layout: true --- class: inverse, center, middle background-image: url(figures/titlepage16-9.png) background-size: cover <br> # 商业预测 ## 第六讲:商业预测前沿 <img src="figures/qr.png" width="150px"/> #### 康雁飞 | 北航经管学院 | 数量经济与商务统计系 --- # 商业预测前沿方法 - 分层或分组时间序列预测 - 神经网络模型 - 预测组合 - Bagging - 预测现实 --- class: inverse, center, middle # 分层或分组时间序列预测 --- # 分层时间序列 时间序列通常可以按照各种感兴趣的属性自然地进行分类,如组织结构、地理位置或地理结构、产品层次结构。 --- # 例:产品需求层次 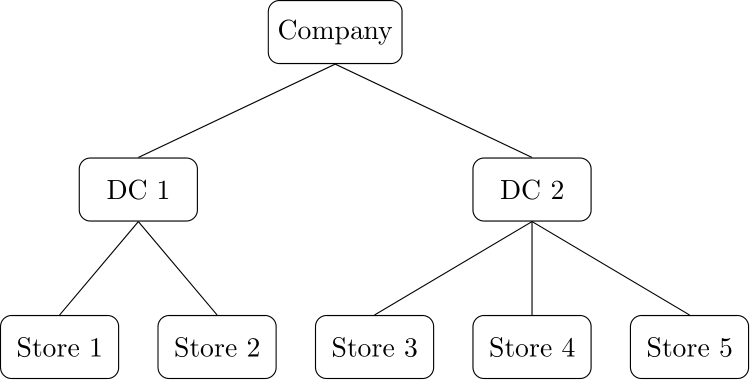 --- # 例:亚马逊产品需求 .scroll-output[ 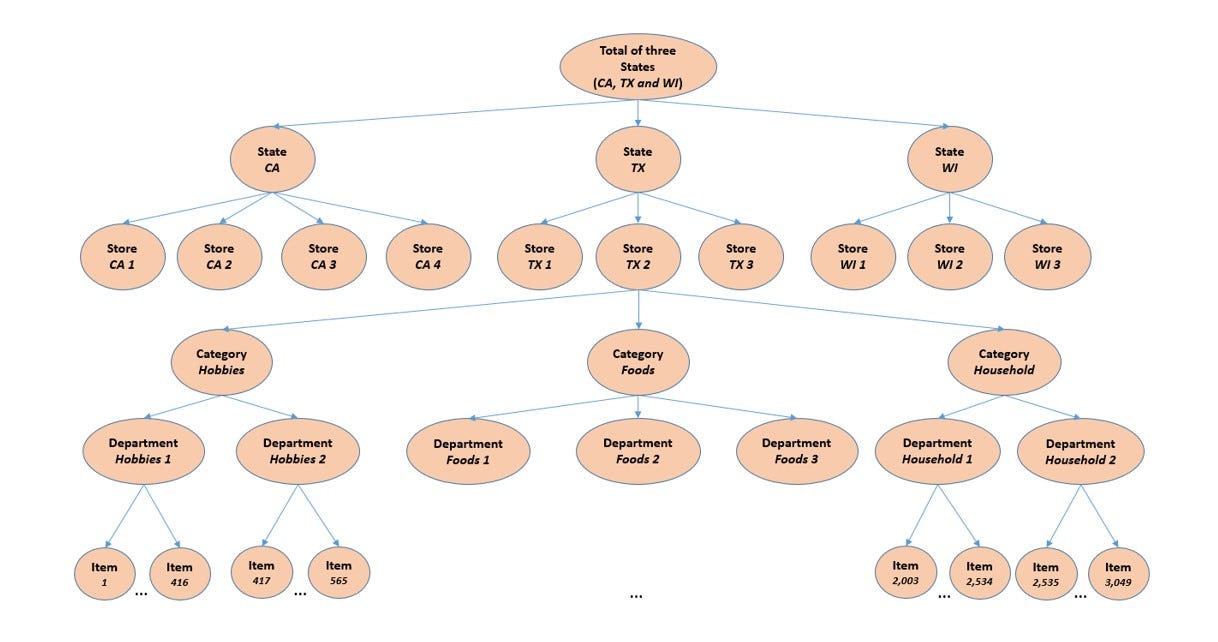] --- # 例:澳大利亚旅游层次 - 澳大利亚分为八个地理区域(一些称为州,另一些称为地区),每个区域都有自己的政府和一些经济和行政自治机构。这些中的每一个可以按兴趣进一步细分为更小的部分,称为区。 - 商业规划者和旅游部门对整个澳大利亚,各州和地区以及各区的预测很感兴趣。在这个例子中,我们主要关注国内旅游的季度需求,以澳大利亚人出门在外的过夜数来衡量。 - 有六个州:新南威尔士州(NSW),昆士兰州(QLD),南澳大利亚州(SAU),维多利亚州(VIC),西澳大利亚州(WAU)和其他州(OTH)。对于其中的每一个州,我们考虑以下这些区的游客过夜数。 --- # 例:澳大利亚旅游层次 |州 |区 | |:------|:---------------------------------------------------------------------| |NSW |大都会(NSWMetro),北海岸(NSWNthCo),南海岸(NSWSthCo),南部内陆(NSWSthIn),北部内陆(NSWNthIn)| |QLD |大都会(QLDMetro),中部(QLDCntrl),北海岸(QLDNthCo)| |SAU |大都会(SAUMetro),海岸(SAUCoast),内陆(SAUInner)| |VIC |大都会(VICMetro),西海岸(VICWstCo),东海岸(VICEstCo),内陆(VICInner)| |WAU |大都会(WAUMetro),海岸(WAUCoast),内陆(WAUInner)| |OTH |大都会(OTHMetro),非大都会(OTHNoMet)| --- # 需求预测 .scroll-output[  ] --- # 自下而上(Bottom-up) .scroll-output[ 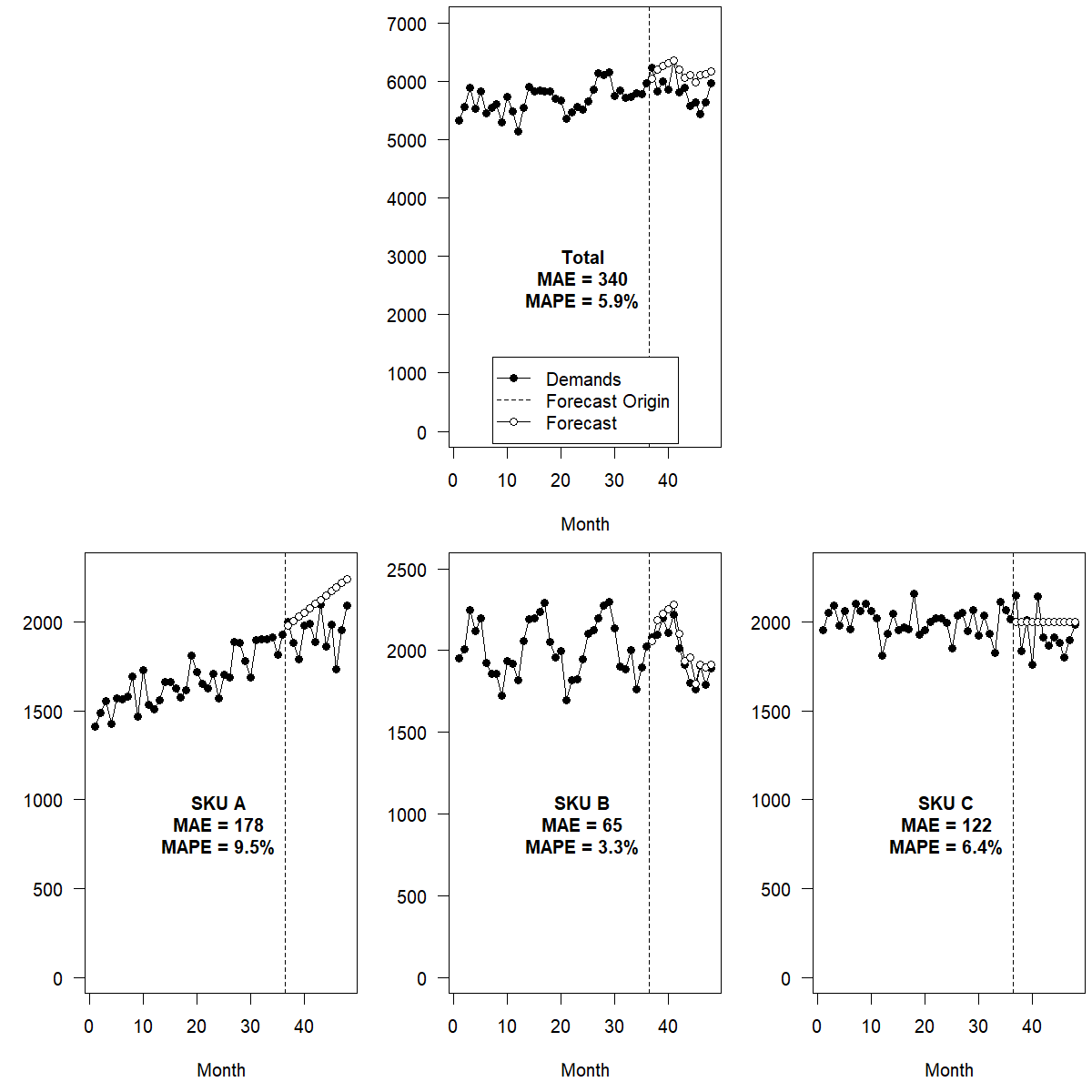 ] --- # 自上而下(Top-down) .scroll-output[  ] --- # 最优调和(Optimal Reconciliation) .scroll-output[  ] --- # 旅游预测:`hts()` .pull-left[ ```r library(hts) tourism.hts <- hts(visnights, characters = c(3, 5)) tourism.hts %>% aggts(levels=0:1) %>% autoplot(facet=TRUE) + xlab("年份") + ylab("百万") + ggtitle("游客过夜数")+ theme(plot.title = element_text(hjust = 0.5)) ``` ] .pull-right[ <img src="BF-L6-advanced_files/figure-html/tourismStates-out-1.png" style="display: block; margin: auto;" /> ] --- # 自下而上预测 ```r forecast(tourism.hts, method="bu", fmethod="arima") ``` ``` ## Hierarchical Time Series ## 3 Levels ## Number of nodes at each level: 1 6 20 ## Total number of series: 27 ## Number of observations in each historical series: 76 ## Number of forecasts per series: 8 ## Top level series of forecasts: ## Qtr1 Qtr2 Qtr3 Qtr4 ## 2017 90.76257 72.40181 76.00051 78.42748 ## 2018 90.16914 72.78868 75.65169 78.33982 ``` --- # 自上而下预测 ```r forecast(tourism.hts, method="tdfp", fmethod="arima") ``` ``` ## Hierarchical Time Series ## 3 Levels ## Number of nodes at each level: 1 6 20 ## Total number of series: 27 ## Number of observations in each historical series: 76 ## Number of forecasts per series: 8 ## Top level series of forecasts: ## Qtr1 Qtr2 Qtr3 Qtr4 ## 2017 95.65193 78.02317 82.30592 83.67373 ## 2018 97.22648 79.59772 83.88048 85.24828 ``` --- # 中间突破法预测 ```r forecast(tourism.hts, method="mo", fmethod="arima", level=1) ``` ``` ## Hierarchical Time Series ## 3 Levels ## Number of nodes at each level: 1 6 20 ## Total number of series: 27 ## Number of observations in each historical series: 76 ## Number of forecasts per series: 8 ## Top level series of forecasts: ## Qtr1 Qtr2 Qtr3 Qtr4 ## 2017 93.32627 75.70450 79.51271 81.15298 ## 2018 93.90874 76.57744 80.37253 82.02744 ``` --- # 最优调和法预测 ```r forecast(tourism.hts, method="comb", fmethod="arima") ``` ``` ## Hierarchical