Big Data Essentials¶
L10: Introduction to Spark¶
Yanfei Kang
yanfeikang@buaa.edu.cn
School of Economics and Management
Beihang University
http://yanfei.site
Spark¶
Apache Spark is a unified analytics engine for large-scale data processing.
- In 2009, Apache Spark began as a research project at UC Berkeley’s AMPLab to improve on MapReduce.
- Specifically, Spark provided a richer set of verbs beyond MapReduce to facilitate optimizing code running in multiple machines.
What is Spark¶
- Spark is a lightning-fast cluster computing technology, designed for fast computation.
- It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing.
- The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application. Spark also loaded data in-memory, making operations much faster than Hadoop’s on-disk storage.
- Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming.
Why Spark¶
Speed¶
- Run workloads 100x faster.
- Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
- One of the earliest results showed that running logistic regression allowed Spark to run 10 times faster than Hadoop by making use of in-memory datasets.
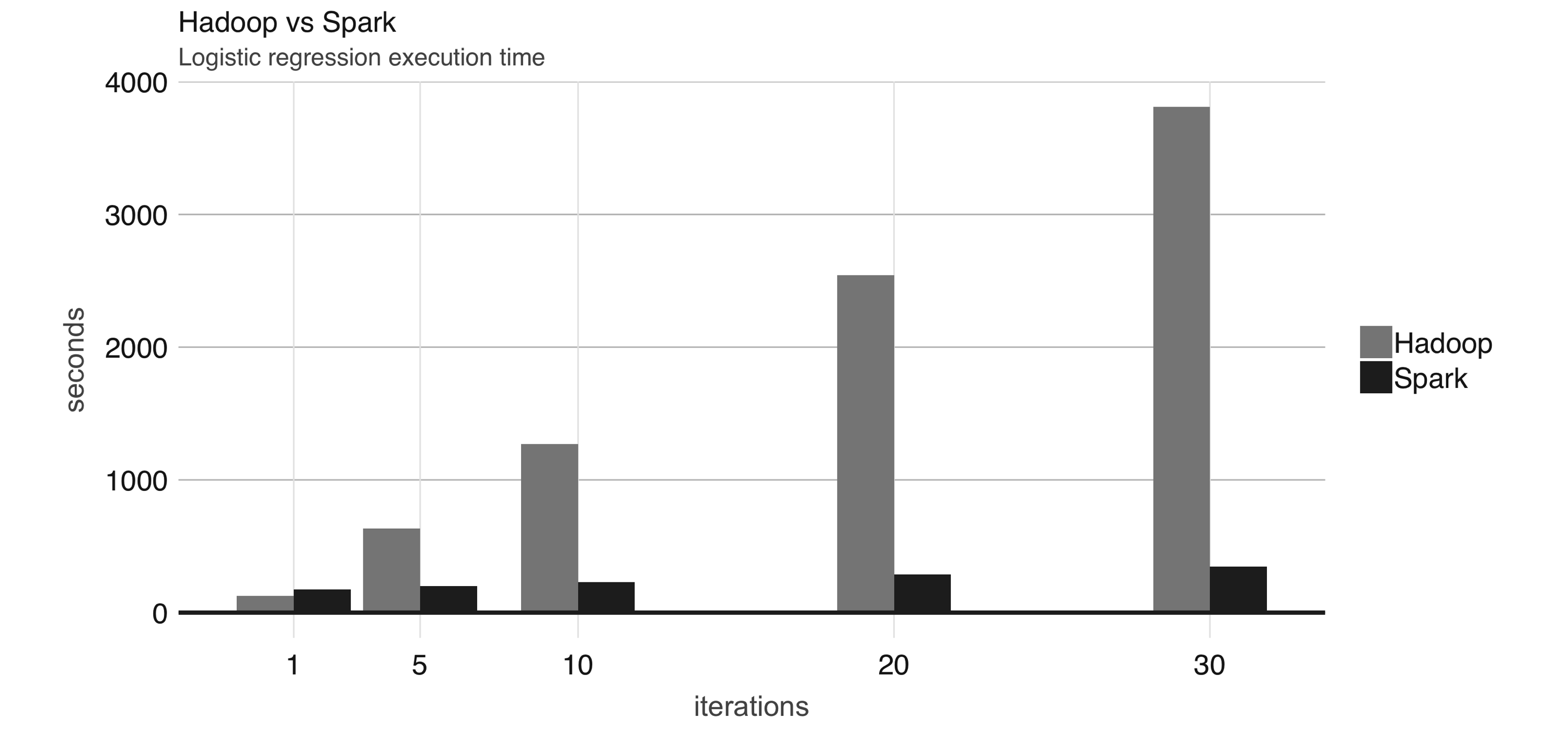
- To give you a sense of how much faster and efficient Spark is, it takes 72 minutes and 2,100 computers to sort 100 terabytes of data using Hadoop, but only 23 minutes and 206 computers using Spark.
