Objectives of this lecture¶
- Introduction to distributed computing
- Discovering Hadoop and why it’s so important
- Exploring the Hadoop Distributed File System
- Digging into Hadoop MapReduce
- Putting Hadoop to work
Why Distributed systems?¶
What is Hadoop?¶
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Explaining Hadoop¶
Hadoop was originally built by a Yahoo! engineer named Doug Cutting and is now an open source project managed by the Apache Software Foundation.
- Search engine innovators like Yahoo! and Google needed to find a way to make sense of the massive amounts of data that their engines were collecting.
- Hadoop was developed because it represented the most pragmatic way to allow companies to manage huge volumes of data easily.
- Hadoop allowed big problems to be broken down into smaller elements so that analysis could be done quickly and cost-effectively.
- By breaking the big data problem into small pieces that could be processed in parallel, you can process the information and regroup the small pieces to present results.
Who use Hadoop?¶
- Facebook uses Hadoop, Hive, and HB ase for data warehousing and real-time application serving.
- Twitter uses Hadoop, Pig, and HB ase for data analysis, visualization, social graph analysis, and machine learning.
- Yahoo! uses Hadoop for data analytics, machine learning, search ranking, email antispam, ad optimization...
- eBay, Samsung, Rackspace, J.P. Morgan, Groupon, LinkedIn, AOL , Last.fm...
Now let us try these commands:¶
hadoopecho $HADOOP_HOMEecho $HADOOP_CONF_DIR
hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
hostnames list[,of,host,names] hosts to use in slave mode
hosts filename list of hosts to use in slave mode
loglevel level set the log4j level for this command
workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
Client Commands:
archive create a Hadoop archive
checknative check native Hadoop and compression libraries availability
classpath prints the class path needed to get the Hadoop jar and the
required libraries
conftest validate configuration XML files
credential interact with credential providers
distch distributed metadata changer
distcp copy file or directories recursively
dtutil operations related to delegation tokens
envvars display computed Hadoop environment variables
fs run a generic filesystem user client
gridmix submit a mix of synthetic job, modeling a profiled from
production load
jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN
applications, not this command.
jnipath prints the java.library.path
kdiag Diagnose Kerberos Problems
kerbname show auth_to_local principal conversion
key manage keys via the KeyProvider
rumenfolder scale a rumen input trace
rumentrace convert logs into a rumen trace
s3guard manage metadata on S3
trace view and modify Hadoop tracing settings
version print the version
Daemon Commands:
kms run KMS, the Key Management Server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
hadoop version
Hadoop 3.2.1 Source code repository git@gitlab.alibaba-inc.com:soe/emr-hadoop.git -r 4e93f833789976263e8f06c9feb77d634e0f2cf2 Compiled by root on 2023-03-23T09:17Z Compiled with protoc 2.5.0 From source with checksum 1b543c4574cae11c43e3f6d84c15983d This command was run using /opt/apps/HADOOP-COMMON/hadoop-3.2.1-1.2.7-alinux3/share/hadoop/common/hadoop-common-3.2.1.jar
echo $HADOOP_HOME
/opt/apps/HADOOP-COMMON/hadoop-common-current/
echo $JAVA_HOME
/usr/lib/jvm/java-1.8.0
echo $HADOOP_CONF_DIR
/etc/taihao-apps/hadoop-conf
Modules of Hadoop¶
- Hadoop Distributed File System (HDFS): A reliable, high-bandwidth, low-cost, data storage cluster that facilitates the management of related files across machines.
- Hadoop MapReduce: A high-performance parallel/distributed data-processing implementation of the MapReduce algorithm.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop Common: The common utilities that support the other Hadoop modules.
HDFS¶
- HDFS is the world’s most reliable storage system.
- It is a data service that offers a unique set of capabilities needed when data volumes and velocity are high.
- The service includes a “NameNode” and multiple “data nodes”.
NameNodes¶
- HDFS works by breaking large files into smaller pieces called blocks. The blocks are stored on data nodes, and it is the responsibility of the NameNode to know what blocks on which data nodes make up the complete file.
- Data nodes are not very smart, but the NameNode is. The data nodes constantly ask the NameNode whether there is anything for them to do. This continuous behavior also tells the NameNode what data nodes are out there and how busy they are.
DataNodes¶
- Within the HDFS cluster, data blocks are replicated across multiple data nodes and access is managed by the NameNode.
Under the covers of HDFS¶
- Big data brings the big challenges of volume, velocity, and variety.
- HDFS addresses these challenges by breaking files into a related collection of smaller blocks. These blocks are distributed among the data nodes in the HDFS cluster and are managed by the NameNode.
- Block sizes are configurable and are usually 128 megabytes (MB) or 256MB, meaning that a 1GB file consumes eight 128MB blocks for its basic storage needs.
- HDFS is resilient, so these blocks are replicated throughout the cluster in case of a server failure. How does HDFS keep track of all these pieces? The short answer is file system metadata.
- HDFS metadata is stored in the NameNode, and while the cluster is operating, all the metadata is loaded into the physical memory of the NameNode server.