Time Series ## 3 Levels ## Number of nodes at each level: 1 6 20 ## Total number of series: 27 ## Number of observations in each historical series: 76 ## Number of forecasts per series: 8 ## Top level series of forecasts: ## Qtr1 Qtr2 Qtr3 Qtr4 ## 2017 92.55729 74.59201 78.37077 80.33918 ## 2018 92.75248 75.35934 78.79227 80.88062 ``` --- # 预测效果评价 ```r train <- window(tourism.hts, end = c(2014, 4)) test <- window(tourism.hts, start = 2015) fcsts.opt <- forecast(train, h = 8, method = "comb", fmethod = "arima") fcsts.bu <- forecast(train, h = 8, method = "bu", fmethod = "arima") cbind(accuracy(fcsts.opt, test, levels = 0), accuracy(fcsts.bu, test, levels = 0)) ``` ``` ## Total Total ## ME 8.338903 8.521813 ## RMSE 8.708361 8.894777 ## MAE 8.338903 8.521813 ## MAPE 10.232566 10.453860 ## MPE 10.232566 10.453860 ## MASE 2.552022 2.607999 ``` --- # 预测效果比较 <table> <caption></caption> <thead> <tr> <th style="empty-cells: hide;border-bottom:hidden;" colspan="1"></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; " colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">自下而上法</div></th> <th style="border-bottom:hidden;padding-bottom:0; padding-left:3px;padding-right:3px;text-align: center; " colspan="2"><div style="border-bottom: 1px solid #ddd; padding-bottom: 5px; ">最优调和法</div></th> </tr> <tr> <th style="text-align:left;"> </th> <th style="text-align:right;"> MAPE </th> <th style="text-align:right;"> MASE </th> <th style="text-align:right;"> MAPE </th> <th style="text-align:right;"> MASE </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> 总计 </td> <td