Ease of Use¶
Write applications quickly in Java, Scala, Python, R, and SQL.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
Spark is also easier to use than Hadoop; for instance, the word-counting MapReduce example takes about 50 lines of code in Hadoop, but it takes only 2 lines of code in Spark. As you can see, Spark is much faster, more efficient, and easier to use than Hadoop.
Generality¶
Combine SQL, streaming, and complex analytics.
Advanced Analytics: Spark not only supports ‘Map’ and ‘reduce’. It also supports SQL queries, Streaming data, Machine learning (ML), and Graph algorithms.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere¶
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.

Spark architecture¶
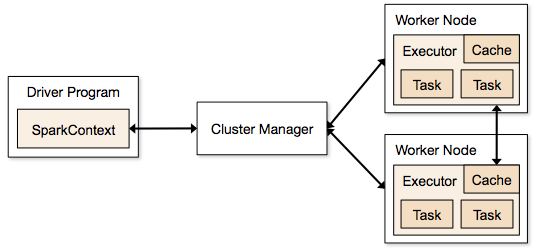
Components of Spark¶
- DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R.
- Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
- MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It is, according to benchmarks, done by the MLlib developers against the Alternating Least Squares (ALS) implementations. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout (before Mahout gained a Spark interface).
- GraphX a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
Spark RDD¶
- Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark.
- It is an immutable distributed collection of objects.
- Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster.
- RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
- There are two ways to create RDDs − parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
Data Sharing is Slow in MapReduce¶
- MapReduce is widely adopted for processing and generating large datasets with a parallel, distributed algorithm on a cluster. It allows users to write parallel computations, using a set of high-level operators, without having to worry about work distribution and fault tolerance.
- Unfortunately, in most current frameworks, the only way to reuse data between computations (Ex − between two MapReduce jobs) is to write it to an external stable storage system (Ex − HDFS). Although this framework provides numerous abstractions for accessing a cluster’s computational resources, users still want more.
- Both Iterative and Interactive applications require faster data sharing across parallel jobs. Data sharing is slow in MapReduce due to replication, serialization, and disk IO. Regarding storage system, most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations.
Data Sharing using Spark RDD¶
- Data sharing is slow in MapReduce due to replication, serialization, and disk IO. Most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations.
- Recognizing this problem, researchers developed a specialized framework called Apache Spark. The key idea of spark is Resilient Distributed Datasets (RDD); it supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk.
How to run spark¶
Spark batch:
spark-submit <SparkApp.py>SparkR:
sparkRPySpark:
pysparkSpark-shell:
spark-shell
Launching Applications with spark-submit¶
- Once a user application is bundled, it can be launched using the bin/spark-submit script. This script takes care of setting up the classpath with Spark and its dependencies, and can support different cluster managers and deploy modes that Spark supports:
spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]Run Python application on a YARN cluster¶
PYSPARK_PYTHON=python3.6 spark-submit \
--master yarn \
--executor-memory 20G \
--num-executors 50 \
examples/src/main/python/pi.py \
1000Run Spark via R¶
Spark also provides an experimental R API since 1.4 (only DataFrames APIs included).
To run Spark interactively in a R interpreter, use
sparkRExample applications are also provided in R. For example,
spark-submit examples/src/main/r/dataframe.R
Run Spark via Pyspark¶
It is also possible to launch the PySpark shell. Set
PYSPARK_PYTHONvariable to select the approperate Python when runningpysparkcommand:PYSPARK_PYTHON=python3.6 pyspark
Run spark interactively within Python¶
You could use spark as a Python's module, but
PySparkisn't onsys.pathby default.That doesn't mean it can't be used as a regular library.
You can address this by either symlinking pyspark into your site-packages, or adding pyspark to sys.path at runtime. findspark does the latter.
To initialize PySpark, just call it within Python
import findspark
findspark.init('/usr/lib/spark-current/')
# Then you could import the `pyspark` module
import pyspark