- Data nodes are very simplistic. They are servers that contain the blocks for a given set of files.
Data storage of HDFS¶
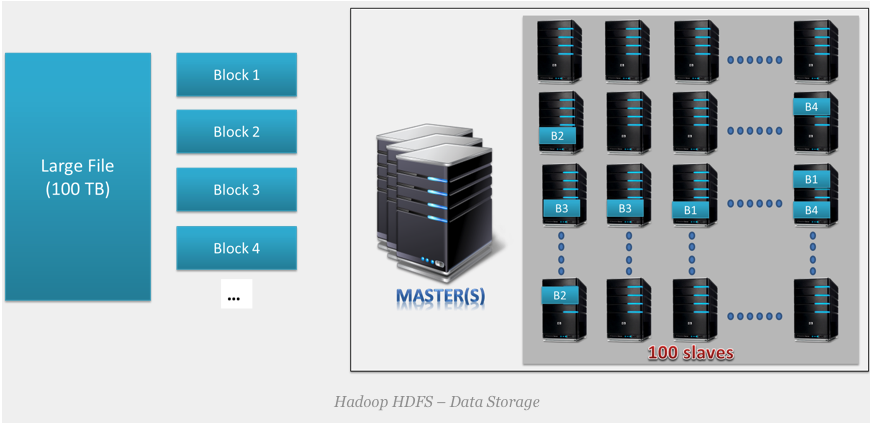
Data storage of HDFS¶
- Multiple copies of each block are stored across the cluster on different nodes.
- This is a replication of data. By default, HDFS replication factor is 3.
- It provides fault tolerance, reliability, and high availability.
- A Large file is split into $n$ number of small blocks. These blocks are stored at different nodes in the cluster in a distributed manner. Each block is replicated and stored across different nodes in the cluster.
HDFS commands¶
hadoop fshadoop fs -helphadoop fs -ls /hadoop fs -ls /user/yanfeihadoop fs -mv LICENSE license.txthadoop fs -mkdir yourNAME
hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
hadoop fs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
-appendToFile <localsrc> ... <dst> :
Appends the contents of all the given local files to the given dst file. The dst
file will be created if it does not exist. If <localSrc> is -, then the input is
read from stdin.
-cat [-ignoreCrc] <src> ... :
Fetch all files that match the file pattern <src> and display their content on
stdout.
-checksum <src> ... :
Dump checksum information for files that match the file pattern <src> to stdout.
Note that this requires a round-trip to a datanode storing each block of the
file, and thus is not efficient to run on a large number of files. The checksum
of a file depends on its content, block size and the checksum algorithm and
parameters used for creating the file.
-chgrp [-R] GROUP PATH... :
This is equivalent to -chown ... :GROUP ...
-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH... :
Changes permissions of a file. This works similar to the shell's chmod command
with a few exceptions.
-R modifies the files recursively. This is the only option currently
supported.
<MODE> Mode is the same as mode used for the shell's command. The only
letters recognized are 'rwxXt', e.g. +t,a+r,g-w,+rwx,o=r.
<OCTALMODE> Mode specifed in 3 or 4 digits. If 4 digits, the first may be 1 or
0 to turn the sticky bit on or off, respectively. Unlike the
shell command, it is not possible to specify only part of the
mode, e.g. 754 is same as u=rwx,g=rx,o=r.
If none of 'augo' is specified, 'a' is assumed and unlike the shell command, no
umask is applied.
-chown [-R] [OWNER][:[GROUP]] PATH... :
Changes owner and group of a file. This is similar to the shell's chown command
with a few exceptions.
-R modifies the files recursively. This is the only option currently
supported.
If only the owner or group is specified, then only the owner or group is
modified. The owner and group names may only consist of digits, alphabet, and
any of [-_./@a-zA-Z0-9]. The names are case sensitive.
WARNING: Avoid using '.' to separate user name and group though Linux allows it.
If user names have dots in them and you are using local file system, you might
see surprising results since the shell command 'chown' is used for local files.
-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst> :
Copy files from the local file system into fs. Copying fails if the file already
exists, unless the -f flag is given.
Flags:
-p Preserves access and modification times, ownership and the
mode.
-f Overwrites the destination if it already exists.
-t <thread count> Number of threads to be used, default is 1.
-l Allow DataNode to lazily persist the file to disk. Forces
replication factor of 1. This flag will result in reduced
durability. Use with care.
-d Skip creation of temporary file(<dst>._COPYING_).
-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst> :
Identical to the -get command.
-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ... :
Count the number of directories, files and bytes under the paths
that match the specified file pattern. The output columns are:
DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
or, with the -q option:
QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA
DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME
The -h option shows file sizes in human readable format.
The -v option displays a header line.
The -x option excludes snapshots from being calculated.
The -t option displays quota by storage types.
It should be used with -q or -u option, otherwise it will be ignored.
If a comma-separated list of storage types is given after the -t option,
it displays the quota and usage for the specified types.
Otherwise, it displays the quota and usage for all the storage
types that support quota. The list of possible storage types(case insensitive):
ram_disk, ssd, disk and archive.
