Modules of Hadoop¶
- Hadoop Distributed File System (HDFS): A reliable, high-bandwidth, low-cost, data storage cluster that facilitates the management of related files across machines.
- Hadoop MapReduce: A high-performance parallel/distributed data-processing implementation of the MapReduce algorithm.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop Common: The common utilities that support the other Hadoop modules.
HDFS¶
- HDFS is the world’s most reliable storage system.
- It is a data service that offers a unique set of capabilities needed when data volumes and velocity are high.
- The service includes a “NameNode” and multiple “data nodes”.
NameNodes¶
- HDFS works by breaking large files into smaller pieces called blocks. The blocks are stored on data nodes, and it is the responsibility of the NameNode to know what blocks on which data nodes make up the complete file.
- Data nodes are not very smart, but the NameNode is. The data nodes constantly ask the NameNode whether there is anything for them to do. This continuous behavior also tells the NameNode what data nodes are out there and how busy they are.
DataNodes¶
- Within the HDFS cluster, data blocks are replicated across multiple data nodes and access is managed by the NameNode.
Under the covers of HDFS¶
- Big data brings the big challenges of volume, velocity, and variety.
- HDFS addresses these challenges by breaking files into a related collection of smaller blocks. These blocks are distributed among the data nodes in the HDFS cluster and are managed by the NameNode.
- Block sizes are configurable and are usually 128 megabytes (MB) or 256MB, meaning that a 1GB file consumes eight 128MB blocks for its basic storage needs.
- HDFS is resilient, so these blocks are replicated throughout the cluster in case of a server failure. How does HDFS keep track of all these pieces? The short answer is file system metadata.
- HDFS metadata is stored in the NameNode, and while the cluster is operating, all the metadata is loaded into the physical memory of the NameNode server.
- Data nodes are very simplistic. They are servers that contain the blocks for a given set of files.
Data storage of HDFS¶
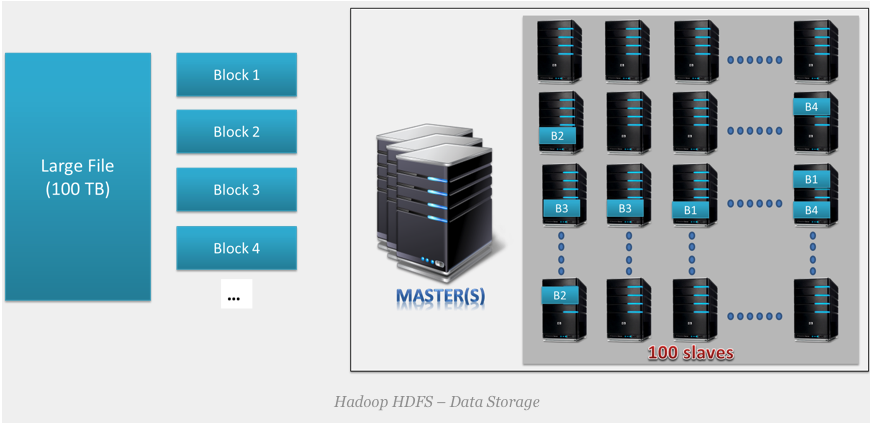
Data storage of HDFS¶
- Multiple copies of each block are stored across the cluster on different nodes.
- This is a replication of data. By default, HDFS replication factor is 3.
- It provides fault tolerance, reliability, and high availability.
- A Large file is split into $n$ number of small blocks. These blocks are stored at different nodes in the cluster in a distributed manner. Each block is replicated and stored across different nodes in the cluster.
