Big Data Essentials¶
L13: Text Mining with Spark¶
Yanfei Kang
yanfeikang@buaa.edu.cn
School of Economics and Management
Beihang University
http://yanfei.site
Concepts in text processing¶
Corpora¶
Corpus is a large collection of texts. It is a body of written or spoken material upon which a linguistic analysis is based.
A corpus provides grammarians, lexicographers, and other interested parties with better discriptions of a language. Computer-procesable corpora allow linguists to adopt the principle of total accountability, retrieving all the occurrences of a particular word or structure for inspection or randomly selcted samples.
Corpus analysis provide lexical information, morphosyntactic information, semantic information and pragmatic information.
Tokens¶
A token is the technical name for a sequence of characters, that we want to treat as a group.
The vocabulary of a text is just the set of tokens that it uses, since in a set, all duplicates are collapsed together. In Python we can obtain the vocabulary items with the command:
set().
Stopwords¶
Stopwords are common words that generally do not contribute to the meaning of a sentence, at least for the purposes of information retrieval and natural language processing.
These are words such as the and a. Most search engines will filter out stopwords from search queries and documents in order to save space in their index.
Stemming¶
Stemming is a technique to remove affixes from a word, ending up with the stem. For example, the stem of cooking is cook , and a good stemming algorithm knows that the ing suffix can be removed.
Stemming is most commonly used by search engines for indexing words. Instead of storing all forms of a word, a search engine can store only the stems, greatly reducing the size of index while increasing retrieval accuracy.
Frequency Counts¶
- Frequency Counts the number of hits.
- Frequency counts require finding all the occurences of a particular feature in the corpus.
- So it is implicit in concordancing. Software is used for this purpose. Frequency counts can be explained statistically.
Word Segmenter¶
Word segmentation is the problem of dividing a string of written language into its component words.
In English and many other languages using some form of the Latin alphabet, the space is a good approximation of a word divider (word delimiter). (Some examples where the space character alone may not be sufficient include contractions like can't for can not.)