It can also pass the value '', 'all' or 'ALL' to specify all the storage types.
The -u option shows the quota and
the usage against the quota without the detailed content summary.The -e option
shows the erasure coding policy.
-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst> :
Copy files that match the file pattern <src> to a destination. When copying
multiple files, the destination must be a directory. Passing -p preserves status
[topax] (timestamps, ownership, permission, ACLs, XAttr). If -p is specified
with no <arg>, then preserves timestamps, ownership, permission. If -pa is
specified, then preserves permission also because ACL is a super-set of
permission. Passing -f overwrites the destination if it already exists. raw
namespace extended attributes are preserved if (1) they are supported (HDFS
only) and, (2) all of the source and target pathnames are in the /.reserved/raw
hierarchy. raw namespace xattr preservation is determined solely by the presence
(or absence) of the /.reserved/raw prefix and not by the -p option. Passing -d
will skip creation of temporary file(<dst>._COPYING_).
-createSnapshot <snapshotDir> [<snapshotName>] :
Create a snapshot on a directory
-deleteSnapshot <snapshotDir> <snapshotName> :
Delete a snapshot from a directory
-df [-h] [<path> ...] :
Shows the capacity, free and used space of the filesystem. If the filesystem has
multiple partitions, and no path to a particular partition is specified, then
the status of the root partitions will be shown.
-h Formats the sizes of files in a human-readable fashion rather than a number
of bytes.
-du [-s] [-h] [-v] [-x] <path> ... :
Show the amount of space, in bytes, used by the files that match the specified
file pattern. The following flags are optional:
-s Rather than showing the size of each individual file that matches the
pattern, shows the total (summary) size.
-h Formats the sizes of files in a human-readable fashion rather than a number
of bytes.
-v option displays a header line.
-x Excludes snapshots from being counted.
Note that, even without the -s option, this only shows size summaries one level
deep into a directory.
The output is in the form
size disk space consumed name(full path)
-expunge [-immediate] :
Delete files from the trash that are older than the retention threshold
-find <path> ... <expression> ... :
Finds all files that match the specified expression and
applies selected actions to them. If no <path> is specified
then defaults to the current working directory. If no
expression is specified then defaults to -print.
The following primary expressions are recognised:
-name pattern
-iname pattern
Evaluates as true if the basename of the file matches the
pattern using standard file system globbing.
If -iname is used then the match is case insensitive.
-print
-print0
Always evaluates to true. Causes the current pathname to be
written to standard output followed by a newline. If the -print0
expression is used then an ASCII NULL character is appended rather
than a newline.
The following operators are recognised:
expression -a expression
expression -and expression
expression expression
Logical AND operator for joining two expressions. Returns
true if both child expressions return true. Implied by the
juxtaposition of two expressions and so does not need to be
explicitly specified. The second expression will not be
applied if the first fails.
-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst> :
Copy files that match the file pattern <src> to the local name. <src> is kept.
When copying multiple files, the destination must be a directory. Passing -f
overwrites the destination if it already exists and -p preserves access and
modification times, ownership and the mode.
-getfacl [-R] <path> :
Displays the Access Control Lists (ACLs) of files and directories. If a
directory has a default ACL, then getfacl also displays the default ACL.
-R List the ACLs of all files and directories recursively.
<path> File or directory to list.
-getfattr [-R] {-n name | -d} [-e en] <path> :
Displays the extended attribute names and values (if any) for a file or
directory.
-R Recursively list the attributes for all files and directories.
-n name Dump the named extended attribute value.
-d Dump all extended attribute values associated with pathname.
-e <encoding> Encode values after retrieving them.Valid encodings are "text",
"hex", and "base64". Values encoded as text strings are enclosed
in double quotes ("), and values encoded as hexadecimal and
base64 are prefixed with 0x and 0s, respectively.
<path> The file or directory.
-getmerge [-nl] [-skip-empty-file] <src> <localdst> :
Get all the files in the directories that match the source file pattern and
merge and sort them to only one file on local fs. <src> is kept.
-nl Add a newline character at the end of each file.
-skip-empty-file Do not add new line character for empty file.
-head <file> :
Show the first 1KB of the file.
-help [cmd ...] :
Displays help for given command or all commands if none is specified.
-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...] :
List the contents that match the specified file pattern. If path is not
specified, the contents of /user/<currentUser> will be listed. For a directory a
list of its direct children is returned (unless -d option is specified).
Directory entries are of the form:
permissions - userId groupId sizeOfDirectory(in bytes)
modificationDate(yyyy-MM-dd HH:mm) directoryName
and file entries are of the form:
permissions numberOfReplicas userId groupId sizeOfFile(in bytes)
modificationDate(yyyy-MM-dd HH:mm) fileName
-C Display the paths of files and directories only.
-d Directories are listed as plain files.
-h Formats the sizes of files in a human-readable fashion
rather than a number of bytes.
-q Print ? instead of non-printable characters.
-R Recursively list the contents of directories.
-t Sort files by modification time (most recent first).
-S Sort files by size.
-r Reverse the order of the sort.
