Spark¶
Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
- In 2009, Apache Spark began as a research project at UC Berkeley’s AMPLab to improve on MapReduce.
- The most widely-used engine for scalable computing: Thousands of companies, including 80% of the Fortune 500, use Apache Spark. Amost 2,000 contributors to the open source project from industry and academia.
Key features¶
Batch/streaming data: Unify the processing of your data in batches and real-time streaming, using your preferred language: Python, SQL, Scala, Java or R.
SQL analytics: Execute fast, distributed ANSI SQL queries for dashboarding and ad-hoc reporting. Runs faster than most data warehouses.
Data science at scale: Perform Exploratory Data Analysis (EDA) on petabyte-scale data without having to resort to downsampling.
Machine learning: Train machine learning algorithms on a laptop and use the same code to scale to fault-tolerant clusters of thousands of machines.
What is Spark¶
- Spark is a lightning-fast cluster computing technology, designed for fast computation.
- It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing.
- The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application. Spark also loaded data in-memory, making operations much faster than Hadoop’s on-disk storage.
- Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming.
Spark¶
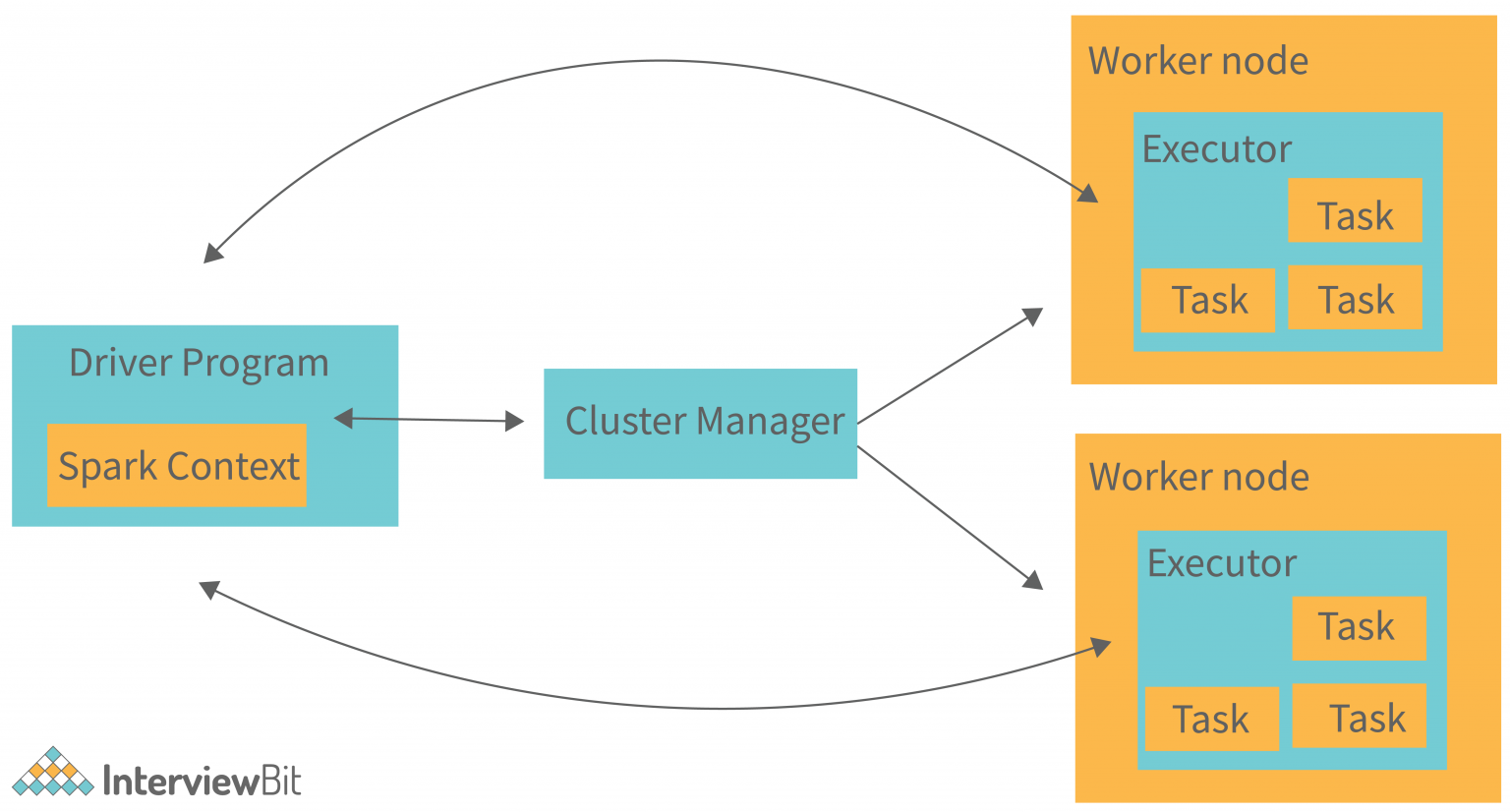
Why Spark¶
Speed¶
- Run workloads 100x faster.
- Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
- One of the earliest results showed that running logistic regression allowed Spark to run 10 times faster than Hadoop by making use of in-memory datasets.
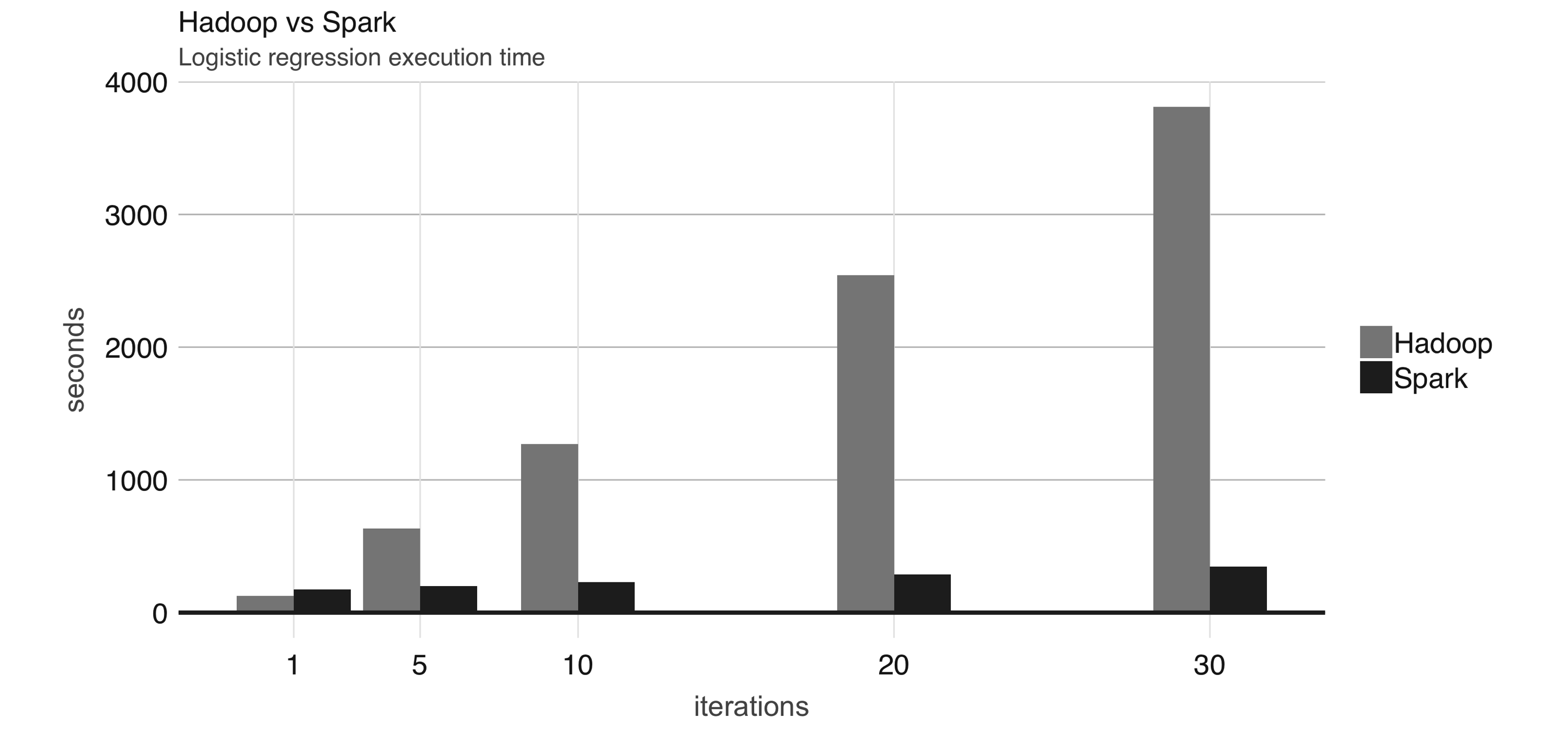
- To give you a sense of how much faster and efficient Spark is, it takes 72 minutes and 2,100 computers to sort 100 terabytes of data using Hadoop, but only 23 minutes and 206 computers using Spark.
