Hadoop MapReduce¶
- Google released a paper on MapReduce technology in December, 2004. This became the genesis of the Hadoop Processing Model.
- MapReduce is a batch-based, distributed computing framework.
- It allows you to parallelize work over a large amount of raw data.
Traditional way¶
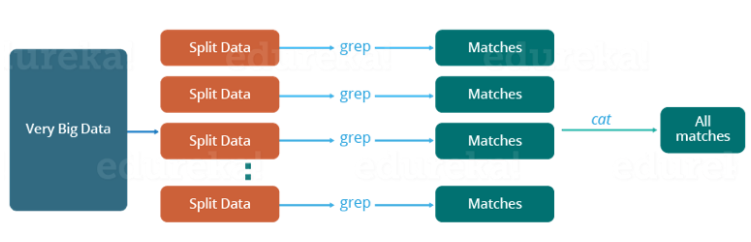
Traditional way¶
- Critical path problem: It is the amount of time taken to finish the job without delaying the next milestone or actual completion date. So, if, any of the machines delays the job, the whole work gets delayed.
- Reliability problem: What if, any of the machines which is working with a part of data fails? The management of this failover becomes a challenge.
- Equal split issue: How will I divide the data into smaller chunks so that each machine gets even part of data to work with. In other words, how to equally divide the data such that no individual machine is overloaded or under utilized.
- Single split may fail: If any of the machine fails to provide the output, I will not be able to calculate the result. So, there should be a mechanism to ensure this fault tolerance capability of the system.
- Aggregation of result: There should be a mechanism to aggregate the result generated by each of the machines to produce the final output.
MapReduce¶
MapReduce gives you the flexibility to write code logic without caring about the design issues of the system.
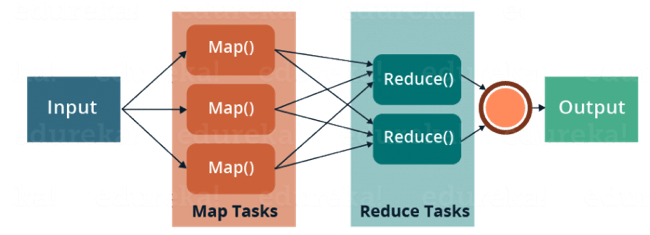
MapReduce¶
MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets in a distributed environment.
- MapReduce consists of two distinct tasks – Map and Reduce.
- As the name MapReduce suggests, reducer phase takes place after mapper phase has been completed.
- So, the first is the map job, where a block of data is read and processed to produce key-value pairs as intermediate outputs.
- The output of a Mapper or map job (key-value pairs) is input to the Reducer.
- The reducer receives the key-value pair from multiple map jobs.
- Then, the reducer aggregates those intermediate data tuples (intermediate key-value pair) into a smaller set of tuples or key-value pairs which is the final output.
MapReduce example - word count¶
The input data consists of text documents, and we want to output the count of each unique word.
Map task¶
- Input:
- Document 1: "Hello world! World of MapReduce."
- Document 2: "MapReduce is powerful. Hello, Hadoop."
- Map Function:
- For each document, the Map function tokenizes the text into words and emits key-value pairs where the key is the word and the value is 1.
- Key-value pairs: ("Hello", 1), ("world", 1), ("World", 1), ("of", 1), ("MapReduce", 1), ("MapReduce", 1), ("is", 1), ("powerful", 1), ("Hello", 1), ("Hadoop", 1).
Shuffle and Sort:¶
- The intermediate key-value pairs are sorted and grouped by key for the shuffle and sort phase.
Reduce task¶
- Input:
- Key: "Hello", Values: [1, 1]
- Key: "Hadoop", Values: [1]
- Key: "MapReduce", Values: [1, 1]
- Key: "World", Values: [1]
- Key: "is", Values: [1]
- Key: "of", Values: [1]
- Key: "powerful", Values: [1]
- Key: "world", Values: [1]
- Reduce Function: for each key, the Reduce function sums up the values, giving the total count of each word, which is ("Hello", 2), ("Hadoop", 1), ("MapReduce", 2), ("World", 1), ("is", 1), ("of", 1), ("powerful", 1), ("world", 1).