-u Use time of last access instead of modification for
display and sorting.
-e Display the erasure coding policy of files and directories.
-mkdir [-p] <path> ... :
Create a directory in specified location.
-p Do not fail if the directory already exists
-moveFromLocal <localsrc> ... <dst> :
Same as -put, except that the source is deleted after it's copied.
-moveToLocal <src> <localdst> :
Not implemented yet
-mv <src> ... <dst> :
Move files that match the specified file pattern <src> to a destination <dst>.
When moving multiple files, the destination must be a directory.
-put [-f] [-p] [-l] [-d] <localsrc> ... <dst> :
Copy files from the local file system into fs. Copying fails if the file already
exists, unless the -f flag is given.
Flags:
-p Preserves access and modification times, ownership and the mode.
-f Overwrites the destination if it already exists.
-l Allow DataNode to lazily persist the file to disk. Forces
replication factor of 1. This flag will result in reduced
durability. Use with care.
-d Skip creation of temporary file(<dst>._COPYING_).
-renameSnapshot <snapshotDir> <oldName> <newName> :
Rename a snapshot from oldName to newName
-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ... :
Delete all files that match the specified file pattern. Equivalent to the Unix
command "rm <src>"
-f If the file does not exist, do not display a diagnostic message or
modify the exit status to reflect an error.
-[rR] Recursively deletes directories.
-skipTrash option bypasses trash, if enabled, and immediately deletes <src>.
-safely option requires safety confirmation, if enabled, requires
confirmation before deleting large directory with more than
<hadoop.shell.delete.limit.num.files> files. Delay is expected when
walking over large directory recursively to count the number of
files to be deleted before the confirmation.
-rmdir [--ignore-fail-on-non-empty] <dir> ... :
Removes the directory entry specified by each directory argument, provided it is
empty.
-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>] :
Sets Access Control Lists (ACLs) of files and directories.
Options:
-b Remove all but the base ACL entries. The entries for user, group
and others are retained for compatibility with permission bits.
-k Remove the default ACL.
-R Apply operations to all files and directories recursively.
-m Modify ACL. New entries are added to the ACL, and existing entries
are retained.
-x Remove specified ACL entries. Other ACL entries are retained.
--set Fully replace the ACL, discarding all existing entries. The
<acl_spec> must include entries for user, group, and others for
compatibility with permission bits. If the ACL spec contains only
access entries, then the existing default entries are retained. If
the ACL spec contains only default entries, then the existing
access entries are retained. If the ACL spec contains both access
and default entries, then both are replaced.
<acl_spec> Comma separated list of ACL entries.
<path> File or directory to modify.
-setfattr {-n name [-v value] | -x name} <path> :
Sets an extended attribute name and value for a file or directory.
-n name The extended attribute name.
-v value The extended attribute value. There are three different encoding
methods for the value. If the argument is enclosed in double quotes,
then the value is the string inside the quotes. If the argument is
prefixed with 0x or 0X, then it is taken as a hexadecimal number. If
the argument begins with 0s or 0S, then it is taken as a base64
encoding.
-x name Remove the extended attribute.
<path> The file or directory.
-setrep [-R] [-w] <rep> <path> ... :
Set the replication level of a file. If <path> is a directory then the command
recursively changes the replication factor of all files under the directory tree
rooted at <path>. The EC files will be ignored here.
-w It requests that the command waits for the replication to complete. This
can potentially take a very long time.
-R It is accepted for backwards compatibility. It has no effect.
-stat [format] <path> ... :
Print statistics about the file/directory at <path>
in the specified format. Format accepts permissions in
octal (%a) and symbolic (%A), filesize in
bytes (%b), type (%F), group name of owner (%g),
name (%n), block size (%o), replication (%r), user name
of owner (%u), access date (%x, %X).
modification date (%y, %Y).
%x and %y show UTC date as "yyyy-MM-dd HH:mm:ss" and
%X and %Y show milliseconds since January 1, 1970 UTC.
If the format is not specified, %y is used by default.
-tail [-f] [-s <sleep interval>] <file> :
Show the last 1KB of the file.
-f Shows appended data as the file grows.
-s With -f , defines the sleep interval between iterations in milliseconds.
-test -[defswrz] <path> :
Answer various questions about <path>, with result via exit status.
-d return 0 if <path> is a directory.
-e return 0 if <path> exists.
-f return 0 if <path> is a file.
-s return 0 if file <path> is greater than zero bytes in size.
-w return 0 if file <path> exists and write permission is granted.
-r return 0 if file <path> exists and read permission is granted.
-z return 0 if file <path> is zero bytes in size, else return 1.
-text [-ignoreCrc] <src> ... :
Takes a source file and outputs the file in text format.
The allowed formats are zip and TextRecordInputStream and Avro.
-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ... :
Updates the access and modification times of the file specified by the <path> to
the current time. If the file does not exist, then a zero length file is created
at <path> with current time as the timestamp of that <path>.