Ease of Use¶
APIs in Java, Scala, Python, R, and SQL.
Spark is also easier to use than Hadoop.
Spark supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Spark is much faster.
Spark installation on a single node (PLEASE DO IT) requires no configuration.
A single, unified API that scales from “small data” on a laptop to “big data” on a cluster.
Runs Everywhere¶
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on AWS (Amazon EMR), Google Cloud Dataproc, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
Libraries of Spark¶
- SQL and DataFrames is a module for working with structured data. Spark SQL lets you query structured data inside Spark programs. DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC.
- Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
- MLlib fits into Spark's APIs and interoperates with NumPy in Python (as of Spark 0.9) and R libraries (as of Spark 1.5). You can use any Hadoop data source (e.g. HDFS, HBase, or local files), making it easy to plug into Hadoop workflows. MLlib contains many algorithms and utilities: classification, Clustering, Recommendation, Text mining, etc.
- GraphX a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
Spark RDD¶
- Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark.
- It is an immutable distributed collection of objects.
- Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster.
- RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
- There are two ways to create RDDs − parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
Launching Applications with spark-submit¶
Once a user application is bundled, it can be launched using the bin/spark-submit script. This script takes care of setting up the classpath with Spark and its dependencies, and can support different cluster managers and deploy modes that Spark supports:
spark-submit \ --class <main-class> \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments]
Run Python application on a YARN cluster¶
PYSPARK_PYTHON=python3.11 spark-submit \
--master yarn \
--executor-memory 20G \
--num-executors 50 \
$SPARK_HOME/examples/src/main/python/pi.py \
1000Run Spark via Pyspark shell¶
It is also possible to launch the PySpark shell. Set
PYSPARK_PYTHONvariable to select the approperate Python when runningpysparkcommand:PYSPARK_PYTHON=python3.11 pyspark
Run spark interactively within Python¶
You could use spark as a Python's module, but
PySparkisn't onsys.pathby default.That doesn't mean it can't be used as a regular library.
You can address this by either symlinking pyspark into your site-packages, or adding pyspark to sys.path at runtime. findspark does the latter.
To initialize PySpark, just call it within Python
import findspark
findspark.init('/opt/apps/SPARK3/spark-current')
# Then you could import the `pyspark` module
import pyspark
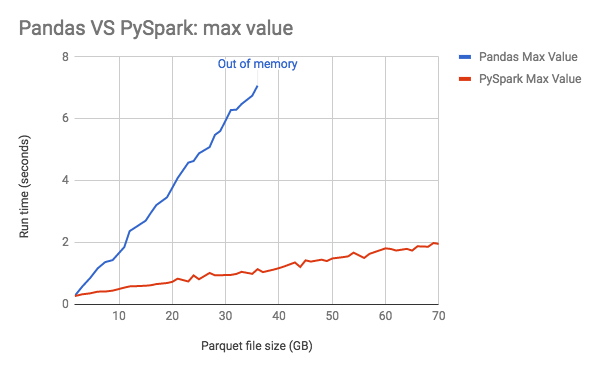
Computational power of spark¶
Let's compute the average of 1:10^10.
