWeights | +-----+-----------+---------------------------------------------------------------+ |0 |[7, 9, 5] |[0.10355315771318357, 0.09868477542600189, 0.09843933396181498]| |1 |[7, 0, 4] |[0.1040835683637236, 0.09777264441955393, 0.09491544531420787] | |2 |[1, 7, 3] |[0.10883139259156634, 0.1010495014616249, 0.09914976885499399] | |3 |[3, 10, 4] |[0.1983476998673522, 0.1435569478193074, 0.13846108456230832] | |4 |[10, 6, 8] |[0.14754394488720485, 0.1428476094030612, 0.1174186236586855] | |5 |[9, 3, 2] |[0.11135044188307669, 0.10322197793809397, 0.09605099904319529]| |6 |[0, 3, 2] |[0.105444504994888, 0.10358278468481515, 0.0966848664289974] | |7 |[7, 3, 5] |[0.10649500869062604, 0.10358063540532723, 0.09789819385986522]| |8 |[5, 2, 0] |[0.18700181680948244, 0.14561945767564574, 0.10788959398249173]| |9 |[1, 8, 5] |[0.12346590882340182, 0.10252391733926622, 0.09998132536463791]| +-----+-----------+---------------------------------------------------------------+
# Shows the result
transformed = model.transform(dataset)
transformed.show(truncate=False)
+-----+---------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |label|features |topicDistribution | +-----+---------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |0.0 |(11,[0,1,2,4,5,6,7,10],[1.0,2.0,6.0,2.0,3.0,1.0,1.0,3.0]) |[0.004698602728920953,0.004698634080926529,0.004698637202254378,0.005844475253299762,0.004866798551297562,0.004698600768126231,0.004698606820891948,0.004698673338562837,0.9563983130049795,0.004698658250740391] | |1.0 |(11,[0,1,3,4,7,10],[1.0,3.0,1.0,3.0,2.0,1.0]) |[0.007838337480010569,0.007838420220564798,0.007838404472487511,0.928598071043226,0.008118216756744411,0.007838298890798144,0.007838341839971404,0.007838452327699513,0.008415067513561348,0.007838389454936066] | |2.0 |(11,[0,1,2,5,6,8,9],[1.0,4.0,1.0,4.0,9.0,1.0,2.0]) |[0.004085118922566911,0.004085110804829474,0.00408515310722593,0.005080330342659554,0.6051790990754575,0.004085076848871843,0.004085095075598439,0.004085130240048597,0.3611446697398778,0.004085215842863832] | |3.0 |(11,[0,1,3,6,8,9,10],[2.0,1.0,3.0,5.0,2.0,3.0,9.0]) |[0.003613102648185557,0.0036130769068053693,0.0036130878578075516,0.46107457827232046,0.509755099912797,0.003613112733697121,0.003613082902692725,0.0036130832266904256,0.0038787070418449293,0.0036130684971588424] | |4.0 |(11,[0,1,2,3,4,6,9,10],[3.0,1.0,1.0,9.0,3.0,2.0,1.0,3.0]) |[0.003914451529009302,0.0039144558967470254,0.003914467265232897,0.9643419295798072,0.0040544525384615775,0.003914477635649164,0.003914476011611889,0.00391447599619608,0.004202380116646159,0.003914433430638668] | |5.0 |(11,[0,1,3,4,5,6,7,8,9],[4.0,2.0,3.0,4.0,5.0,1.0,1.0,1.0,4.0]) |[0.0036132168111503754,0.003613196120850995,0.0036131785615695113,0.6235696899391607,0.00374236347405828,0.003613212782450783,0.0036131919866874427,0.0036131862700200168,0.34739560110076617,0.003613162953285503] | |6.0 |(11,[0,1,3,6,8,9,10],[2.0,1.0,3.0,5.0,2.0,2.0,9.0]) |[0.0037577778677890072,0.003757756189196194,0.0037577617584120776,0.5034872405713712,0.4661743832008508,0.0037577812762059973,0.0037577608637029865,0.003757762612816266,0.004034021252394705,0.003757754407260618] | |7.0 |(11,[0,1,2,3,4,5,6,9,10],[1.0,1.0,1.0,9.0,2.0,1.0,2.0,1.0,3.0])|[0.004270818246732474,0.004270803586560807,0.004270819011499848,0.9610954911009587,0.0044235996367197085,0.004270832081412512,0.004270826241900094,0.004270850376446298,0.004585158107352565,0.00427080161041703] | |8.0 |(11,[0,1,3,4,5,6,7],[4.0,4.0,3.0,4.0,2.0,1.0,3.0]) |[0.004270880649735316,0.004270901210918333,0.00427087559944003,0.9610948216458115,0.0044233742653302915,0.004270822446836553,0.0042708760169687015,0.004270918110563465,0.004585641090904182,0.004270888963491903] | |9.0 |(11,[0,1,2,4,6,8,9,10],[2.0,8.0,2.0,3.0,2.0,2.0,7.0,2.0]) |[0.0032391673855049798,0.0032391436886713555,0.0032391511274671284,0.9704927120791975,0.0033556743659078447,0.0032392027031831047,0.003239143784132646,0.0032391144190771206,0.0034775541225712144,0.0032391363242870604]| |10.0 |(11,[0,1,2,3,5,6,9,10],[1.0,1.0,1.0,9.0,2.0,2.0,3.0,3.0]) |[0.004085015535704517,0.004084964586124705,0.004084996375954626,0.9627877385195561,0.004231429205913753,0.004085028123265747,0.004084995679791362,0.004085016560782856,0.004385857719228803,0.0040849576936773] | |11.0 |(11,[0,1,4,5,6,7,9],[4.0,1.0,4.0,5.0,1.0,3.0,1.0]) |[0.004698614197775369,0.004698662809333,0.004698604627352072,0.00584309155155734,0.0048664552576085296,0.004698580821844376,0.004698605821860598,0.004698631788928853,0.956400169260002,0.004698583863737762] | +-----+---------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Topic modeling: Airline review¶
rawdata = spark.read.load("/data/airline.csv", format="csv", header=True)
rawdata = rawdata.dropDuplicates(['content']).select("airline_name", "date", "author_country", "overall_rating", "cabin_flown", "content", "recommended")
raw_cols = rawdata.columns
rawdata.printSchema()
rawdata.show(5, truncate=False)
root |-- airline_name: string (nullable = true) |-- date: string (nullable = true) |-- author_country: string (nullable = true) |-- overall_rating: string (nullable = true) |-- cabin_flown: string (nullable = true) |-- content: string (nullable = true) |-- recommended: string (nullable = true) +-----------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+ |airline_name |date |author_country |overall_rating |cabin_flown |content |recommended| +-----------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+ |tap-portugal |2015-07-21 |Germany |1.0 |Economy | I fly up to Lisbon on a near weekly basis generally on Lufthansa. When there are no seats left I'm force to book with TAP. I'm continuously disappointed and frustrated with TAP, last year I missed my wedding anniversary dinner when I took the mid-afternoon flight home. At Lisbon and with 10 minutes to go before scheduled boarding were suddenly told there was a 6 hour delay! If they'd told us earlier I'd have got another airline and made the dinner. When I wrote a constructive letter to TAP the Costumer service replied saying she was unable to 'communicate' reasons for delays. Second attempt, an automatic reply, until today no one reply on a proper way to my complain. Once again I was forced to fly TAP for the first time in a year and I got a 2 hours delayed flight, this is shocking. Once again why or why are they so dreadfully poor on punctuality! The snack they offered on board was worst since last time. Shocking airline which does not seem to be improving. By the way in 3 years on Lufthansa I have been delayed once for 20 minutes.|0 | |now | the crew was professional. At this price point | though I admit that's a pretty low bar. For the most part | you are stuck until Spirit can get you there | it feels like someone is thrusting their knuckle - two knuckles - into your back. There is no curbside check-in. And because Spirit has no reciprocity with other airlines| all you really can expect is a seat on a jet to get you from point A to point B. That's all |9.0 | |seat has an outstanding pitch| pillow and noise-cancelling headphones. Pyjamas and slippers were given out later on the segments to/from IAD. Staff service was very good on all segments and dine when you want service was good | with a blanket | and provided very good value for money. Baggage delivery at IAD was much delayed| despite