-a Change only the access time
-m Change only the modification time
-t TIMESTAMP Use specified timestamp (in format yyyyMMddHHmmss) instead of
current time
-c Do not create any files
-touchz <path> ... :
Creates a file of zero length at <path> with current time as the timestamp of
that <path>. An error is returned if the file exists with non-zero length
-truncate [-w] <length> <path> ... :
Truncate all files that match the specified file pattern to the specified
length.
-w Requests that the command wait for block recovery to complete, if
necessary.
-usage [cmd ...] :
Displays the usage for given command or all commands if none is specified.
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
hadoop fs -ls /
Found 4 items drwxrwxrwx - spark hadoop 0 2023-10-17 08:58 /spark-history drwxrwxrwx - hdfs hadoop 0 2023-10-16 16:33 /tmp drwxrwxrwx - hdfs hadoop 0 2023-10-16 16:33 /user drwxr-x--x - hadoop hadoop 0 2023-10-16 16:33 /yarn
hadoop fs -ls /user/
Found 3 items drwxr-x--x - hive hadoop 0 2023-10-16 16:33 /user/hive drwxr-x--x - spark hadoop 0 2023-10-16 16:33 /user/spark drwxr-x--x - yanfei hadoop 0 2023-10-31 19:22 /user/yanfei
hadoop fs -put /home/yanfei/lectures/BDE-L7-hadoop.ipynb .
hadoop fs -ls /user/yanfei
Found 2 items drwx------ - yanfei hadoop 0 2023-10-31 18:12 /user/yanfei/.Trash -rw-r----- 2 yanfei hadoop 69360 2023-10-31 18:12 /user/yanfei/BDE-L7-hadoop.ipynb
hadoop fs -mv BDE-L7-hadoop.ipynb hadoop.ipynb
hadoop fs -ls /user/yanfei
Found 2 items drwx------ - yanfei hadoop 0 2023-10-31 18:12 /user/yanfei/.Trash -rw-r----- 2 yanfei hadoop 69360 2023-10-31 18:12 /user/yanfei/hadoop.ipynb
hdfs fsck /user/yanfei/hadoop.ipynb -files -blocks -locations
Connecting to namenode via http://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:9870/fsck?ugi=yanfei&files=1&blocks=1&locations=1&path=%2Fuser%2Fyanfei%2Fhadoop.ipynb FSCK started by yanfei (auth:SIMPLE) from /192.168.0.4 for path /user/yanfei/hadoop.ipynb at Wed Nov 01 13:03:57 CST 2023 /user/yanfei/hadoop.ipynb 69360 bytes, replicated: replication=2, 1 block(s): OK 0. BP-1046675181-192.168.0.4-1697445166858:blk_1073741841_1018 len=69360 Live_repl=2 [DatanodeInfoWithStorage[192.168.0.3:9866,DS-55541f20-e480-4611-9917-107fc3cd6ca4,DISK], DatanodeInfoWithStorage[192.168.0.2:9866,DS-ce7310bf-9674-4824-96e2-09933c0c2342,DISK]] Status: HEALTHY Number of data-nodes: 2 Number of racks: 1 Total dirs: 0 Total symlinks: 0 Replicated Blocks: Total size: 69360 B Total files: 1 Total blocks (validated): 1 (avg. block size 69360 B) Minimally replicated blocks: 1 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 2 Average block replication: 2.0 Missing blocks: 0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Erasure Coded Block Groups: Total size: 0 B Total files: 0 Total block groups (validated): 0 Minimally erasure-coded block groups: 0 Over-erasure-coded block groups: 0 Under-erasure-coded block groups: 0 Unsatisfactory placement block groups: 0 Average block group size: 0.0 Missing block groups: 0 Corrupt block groups: 0 Missing internal blocks: 0 FSCK ended at Wed Nov 01 13:03:57 CST 2023 in 1 milliseconds The filesystem under path '/user/yanfei/hadoop.ipynb' is HEALTHY
HDFS path¶
/user/yanfei/hadoop.ipynbrefers to the logical path within HDFS that is used to access and manage the file. This logical path is stored in the metadata managed by the NameNode.- The physical data blocks of the file, however, are distributed across the DataNodes.
- When you access a file in HDFS, the logical path is used to retrieve metadata from the NameNode. The metadata includes information about the block locations. Subsequently, the client can then retrieve the actual data blocks from the respective DataNodes.
Hadoop MapReduce¶
- Google released a paper on MapReduce technology in December, 2004. This became the genesis of the Hadoop Processing Model.
- MapReduce is a batch-based, distributed computing framework.
- It allows you to parallelize work over a large amount of raw data.
Traditional way¶
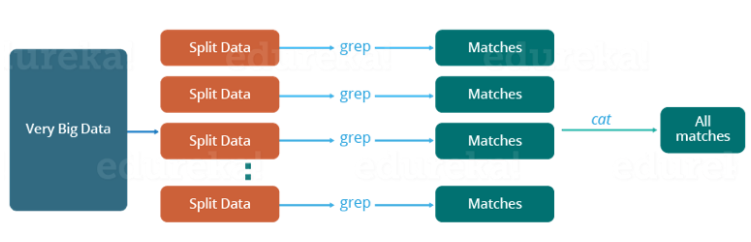
Traditional way¶
- Critical path problem: It is the amount of time taken to finish the job without delaying the next milestone or actual completion date. So, if, any of the machines delays the job, the whole work gets delayed.