However the equivalent to this character is not found in all written scripts, and without it word segmentation is a difficult problem. Languages which do not have a trivial word segmentation process include Chinese, Japanese, where sentences but not words are delimited, Thai and Lao, where phrases and sentences but not words are delimited, and Vietnamese, where syllables but not words are delimited.
Part-Of-Speech Tagger¶
In corpus linguistics, part-of-speech tagging (POS tagging or POST), also called grammatical tagging or word-category disambiguation, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition, as well as its context—i.e. relationship with adjacent and related words in a phrase, sentence, or paragraph.
A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
Named Entity Recognizer¶
- Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify elements in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages.
Word embeddings¶
- Word frequency based
- Prediction based
Word embeddings¶
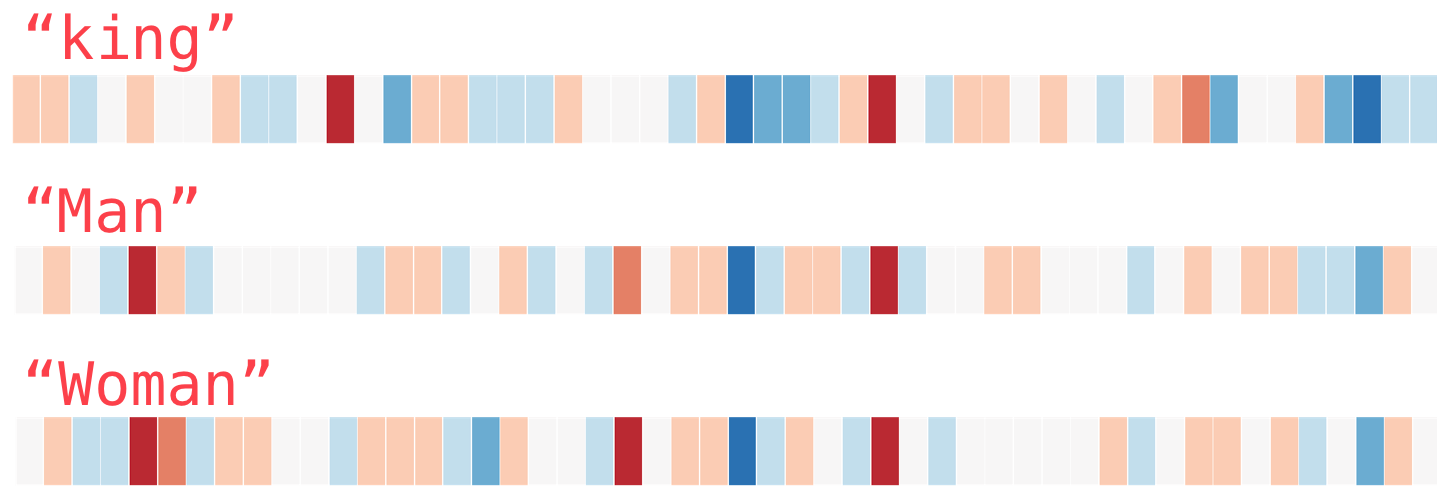
This is a word embedding for the word “king” (GloVe vector trained on Wikipedia):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
King¶

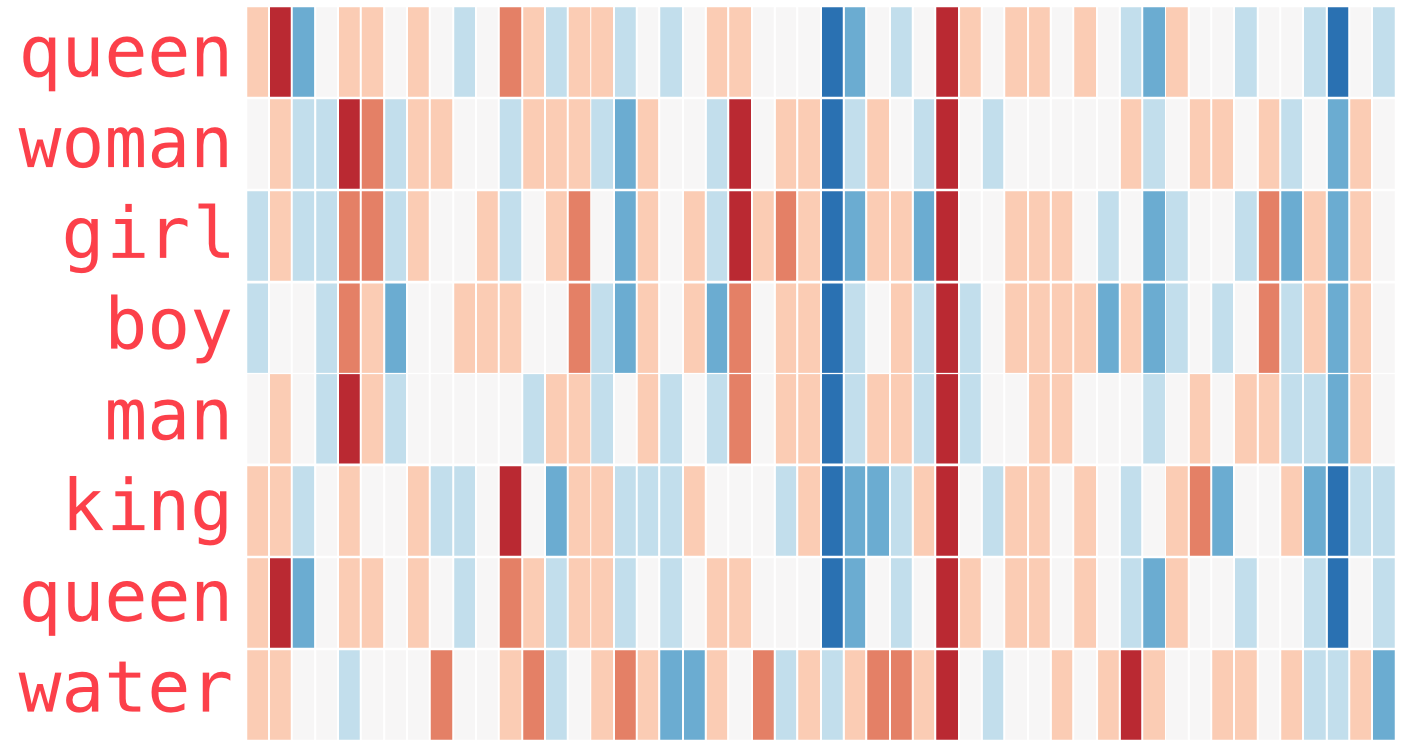
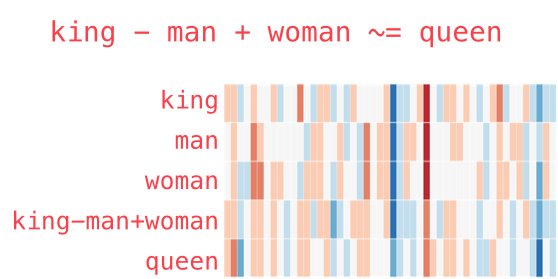
Analogy¶
Text Feature Extractors¶
import findspark
findspark.init('/usr/lib/spark-current')
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Python Spark with TM").getOrCreate()
from pyspark.ml.feature import Tokenizer
sentenceData = spark.createDataFrame([
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat")
], ["label", "sentence"])
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
tokenizer
wordsData = tokenizer.transform(sentenceData)
wordsData.show()
Count vectorizer¶
Denote a term by $t$, a document by $d$, and the corpus by $D$. Term frequency $TF(t,d)$ is the number of times that term t appears in document $d$.
# CountVectorizer can be used to get term frequency vectors
from pyspark.ml.feature import CountVectorizer
cv = CountVectorizer(inputCol="words", outputCol="rawFeatures")
model = cv.fit(wordsData)
result = model.transform(wordsData)
result.show(truncate=False)
IDF¶
- If we only use term frequency to measure the importance, it is very easy to over-emphasize terms that appear very often but carry little information about the document, e.g., “a”, “the”, and “of”. If a term appears very often across the corpus, it means it doesn’t carry special information about a particular document.