its showy architecture. Certainly no match for SIN and HKG. Check-in at CMB was efficient | though cutbacks are very evident in their menus. Of the four flight segments |4.0 | |did offer me a full refund | you have to pay for entertainment - something you don't usually expect on a 9-hour flight. The cabin crew could not make themselves clearly understood either. I will say a few good things about the airline| let's just say I was lucky enough to have some pretty powerful sleeping pills. The Economy seating on the A330 was cramped and narrow - something which you don't want when you're 6'1"" tall. Additionally|Solo Leisure | so long as you have patience and the gumption to pre-order food." | though. I had ordered a nasi lemak when I booked the flight - this is unbelievably delicious and thoroughly recommended. Also |null | |spirit-airlines |2015-06-26 |United States |1.0 |Economy |"1.5 hours late departure - no apology or explanation as to why. We literally sweated all the way here as the cabin was about 80-84 degrees. Waited for our baggage for over an hour to even start moving. This airline is not a ""value"". I've flown with them four times and not once has my flight been on time. This will be the last time I fly with them." |0 | +-----------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+ only showing top 5 rows
Remove non ASCII characters¶
# remove non ASCII characters
def strip_non_ascii(data_str):
''' Returns the string without non ASCII characters'''
stripped = (c for c in data_str if 0 < ord(c) < 127)
return ''.join(stripped)
Check it blank line or not¶
# check to see if a row only contains whitespaceG
def check_blanks(data_str):
is_blank = str(data_str.isspace())
return is_blank
Fixed abbreviation¶
# fixed abbreviation
def fix_abbreviation(data_str):
data_str = data_str.lower()
data_str = re.sub(r'\bthats\b', 'that is', data_str)
data_str = re.sub(r'\bive\b', 'i have', data_str)
data_str = re.sub(r'\bim\b', 'i am', data_str)
data_str = re.sub(r'\bya\b', 'yeah', data_str)
data_str = re.sub(r'\bcant\b', 'can not', data_str)
data_str = re.sub(r'\bdont\b', 'do not', data_str)
data_str = re.sub(r'\bwont\b', 'will not', data_str)
data_str = re.sub(r'\bid\b', 'i would', data_str)
data_str = re.sub(r'wtf', 'what the fuck', data_str)
data_str = re.sub(r'\bwth\b', 'what the hell', data_str)
data_str = re.sub(r'\br\b', 'are', data_str)
data_str = re.sub(r'\bu\b', 'you', data_str)
data_str = re.sub(r'\bk\b', 'OK', data_str)
data_str = re.sub(r'\bsux\b', 'sucks', data_str)
data_str = re.sub(r'\bno+\b', 'no', data_str)
data_str = re.sub(r'\bcoo+\b', 'cool', data_str)
data_str = re.sub(r'rt\b', '', data_str)
data_str = data_str.strip()
return data_str
Remove irrelevant features¶
# remove irrelevant features
def remove_features(data_str):
# compile regex
url_re = re.compile('https?://(www.)?\w+\.\w+(/\w+)*/?')
punc_re = re.compile('[%s]' % re.escape(string.punctuation))
num_re = re.compile('(\\d+)')
mention_re = re.compile('@(\w+)')
alpha_num_re = re.compile("^[a-z0-9_.]+$")
# convert to lowercase
data_str = data_str.lower()
# remove hyperlinks
data_str = url_re.sub(' ', data_str)
# remove @mentions
data_str = mention_re.sub(' ', data_str)
# remove puncuation
data_str = punc_re.sub(' ', data_str)
# remove numeric 'words'
data_str = num_re.sub(' ', data_str)
# remove non a-z 0-9 characters and words shorter than 1 characters
list_pos = 0
cleaned_str = ''
for word in data_str.split():
if list_pos == 0:
if alpha_num_re.match(word) and len(word) > 1:
cleaned_str = word
else:
cleaned_str = ' '
else:
if alpha_num_re.match(word) and len(word) > 1:
cleaned_str = cleaned_str + ' ' + word
else:
cleaned_str += ' '