MapReduce example - word count¶
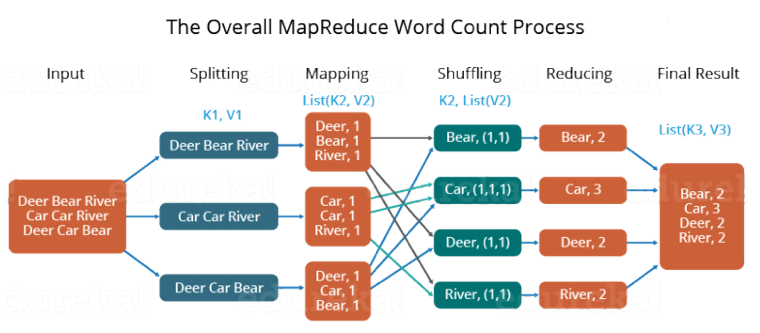
MapReduce example - word count¶
- Divide the input in three splits as shown in the figure. This will distribute the work among all the map nodes.
- Tokenize the words in each of the mapper and give a hardcoded value (1) to each of the tokens or words. The rationale behind giving a hardcoded value equal to 1 is that every word, in itself, will occur once.
- Now, a list of key-value pair will be created where the key is nothing but the individual words and value is one. So, for the first line (Dear Bear River) we have 3 key-value pairs – Dear, 1; Bear, 1; River, 1. The mapping process remains the same on all the nodes.
- After mapper phase, a partition process takes place where sorting and shuffling happens so that all the tuples with the same key are sent to the corresponding reducer.
- After the sorting and shuffling phase, each reducer will have a unique key and a list of values corresponding to that very key. For example, Bear, [1,1]; Car, [1,1,1].., etc.
- Now, each Reducer counts the values which are present in that list of values. As shown in the figure, reducer gets a list of values which is [1,1] for the key Bear. Then, it counts the number of ones in the very list and gives the final output as – Bear, 2.
- Finally, all the output key/value pairs are then collected and written in the output file.
Advantages of MapReduce¶
Parallel Processing: In MapReduce, we are dividing the job among multiple nodes and each node works with a part of the job simultaneously.
Data Locality: Instead of moving data to the processing unit, we are moving processing unit to the data in the MapReduce Framework.
MapReduce example - word count¶
In [1]:
hadoop fs -rm -r /user/yanfei/output
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \
-input /user/yanfei/hadoop.ipynb \
-output /user/yanfei/output \
-mapper "/usr/bin/cat" \
-reducer "/usr/bin/wc"
2023-11-07 13:37:07,241 INFO fs.TrashPolicyDefault: Moved: 'hdfs://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:9000/user/yanfei/output' to trash at: hdfs://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:9000/user/yanfei/.Trash/Current/user/yanfei/output packageJobJar: [/tmp/hadoop-unjar3569133461550345997/] [] /tmp/streamjob1498758464425584878.jar tmpDir=null 2023-11-07 13:37:09,171 INFO client.RMProxy: Connecting to ResourceManager at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:8032 2023-11-07 13:37:09,305 INFO client.AHSProxy: Connecting to Application History server at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:10200 2023-11-07 13:37:09,330 INFO client.RMProxy: Connecting to ResourceManager at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:8032 2023-11-07 13:37:09,330 INFO client.AHSProxy: Connecting to Application History server at master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com/192.168.0.4:10200 2023-11-07 13:37:09,451 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /yarn/c-a637e78383e5fe3e/mapred/staging/yanfei/.staging/job_1697504306738_0018 2023-11-07 13:37:09,606 INFO mapred.FileInputFormat: Total input files to process : 1 2023-11-07 13:37:09,643 INFO mapreduce.JobSubmitter: number of splits:16 2023-11-07 13:37:09,715 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697504306738_0018 2023-11-07 13:37:09,716 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2023-11-07 13:37:09,834 INFO conf.Configuration: found resource resource-types.xml at file:/etc/taihao-apps/hadoop-conf/resource-types.xml 2023-11-07 13:37:09,884 INFO impl.YarnClientImpl: Submitted application application_1697504306738_0018 2023-11-07 13:37:09,907 INFO mapreduce.Job: The url to track the job: http://master-1-1.c-a637e78383e5fe3e.cn-zhangjiakou.emr.aliyuncs.com:20888/proxy/application_1697504306738_0018/ 