In [6]:
hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
HDFS commands¶
hadoop fshadoop fs -helphadoop fs -ls /hadoop fs -ls /user/yanfeihadoop fs -mv LICENSE license.txthadoop fs -mkdir yourNAME
In [8]:
hadoop fs -ls /
Found 4 items drwxrwxrwx - spark hadoop 0 2023-10-17 08:58 /spark-history drwxrwxrwx - hdfs hadoop 0 2023-10-16 16:33 /tmp drwxrwxrwx - hdfs hadoop 0 2023-10-16 16:33 /user drwxr-x--x - hadoop hadoop 0 2023-10-16 16:33 /yarn
In [4]:
hadoop fs -ls /user/
Found 3 items drwxr-x--x - hive hadoop 0 2023-10-16 16:33 /user/hive drwxr-x--x - spark hadoop 0 2023-10-16 16:33 /user/spark drwxr-x--x - yanfei hadoop 0 2023-10-31 19:22 /user/yanfei
In [12]:
hadoop fs -mkdir /user/yanfei
In [13]:
hadoop fs -ls /user
Found 5 items drwxr-x--x - hive hadoop 0 2025-02-24 11:40 /user/hive drwxr-x--x - root hadoop 0 2025-02-24 18:08 /user/root drwxr-x--x - spark hadoop 0 2025-02-24 11:40 /user/spark drwxr-x--x - teacher hadoop 0 2025-02-24 22:06 /user/teacher drwxr-x--x - yanfei hadoop 0 2025-03-03 23:14 /user/yanfei
In [14]:
hadoop fs -put /home/yanfei/lectures/BDE-hadoop.ipynb .
In [15]:
hadoop fs -ls /user/yanfei
Found 1 items -rw-r----- 2 yanfei hadoop 46055 2025-03-03 23:14 /user/yanfei/BDE-hadoop.ipynb
In [16]:
hadoop fs -mv BDE-hadoop.ipynb hadoop.ipynb
In [17]:
hadoop fs -ls /user/yanfei
Found 1 items -rw-r----- 2 yanfei hadoop 46055 2025-03-03 23:14 /user/yanfei/hadoop.ipynb
In [18]:
hdfs fsck /user/yanfei/hadoop.ipynb -files -blocks -locations
Connecting to namenode via http://master-1-1.c-90a0b99c49464ed0.cn-hangzhou.emr.aliyuncs.com:9870/fsck?ugi=yanfei&files=1&blocks=1&locations=1&path=%2Fuser%2Fyanfei%2Fhadoop.ipynb FSCK started by yanfei (auth:SIMPLE) from /10.0.0.123 for path /user/yanfei/hadoop.ipynb at Mon Mar 03 23:15:05 CST 2025 /user/yanfei/hadoop.ipynb 46055 bytes, replicated: replication=2, 1 block(s): OK 0. BP-465277494-10.0.0.123-1740368374401:blk_1073741842_1018 len=46055 Live_repl=2 [DatanodeInfoWithStorage[10.0.0.122:9866,DS-c9551a7c-917a-4aba-b747-408a0749cf43,DISK], DatanodeInfoWithStorage[10.0.0.124:9866,DS-d24ad1ec-6b54-4150-b31c-88d0f39083bb,DISK]] Status: HEALTHY Number of data-nodes: 2 Number of racks: 1 Total dirs: 0 Total symlinks: 0 Replicated Blocks: Total size: 46055 B Total files: 1 Total blocks (validated): 1 (avg. block size 46055 B) Minimally replicated blocks: 1 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 2 Average block replication: 2.0 Missing blocks: 0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Erasure Coded Block Groups: Total size: 0 B Total files: 0 Total block groups (validated): 0 Minimally erasure-coded block groups: 0 Over-erasure-coded block groups: 0 Under-erasure-coded block groups: 0 Unsatisfactory placement block groups: 0 Average block group size: 0.0 Missing block groups: 0 Corrupt block groups: 0 Missing internal blocks: 0 FSCK ended at Mon Mar 03 23:15:05 CST 2025 in 4 milliseconds The filesystem under path '/user/yanfei/hadoop.ipynb' is HEALTHY
HDFS path¶
/user/yanfei/hadoop.ipynbrefers to the logical path within HDFS that is used to access and manage the file. This logical path is stored in the metadata managed by the NameNode.- The physical data blocks of the file, however, are distributed across the DataNodes.
- When you access a file in HDFS, the logical path is used to retrieve metadata from the NameNode. The metadata includes information about the block locations. Subsequently, the client can then retrieve the actual data blocks from the respective DataNodes.