list_pos += 1
# remove unwanted space, *.split() will automatically split on
# whitespace and discard duplicates, the " ".join() joins the
# resulting list into one string.
return " ".join(cleaned_str.split())
Remove stopwords¶
# removes stop words
def remove_stops(data_str):
# expects a string
stops = set(stopwords.words("english"))
list_pos = 0
cleaned_str = ''
text = data_str.split()
for word in text:
if word not in stops:
# rebuild cleaned_str
if list_pos == 0:
cleaned_str = word
else:
cleaned_str = cleaned_str + ' ' + word
list_pos += 1
return cleaned_str
Part-of-Speech Tagging¶
# Part-of-Speech Tagging
def tag_and_remove(data_str):
cleaned_str = ' '
# noun tags
nn_tags = ['NN', 'NNP', 'NNP', 'NNPS', 'NNS']
# adjectives
jj_tags = ['JJ', 'JJR', 'JJS']
# verbs
vb_tags = ['VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ']
nltk_tags = nn_tags + jj_tags + vb_tags
# break string into 'words'
text = data_str.split()
# tag the text and keep only those with the right tags
tagged_text = pos_tag(text)
for tagged_word in tagged_text:
if tagged_word[1] in nltk_tags:
cleaned_str += tagged_word[0] + ' '
return cleaned_str
Lemmatization¶
# lemmatization
def lemmatize(data_str):
# expects a string
list_pos = 0
cleaned_str = ''
lmtzr = WordNetLemmatizer()
text = data_str.split()
tagged_words = pos_tag(text)
for word in tagged_words:
if 'v' in word[1].lower():
lemma = lmtzr.lemmatize(word[0], pos='v')
else:
lemma = lmtzr.lemmatize(word[0], pos='n')
if list_pos == 0:
cleaned_str = lemma
else:
cleaned_str = cleaned_str + ' ' + lemma
list_pos += 1
return cleaned_str
Setup pyspark udf function¶
from pyspark.sql.functions import udf, col
from pyspark.sql.types import StringType, DoubleType, DateType
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.corpus import stopwords
from nltk import pos_tag
import string
import re
# setup pyspark udf function
strip_non_ascii_udf = udf(strip_non_ascii, StringType())
check_blanks_udf = udf(check_blanks, StringType())
fix_abbreviation_udf = udf(fix_abbreviation, StringType())
remove_stops_udf = udf(remove_stops, StringType())
remove_features_udf = udf(remove_features, StringType())
tag_and_remove_udf = udf(tag_and_remove, StringType())
lemmatize_udf = udf(lemmatize, StringType())
from datetime import datetime
from pyspark.sql.functions import col
# https://docs.python.org/2/library/datetime.html#strftime-and-strptime-behavior
# 21-Jun-14 <----> %d-%b-%y
to_date = udf (lambda x: datetime.strptime(x, '%d-%b-%y'), DateType())
rawdata = rawdata.withColumn('date', to_date(col('date')))
rawdata.printSchema()
root |-- airline_name: string (nullable = true) |-- date: date (nullable = true) |-- author_country: string (nullable = true) |-- overall_rating: string (nullable = true) |-- cabin_flown: string (nullable = true) |-- content: string (nullable = true) |-- recommended: string (nullable = true)
rawdata = rawdata.withColumn('non_asci', strip_non_ascii_udf(rawdata['content']))
raw_cols = rawdata.columns
raw_cols
['airline_name', 'date', 'author_country', 'overall_rating', 'cabin_flown', 'content', 'recommended', 'non_asci']
rawdata = rawdata.select(raw_cols+['non_asci']).withColumn('fixed_abbrev',fix_abbreviation_udf(rawdata['non_asci']))
rawdata = rawdata.select(raw_cols+['fixed_abbrev']).withColumn('stop_text',remove_stops_udf(rawdata['fixed_abbrev']))
rawdata = rawdata.select(raw_cols+['stop_text']).withColumn('feat_text',remove_features_udf(rawdata['stop_text']))
rawdata = rawdata.select(raw_cols+['feat_text']).withColumn('tagged_text',tag_and_remove_udf(rawdata['feat_text']))
rawdata = rawdata.select(raw_cols+['tagged_text']).withColumn('lemm_text',lemmatize_udf(rawdata['tagged_text']))
rawdata = rawdata.select(raw_cols+['lemm_text']).withColumn("is_blank", check_blanks_udf(rawdata["lemm_text"]))
from pyspark.sql.functions import monotonically_increasing_id
# Create Unique ID
rawdata = rawdata.withColumn("uid", monotonically_increasing_id())
data = rawdata.filter(rawdata["is_blank"] == "False")
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
from pyspark.ml import Pipeline
from pyspark.ml.classification import NaiveBayes, RandomForestClassifier
from pyspark.ml.clustering import LDA
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.tuning import ParamGridBuilder