For 10^10 rows with 64-bit integers, you'd need around 80 GB of memory.
Compare pandas and pyspark in computational time and memory usage.
Using pandas¶
import pandas as pd
import time
# Create a large dataset with pandas
n = 10**9 # Example size of dataset
data = pd.DataFrame({'numbers': range(1, n+1)})
# Start timer
start_time = time.time()
# Perform the computation (sum of numbers)
avg_result = data['numbers'].mean()
# End timer
end_time = time.time()
# Print time taken
print(f"Computation time without Spark: {end_time - start_time} seconds")
print(avg_result)
Computation time without Spark: 0.8456501960754395 seconds 500000000.5
Using pyspark¶
from pyspark.sql import SparkSession
import time
# Initialize Spark session
spark = SparkSession.builder \
.master("local[16]") \
.appName("Spark Computation") \
.getOrCreate()
# Create a large dataset with Spark
n = 10**10 # Example size of dataset
data = spark.range(1, n+1).toDF("numbers")
# Start timer
start_time = time.time()
# Perform the computation (sum of numbers)
avg_result = data.groupBy().avg("numbers").collect()[0][0]
# End timer
end_time = time.time()
# Print time taken
print(f"Computation time with Spark: {end_time - start_time} seconds")
print(avg_result)
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 25/03/31 18:14:14 WARN [Thread-6] Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041. [Stage 0:> (0 + 16) / 16]
Computation time with Spark: 2.633451223373413 seconds 5000000000.009091
Spark Configuration Parameters¶
| Parameter | Description | Example Value |
|---|---|---|
spark.app.name |
Name of the Spark application | "MyApp" |
spark.master |
Master URL for the cluster | "local[*]" |
spark.executor.memory |
Memory per executor | "4g" |
spark.driver.memory |
Memory for the driver | "2g" |
spark.executor.cores |
Number of cores per executor | "4" |
spark.num.executors |
Number of executors | "10" |
spark.sql.shuffle.partitions |
Number of partitions for shuffle operations | "200" |
spark.default.parallelism |
Default number of partitions for RDDs | "36" |
spark = SparkSession.builder \
.master("yarn") \
.appName("Spark Computation") \
.spark.num.executors('10') \
.spark.executor.cores('4') \
.spark.executor.memory('4g')
.getOrCreate()
- Start 10 executors.
- Use 4 cores and 4G memory for each executor.
Our case¶
- 2 workers.
- 8 cores, 32G memory for each worker.
Per Executor Settings¶
| Parameter | Value | Description |
|---|---|---|
spark.executor.cores |
4 | Number of CPU cores per executor |
spark.executor.memory |
14g | Memory allocated to each executor |
| JVM Overhead (estimated) | ~1.4g | Extra memory Spark reserves (approx. 10%) |
Per Worker Node Resource Usage¶
| Item | Value | Description |
|---|---|---|
| Executors | 2 | Executors per worker |
| Total CPU usage | 2 × 4 = 8 ✅ | All CPU cores are fully utilized |
| Total Memory usage | 2 × 14g = 28g ✅ | Most memory is used, leaving headroom |
| Reserved Memory | ~4g | For system and JVM overhead |
Cluster-Wide Resource Usage¶
| Item | Value |
|---|---|
| Total Executors | 4 |
| Total CPU usage | 4 × 4 = 16 cores ✅ |
| Total Memory (executors) | 4 × 14g = 56g ✅ |
| Total JVM Overhead | ~4 × 1.4g = 5.6g |
| Total Memory (including overhead) | ≈ 62g ✅ |
The best config:¶
spark = SparkSession.builder \
.appName("OptimizedApp") \
.config("spark.executor.cores", "4") \
.config("spark.executor.memory", "14g") \
.config("spark.num.executors", "4") \
.getOrCreate()
spark.stop()
Lab¶
- Install spark on your laptop.
- Run an example comparing computation time of using spark v.s. not using spark.