2023-11-07 13:37:09,908 INFO mapreduce.Job: Running job: job_1697504306738_0018 2023-11-07 13:37:15,968 INFO mapreduce.Job: Job job_1697504306738_0018 running in uber mode : false 2023-11-07 13:37:15,969 INFO mapreduce.Job: map 0% reduce 0% 2023-11-07 13:37:23,020 INFO mapreduce.Job: map 100% reduce 0% 2023-11-07 13:37:28,038 INFO mapreduce.Job: map 100% reduce 100% 2023-11-07 13:37:28,043 INFO mapreduce.Job: Job job_1697504306738_0018 completed successfully 2023-11-07 13:37:28,096 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=24980 FILE: Number of bytes written=5766509 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=133200 HDFS: Number of bytes written=175 HDFS: Number of read operations=83 HDFS: Number of large read operations=0 HDFS: Number of write operations=14 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=16 Launched reduce tasks=7 Data-local map tasks=16 Total time spent by all maps in occupied slots (ms)=4252040 Total time spent by all reduces in occupied slots (ms)=2219341 Total time spent by all map tasks (ms)=81770 Total time spent by all reduce tasks (ms)=21547 Total vcore-milliseconds taken by all map tasks=81770 Total vcore-milliseconds taken by all reduce tasks=21547 Total megabyte-milliseconds taken by all map tasks=136065280 Total megabyte-milliseconds taken by all reduce tasks=71018912 Map-Reduce Framework Map input records=1559 Map output records=1559 Map output bytes=70982 Map output materialized bytes=38341 Input split bytes=2400 Combine input records=0 Combine output records=0 Reduce input groups=788 Reduce shuffle bytes=38341 Reduce input records=1559 Reduce output records=7 Spilled Records=3118 Shuffled Maps =112 Failed Shuffles=0 Merged Map outputs=112 GC time elapsed (ms)=2970 CPU time spent (ms)=27730 Physical memory (bytes) snapshot=12230250496 Virtual memory (bytes) snapshot=91465084928 Total committed heap usage (bytes)=28149022720 Peak Map Physical memory (bytes)=593018880 Peak Map Virtual memory (bytes)=3542560768 Peak Reduce Physical memory (bytes)=423645184 Peak Reduce Virtual memory (bytes)=4992397312 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=130800 File Output Format Counters Bytes Written=175 2023-11-07 13:37:28,096 INFO streaming.StreamJob: Output directory: /user/yanfei/output
In [3]:
hadoop fs -ls /user/yanfei/output
Found 8 items -rw-r----- 2 yanfei hadoop 0 2023-10-31 19:23 /user/yanfei/output/_SUCCESS -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00000 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00001 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00002 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00003 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00004 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00005 -rw-r----- 2 yanfei hadoop 25 2023-10-31 19:23 /user/yanfei/output/part-00006
In [2]:
hadoop fs -cat /user/yanfei/output/*
264 1121 9819
271 908 8650
258 1396 12967
163 999 8517
251 1318 11857
174 1197 9691
178 1091 9418
MapReduce example - word count¶
In [20]:
hadoop fs -rm -r /user/yanfei/output
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \
-input /user/yanfei/hadoop.ipynb \
-output /user/yanfei/output \
-mapper "/usr/bin/cat" \
-reducer "/usr/bin/wc" \
-numReduceTasks 1