from pyspark.ml.tuning import CrossValidator
from pyspark.ml.feature import IndexToString, StringIndexer, VectorIndexer
from pyspark.ml.feature import CountVectorizer
# Configure an ML pipeline, which consists of tree stages: tokenizer, hashingTF, and nb.
tokenizer = Tokenizer(inputCol="lemm_text", outputCol="words")
vectorizer = CountVectorizer(inputCol= "words", outputCol="rawFeatures")
idf = IDF(inputCol="rawFeatures", outputCol="features")
lda = LDA(k=5, seed=1)
pipeline = Pipeline(stages=[tokenizer, vectorizer, idf, lda])
data = data.filter(data.content.isNotNull())
model = pipeline.fit(data)
from pyspark.sql.types import ArrayType, StringType
def termsIdx2Term(vocabulary):
def termsIdx2Term(termIndices):
return [vocabulary[int(index)] for index in termIndices]
return udf(termsIdx2Term, ArrayType(StringType()))
vectorizerModel = model.stages[1]
vocabList = vectorizerModel.vocabulary
ldatopics = model.stages[3].describeTopics(10)
final = ldatopics.withColumn("Terms", termsIdx2Term(vocabList)("termIndices"))
final.show(10, truncate = False)
+-----+-------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------+ |topic|termIndices |termWeights |Terms | +-----+-------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------+ |0 |[18, 7, 11, 2, 30, 43, 13, 14, 143, 44] |[0.004986300417694738, 0.004420169985438627, 0.003943308956439049, 0.0038013469233066305, 0.0035444891576246504, 0.0035288420551726715, 0.003498015031922209, 0.0033112340041815593, 0.0032255154295388762, 0.003209750475670939] |[delay, hour, plane, time, airpo, arrive, check, return, pm, leave] | |1 |[7, 9, 50, 13, 6, 53, 18, 23, 70, 54] |[0.004494000660613258, 0.004430918090459764, 0.004213588332072379, 0.004212786864820836, 0.0039450251731968115, 0.0038863296900590234, 0.0038262368507141742, 0.0037921754396921165, 0.0036792488032231117, 0.0036592872384431764]|[hour, get, tell, check, airline, bag, delay, go, customer, day] | |2 |[1, 15, 4, 21, 10, 22, 5, 16, 3, 26] |[0.005110081289144715, 0.004632213421593756, 0.00433082732697833, 0.004214688833466024, 0.0040679519498263835, 0.0038982120798714084, 0.0038262941332836025, 0.003775680314605875, 0.00365351564609453, 0.0035577787740803894] |[seat, class, good, business, crew, meal, food, cabin, service, economy]| |3 |[307, 210, 29, 1, 475, 11, 6, 4, 8, 3] |[0.005581584094457924, 0.004657985715136682, 0.004033443022472019, 0.0033986065132364366, 0.0029070904100119105, 0.0027614820614501, 0.002756501299358898, 0.002654776500497875, 0.0026104594136431123, 0.0025809780869122776] |[rouge, canada, air, seat, ac, plane, airline, good, fly, service] | |4 |[173, 15, 21, 61, 551, 571, 4, 665, 351, 5]|[0.006450020339599257, 0.00566981148997184, 0.005571922860214536, 0.005311012547749606, 0.004941511954120491, 0.004618996964379272, 0.0035936297864286692, 0.003434291158612825, 0.0030088873640786748, 0.0027737295054203297] |[bkk, class, business, lounge, doh, ist, good, brussels, kul, food] | +-----+-------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------+