- Reliability problem: What if, any of the machines which is working with a part of data fails? The management of this failover becomes a challenge.
- Equal split issue: How will I divide the data into smaller chunks so that each machine gets even part of data to work with. In other words, how to equally divide the data such that no individual machine is overloaded or under utilized.
- Single split may fail: If any of the machine fails to provide the output, I will not be able to calculate the result. So, there should be a mechanism to ensure this fault tolerance capability of the system.
- Aggregation of result: There should be a mechanism to aggregate the result generated by each of the machines to produce the final output.
MapReduce¶
MapReduce gives you the flexibility to write code logic without caring about the design issues of the system.
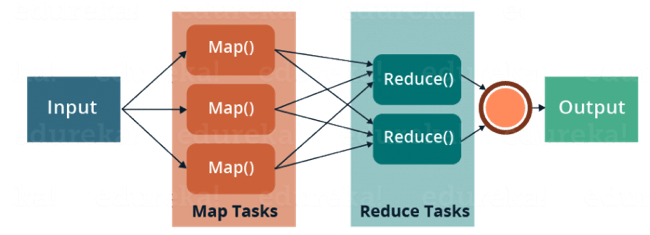
MapReduce¶
MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets in a distributed environment.
- MapReduce consists of two distinct tasks – Map and Reduce.
- As the name MapReduce suggests, reducer phase takes place after mapper phase has been completed.
- So, the first is the map job, where a block of data is read and processed to produce key-value pairs as intermediate outputs.
- The output of a Mapper or map job (key-value pairs) is input to the Reducer.
- The reducer receives the key-value pair from multiple map jobs.
- Then, the reducer aggregates those intermediate data tuples (intermediate key-value pair) into a smaller set of tuples or key-value pairs which is the final output.
MapReduce example - word count¶
The input data consists of text documents, and we want to output the count of each unique word.
Map task¶
- Input:
- Document 1: "Hello world! World of MapReduce."
- Document 2: "MapReduce is powerful. Hello, Hadoop."
- Map Function:
- For each document, the Map function tokenizes the text into words and emits key-value pairs where the key is the word and the value is 1.
- Key-value pairs: ("Hello", 1), ("world", 1), ("World", 1), ("of", 1), ("MapReduce", 1), ("MapReduce", 1), ("is", 1), ("powerful", 1), ("Hello", 1), ("Hadoop", 1).
Shuffle and Sort:¶
- The intermediate key-value pairs are sorted and grouped by key for the shuffle and sort phase.
Reduce task¶
- Input:
- Key: "Hello", Values: [1, 1]
- Key: "Hadoop", Values: [1]
- Key: "MapReduce", Values: [1, 1]
- Key: "World", Values: [1]
- Key: "is", Values: [1]
- Key: "of", Values: [1]
- Key: "powerful", Values: [1]
- Key: "world", Values: [1]
- Reduce Function: for each key, the Reduce function sums up the values, giving the total count of each word, which is ("Hello", 2), ("Hadoop", 1), ("MapReduce", 2), ("World", 1), ("is", 1), ("of", 1), ("powerful", 1), ("world", 1).
MapReduce example - word count¶
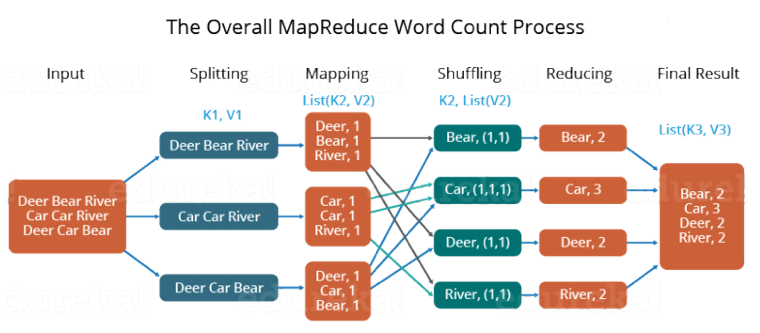
MapReduce example - word count¶
- Divide the input in three splits as shown in the figure. This will distribute the work among all the map nodes.
- Tokenize the words in each of the mapper and give a hardcoded value (1) to each of the tokens or words. The rationale behind giving a hardcoded value equal to 1 is that every word, in itself, will occur once.
- Now, a list of key-value pair will be created where the key is nothing but the individual words and value is one. So, for the first line (Dear Bear River) we have 3 key-value pairs – Dear, 1; Bear, 1; River, 1. The mapping process remains the same on all the nodes.
- After mapper phase, a partition process takes place where sorting and shuffling happens so that all the tuples with the same key are sent to the corresponding reducer.
- After the sorting and shuffling phase, each reducer will have a unique key and a list of values corresponding to that very key. For example, Bear, [1,1]; Car, [1,1,1].., etc.