21/12/03 12:02:57 INFO fs.TrashPolicyDefault: Moved: 'hdfs://emr-header-1.cluster-49012:9000/user/yanfei/output' to trash at: hdfs://emr-header-1.cluster-49012:9000/user/yanfei/.Trash/Current/user/yanfei/output packageJobJar: [/tmp/hadoop-unjar4915498231992068313/] [] /tmp/streamjob2060219075808971674.jar tmpDir=null 21/12/03 12:02:59 INFO client.RMProxy: Connecting to ResourceManager at emr-header-1.cluster-49012/192.168.0.3:8032 21/12/03 12:02:59 INFO client.AHSProxy: Connecting to Application History server at emr-header-1.cluster-49012/192.168.0.3:10200 21/12/03 12:02:59 INFO client.RMProxy: Connecting to ResourceManager at emr-header-1.cluster-49012/192.168.0.3:8032 21/12/03 12:02:59 INFO client.AHSProxy: Connecting to Application History server at emr-header-1.cluster-49012/192.168.0.3:10200 21/12/03 12:02:59 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/yanfei/.staging/job_1637546690590_0004 21/12/03 12:02:59 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 21/12/03 12:03:00 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 97184efe294f64a51a4c5c172cbc22146103da53] 21/12/03 12:03:00 INFO mapred.FileInputFormat: Total input files to process : 1 21/12/03 12:03:00 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO mapreduce.JobSubmitter: number of splits:16 21/12/03 12:03:00 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 21/12/03 12:03:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1637546690590_0004 21/12/03 12:03:00 INFO mapreduce.JobSubmitter: Executing with tokens: [] 21/12/03 12:03:00 INFO conf.Configuration: resource-types.xml not found 21/12/03 12:03:00 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 21/12/03 12:03:00 INFO impl.YarnClientImpl: Submitted application application_1637546690590_0004 21/12/03 12:03:00 INFO mapreduce.Job: The url to track the job: http://emr-header-1.cluster-49012:20888/proxy/application_1637546690590_0004/ 21/12/03 12:03:00 INFO mapreduce.Job: Running job: job_1637546690590_0004 21/12/03 12:03:05 INFO mapreduce.Job: Job job_1637546690590_0004 running in uber mode : false 21/12/03 12:03:05 INFO mapreduce.Job: map 0% reduce 0% 21/12/03 12:03:09 INFO mapreduce.Job: map 13% reduce 0% 21/12/03 12:03:10 INFO mapreduce.Job: map 100% reduce 0% 21/12/03 12:03:12 INFO mapreduce.Job: map 100% reduce 100% 21/12/03 12:03:12 INFO mapreduce.Job: Job job_1637546690590_0004 completed successfully 21/12/03 12:03:12 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=16539 FILE: Number of bytes written=4237750 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=132018 HDFS: Number of bytes written=25 HDFS: Number of read operations=53 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Killed map tasks=1 Launched map tasks=16 Launched reduce tasks=1 Data-local map tasks=16 Total time spent by all maps in occupied slots (ms)=4745661 Total time spent by all reduces in occupied slots (ms)=189727 Total time spent by all map tasks (ms)=41997 Total time spent by all reduce tasks (ms)=1679 Total vcore-milliseconds taken by all map tasks=41997 Total vcore-milliseconds taken by all reduce tasks=1679 Total megabyte-milliseconds taken by all map tasks=151861152 Total megabyte-milliseconds taken by all reduce tasks=6071264 Map-Reduce Framework Map input records=1535 Map output records=1535 Map output bytes=70324 Map output materialized bytes=25405 Input split bytes=1840 Combine input records=0 Combine output records=0 Reduce input groups=799 Reduce shuffle bytes=25405 Reduce input records=1535 Reduce output records=1 Spilled Records=3070 Shuffled Maps =16 Failed Shuffles=0 Merged Map outputs=16 GC time elapsed (ms)=1050 CPU time spent (ms)=11930 Physical memory (bytes) snapshot=8222433280 Virtual memory (bytes) snapshot=85753057280 Total committed heap usage (bytes)=12587630592 Peak Map Physical memory (bytes)=495804416 Peak Map Virtual memory (bytes)=5044715520 Peak Reduce Physical memory (bytes)=303345664 Peak Reduce Virtual memory (bytes)=5058519040 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=130178 File Output Format Counters Bytes Written=25 21/12/03 12:03:12 INFO streaming.StreamJob: Output directory: /user/yanfei/output
In [21]:
hadoop fs -cat /user/yanfei/output/*
21/12/03 12:03:20 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 1535 7774 70273