- IDF (Inverse document frequency) is a numerical measure of how much information a term provides: $$IDF(t, D) = \log \frac{|D| + 1}{DF(t, D) + 1},$$ where $|D|$ is the total number of documents in the corpus.
- Since logarithm is used, if a term appears in all documents, its IDF value becomes 0. Note that a smoothing term is applied to avoid dividing by zero for terms outside the corpus.
# We use IDF to rescale the feature vectors
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(result)
rescaledData = idfModel.transform(result)
rescaledData.select("label", "features").show(truncate=False)
HashingTF¶
# Alternatively, we can use hashingTF to extract features
from pyspark.ml.feature import HashingTF, IDF
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(wordsData)
featurizedData.show(featurizedData.count(), truncate=False)
Word2Vec¶
Word2Vec is an Estimator which takes sequences of words representing documents and trains a Word2VecModel.
The model maps each word to a unique fixed-size vector.
The Word2VecModel transforms each document into a vector using the average of all words in the document; this vector can then be used as features for prediction, document similarity calculations, etc. Please refer to the MLlib user guide on Word2Vec for more details.
from pyspark.ml.feature import Word2Vec
# Input data: Each row is a bag of words from a sentence or document.
documentDF = spark.createDataFrame([
("Hi I heard about Spark".split(" "), ),
("I wish Java could use case classes".split(" "), ),
("Logistic regression models are neat".split(" "), )
], ["text"])
# Learn a mapping from words to Vectors.
word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result")
model = word2Vec.fit(documentDF)
result = model.transform(documentDF)
for row in result.collect():
text, vector = row
print("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector)))
Remove stop words¶
from pyspark.ml.feature import StopWordsRemover
sentenceData = spark.createDataFrame([
(0, ["I", "saw", "the", "red", "balloon"]),
(1, ["Mary", "had", "a", "little", "lamb"])
], ["id", "raw"])
remover = StopWordsRemover(inputCol="raw", outputCol="filtered")
remover.transform(sentenceData).show(truncate=False)
$n$-gram¶
An $n$-gram is a sequence of $n$ tokens (typically words) for some integer $n$. The NGram class can be used to transform input features into $n$-grams.
NGram takes as input a sequence of strings (e.g. the output of a Tokenizer).
- The parameter
nis used to determine the number of terms in each $n$-gram. - The output will consist of a sequence of $n$-grams where each $n$-gram is represented by a space-delimited string of $n$ consecutive words. If the input sequence contains fewer than n strings, no output is produced.
from pyspark.ml.feature import NGram
wordDataFrame = spark.createDataFrame([
(0, ["Hi", "I", "heard", "about", "Spark"]),
(1, ["I", "wish", "Java", "could", "use", "case", "classes"]),
(2, ["Logistic", "regression", "models", "are", "neat"]),
(3, ["I", "like", "regression", "models"]),
], ["id", "words"])
ngram = NGram(n=2, inputCol="words", outputCol="ngrams")
ngramDataFrame = ngram.transform(wordDataFrame)
ngramDataFrame.select("ngrams").show(truncate=False)
Topic modelling with LDA¶
LDA is an unsupervised method that models documents and topics based on Dirichlet distribution, wherein each document is considered to be a distribution over various topics and each topic is modeled as a distribution over words.
Therefore, given a collection of documents, LDA outputs a set of topics, with each topic being associated with a set of words.
To model the distributions, LDA also requires the number of topics (often denoted by k) as an input. For instance, the following are the topics extracted from a random set of tweets from Canadian users where k = 3:
- Topic 1: great, day, happy, weekend, tonight, positive experiences
- Topic 2: food, wine, beer, lunch, delicious, dining
- Topic 3: home, real estate, house, tips, mortgage, real estate
from pyspark.ml.clustering import LDA
# Loads data.
dataset = spark.read.format("libsvm").load("/opt/apps/ecm/service/spark/2.4.5-hadoop3.1-1.0.2/package/spark-2.4.5-hadoop3.1-1.0.2/data/mllib/sample_lda_libsvm_data.txt")
dataset.head(10)
# Trains a LDA model.
lda = LDA(k=10, maxIter=10)
model = lda.fit(dataset)
ll = model.logLikelihood(dataset)
lp = model.logPerplexity(dataset)
print("The lower bound on the log likelihood of the entire corpus: " + str(ll))
print("The upper bound on perplexity: " + str(lp))
# Describe topics.
topics = model.describeTopics(3)
print("The topics described by their top-weighted terms:")
topics.show(truncate=False)
# Shows the result
transformed = model.transform(dataset)
transformed.show(truncate=False)
Lab 8¶
- Find anEnglish corpras and load to Spark
- Text processing with the document
- Topic modeling with your data
- Visulize your result with Python