- Now, each Reducer counts the values which are present in that list of values. As shown in the figure, reducer gets a list of values which is [1,1] for the key Bear. Then, it counts the number of ones in the very list and gives the final output as – Bear, 2.
- Finally, all the output key/value pairs are then collected and written in the output file.
Advantages of MapReduce¶
Parallel Processing: In MapReduce, we are dividing the job among multiple nodes and each node works with a part of the job simultaneously.
Data Locality: Instead of moving data to the processing unit, we are moving processing unit to the data in the MapReduce Framework.
MapReduce example - word count¶
hadoop fs -rm -r /user/yanfei/output
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \
-input /user/yanfei/hadoop.ipynb \
-output /user/yanfei/output \
-mapper "/usr/bin/cat" \
-reducer "/usr/bin/wc"
2023-11-07 13:37:07,241 INFO fs.TrashPolicyDefault: Moved: 'hdfs://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:9000/user/yanfei/output' to trash at: hdfs://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:9000/user/yanfei/.Trash/Current/user/yanfei/output packageJobJar: [/tmp/hadoop-unjar3569133461550345997/] [] /tmp/streamjob1498758464425584878.jar tmpDir=null 2023-11-07 13:37:09,171 INFO client.RMProxy: Connecting to ResourceManager at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:8032 2023-11-07 13:37:09,305 INFO client.AHSProxy: Connecting to Application History server at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:10200 2023-11-07 13:37:09,330 INFO client.RMProxy: Connecting to ResourceManager at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:8032 2023-11-07 13:37:09,330 INFO client.AHSProxy: Connecting to Application History server at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:10200 2023-11-07 13:37:09,451 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /yarn/c-a637e78383e5fe3e/mapred/staging/yanfei/.staging/job_1697504306738_0018 2023-11-07 13:37:09,606 INFO mapred.FileInputFormat: Total input files to process : 1 2023-11-07 13:37:09,643 INFO mapreduce.JobSubmitter: number of splits:16 2023-11-07 13:37:09,715 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697504306738_0018 2023-11-07 13:37:09,716 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2023-11-07 13:37:09,834 INFO conf.Configuration: found resource resource-types.xml at file:/etc/taihao-apps/hadoop-conf/resource-types.xml 2023-11-07 13:37:09,884 INFO impl.YarnClientImpl: Submitted application application_1697504306738_0018 2023-11-07 13:37:09,907 INFO mapreduce.Job: The url to track the job: http://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:20888/proxy/application_1697504306738_0018/ 2023-11-07 13:37:09,908 INFO mapreduce.Job: Running job: job_1697504306738_0018 2023-11-07 13:37:15,968 INFO mapreduce.Job: Job job_1697504306738_0018 running in uber mode : false 2023-11-07 13:37:15,969 INFO mapreduce.Job: map 0% reduce 0% 2023-11-07 13:37:23,020 INFO mapreduce.Job: map 100% reduce 0% 2023-11-07 13:37:28,038 INFO mapreduce.Job: map 100% reduce 100% 2023-11-07 13:37:28,043 INFO mapreduce.Job: Job job_1697504306738_0018 completed successfully 2023-11-07 13:37:28,096 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=24980 FILE: Number of bytes written=5766509 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=133200 HDFS: Number of bytes written=175 HDFS: Number of read operations=83 HDFS: Number of large read operations=0 HDFS: Number of write operations=14 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=16 Launched reduce tasks=7 Data-local map tasks=16 Total time spent by all maps in occupied slots (ms)=4252040 Total time spent by all reduces in occupied slots (ms)=2219341 Total time spent by all map tasks (ms)=81770 Total time spent by all reduce tasks (ms)=21547 Total vcore-milliseconds taken by all map tasks=81770 Total vcore-milliseconds taken by all reduce tasks=21547 Total megabyte-milliseconds taken by all map tasks=136065280 Total megabyte-milliseconds taken by all reduce tasks=71018912 Map-Reduce Framework Map input records=1559 Map output records=1559 Map output bytes=70982 Map output materialized bytes=38341 Input split bytes=2400 Combine input records=0 Combine output records=0 Reduce input groups=788 Reduce shuffle bytes=38341 Reduce input records=1559 Reduce output records=7 Spilled Records=3118 Shuffled Maps =112 Failed Shuffles=0 Merged Map outputs=112 GC time elapsed (ms)=2970 CPU time spent (ms)=27730 Physical memory (bytes) snapshot=12230250496 Virtual memory (bytes) snapshot=91465084928 Total committed heap usage (bytes)=28149022720 Peak Map Physical memory (bytes)=593018880 Peak Map Virtual memory (bytes)=3542560768 Peak Reduce Physical memory (bytes)=423645184 Peak Reduce Virtual memory (bytes)=4992397312 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=130800 File Output Format Counters Bytes Written=175 2023-11-07 13:37:28,096 INFO streaming.StreamJob: Output directory: /user/yanfei/output
hadoop fs -ls /user/yanfei/output
Found 8 items -rw-r----- 2 yanfei hadoop 0 2023-10-31 19:23 /user/yanfei/output/_SUCCESS -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00000 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00001 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00002 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00003 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00004 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00005 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00006
hadoop fs -cat /user/yanfei/output/*
264 1121 9819
271 908 8650
258 1396 12967
163 999 8517
251 1318 11857
174 1197 9691
178 1091 9418
MapReduce example - word count¶
hadoop fs -rm -r /user/yanfei/output
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \
-input /user/yanfei/hadoop.ipynb \
-output /user/yanfei/output \
-mapper "/usr/bin/cat" \
-reducer "/usr/bin/wc" \
-numReduceTasks 1
21/12/03 12:02:57 INFO fs.TrashPolicyDefault: Moved: 'hdfs://emr-header-1.cluster-49012:9000/user/yanfei/output' to trash at: hdfs://emr-header-1.cluster-49012:9000/user/yanfei/.Trash/Current/user/yanfei/output packageJobJar: [/tmp/hadoop-unjar4915498231992068313/] [] /tmp/streamjob2060219075808971674.jar tmpDir=null 21/12/03 12:02:59 INFO client.RMProxy: Connecting to ResourceManager at emr-header-1.cluster-49012/192.168.0.3:8032 21/12/03 12:02:59 INFO client.AHSProxy: Connecting to Application History server at emr-header-1.cluster-49012/192.168.0.3:10200 21/12/03 12:02:59 INFO client.RMProxy: Connecting to ResourceManager at emr-header-1.cluster-49012/192.168.0.3:8032 21/12/03 12:02:59 INFO client.AHSProxy: Connecting to Application History server at emr-header-1.cluster-49012/192.168.0.3:10200 21/12/03 12:02:59 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/yanfei/.staging/job_1637546690590_0004 21/12/03 12:02:59 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 21/12/03 12:03:00 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 97184efe294f64a51a4c5c172cbc22146103da53] 21/12/03 12:03:00 INFO mapred.FileInputFormat: Total input files to process : 1 21/12/03 12:03:00 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO mapreduce.JobSubmitter: number of splits:16 21/12/03 12:03:00 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1637546690590_0004 21/12/03 12:03:00 INFO mapreduce.JobSubmitter: Executing with tokens: [] 21/12/03 12:03:00 INFO conf.Configuration: resource-types.xml not found 21/12/03 12:03:00 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 21/12/03 12:03:00 INFO impl.YarnClientImpl: Submitted application application_1637546690590_0004 21/12/03 12:03:00 INFO mapreduce.Job: The url to track the job: http://emr-header-1.cluster-49012:20888/proxy/application_1637546690590_0004/ 21/12/03 12:03:00 INFO mapreduce.Job: Running job: job_1637546690590_0004 21/12/03 12:03:05 INFO mapreduce.Job: Job job_1637546690590_0004 running in uber mode : false 21/12/03 12:03:05 INFO mapreduce.Job: map 0% reduce 0% 21/12/03 12:03:09 INFO mapreduce.Job: map 13% reduce 0% 21/12/03 12:03:10 INFO mapreduce.Job: map 100% reduce 0% 21/12/03 12:03:12 INFO mapreduce.Job: map 100% reduce 100% 21/12/03 12:03:12 INFO mapreduce.Job: Job job_1637546690590_0004 completed successfully 21/12/03 12:03:12 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=16539 FILE: Number of bytes written=4237750 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=132018 HDFS: Number of bytes written=25 HDFS: Number of read operations=53 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Killed map tasks=1 Launched map tasks=16 Launched reduce tasks=1 Data-local map tasks=16 Total time spent by all maps in occupied slots (ms)=4745661 Total time spent by all reduces in occupied slots (ms)=189727 Total time spent by all map tasks (ms)=41997 Total time spent by all reduce tasks (ms)=1679 Total vcore-milliseconds taken by all map tasks=41997 Total vcore-milliseconds taken by all reduce tasks=1679 Total megabyte-milliseconds taken by all map tasks=151861152 Total megabyte-milliseconds taken by all reduce tasks=6071264 Map-Reduce Framework Map input records=1535 Map output records=1535 Map output bytes=70324 Map output materialized bytes=25405 Input split bytes=1840 Combine input records=0 Combine output records=0 Reduce input groups=799 Reduce shuffle bytes=25405 Reduce input records=1535 Reduce output records=1 Spilled Records=3070 Shuffled Maps =16 Failed Shuffles=0 Merged Map outputs=16 GC time elapsed (ms)=1050 CPU time spent (ms)=11930 Physical memory (bytes) snapshot=8222433280 Virtual memory (bytes) snapshot=85753057280 Total committed heap usage (bytes)=12587630592 Peak Map Physical memory (bytes)=495804416 Peak Map Virtual memory (bytes)=5044715520 Peak Reduce Physical memory (bytes)=303345664 Peak Reduce Virtual memory (bytes)=5058519040 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=130178 File Output Format Counters Bytes Written=25 21/12/03 12:03:12 INFO streaming.StreamJob: Output directory: /user/yanfei/output
hadoop fs -cat /user/yanfei/output/*
21/12/03 12:03:20 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 1535 7774 70273