style="text-align:right;"> 10.45 </td> <td style="text-align:right;"> 2.61 </td> <td style="text-align:right;"> 10.23 </td> <td style="text-align:right;"> 2.55 </td> </tr> <tr> <td style="text-align:left;"> 州 </td> <td style="text-align:right;"> 12.01 </td> <td style="text-align:right;"> 1.71 </td> <td style="text-align:right;"> 11.93 </td> <td style="text-align:right;"> 1.73 </td> </tr> <tr> <td style="text-align:left;"> 底层 </td> <td style="text-align:right;"> 13.92 </td> <td style="text-align:right;"> 1.29 </td> <td style="text-align:right;"> 13.86 </td> <td style="text-align:right;"> 1.29 </td> </tr> <tr> <td style="text-align:left;"> 所有序列 </td> <td style="text-align:right;"> 13.37 </td> <td style="text-align:right;"> 1.43 </td> <td style="text-align:right;"> 13.29 </td> <td style="text-align:right;"> 1.44 </td> </tr> </tbody> </table> --- class: inverse, center, middle # 神经网络模型 --- # 神经网络架构 .pull-left[ - 神经网络可以被理解为是一种分层的“神经元”网络结构。 - 预测变量(或输入)构成底层,响应变量(或输出)构成顶层。还可能存在包含“隐藏神经元”的中间层。 - 最简单的网络不包含中间的隐藏层,等价于线性回归。 ] .pull-right[ <div class="figure" style="text-align: center"> <img src="figures/nnet1.png" alt="与线性回归等价的简单神经网络。" width="75%" /> <p class="caption">与线性回归等价的简单神经网络。</p> </div> ] --- # 神经网络架构 如果我们增加一个包含隐藏神经元的中间层,神经网络就成为非线性形式。 <div class="figure" style="text-align: center"> <img src="figures/nnet2.png" alt="包含4个输入及1个隐藏层的神经网络,其中隐藏层中包含3个隐藏神经元。" width="80%" /> <p class="caption">包含4个输入及1个隐藏层的神经网络,其中隐藏层中包含3个隐藏神经元。</p> </div> --- # 神经网络自回归 - 类似于我们在线性自回归模型中使用滞后值作为自变量一样,对于时间序列数据,时间序列的滞后值也可以作为神经网络的输入。我们称之为神经网络自回归或 NNAR 模型。 - 我们只考虑包含一个隐藏层的前馈网络的情况,使用符号 NNAR($p,k$) 来表示隐藏层中有 `\(p\)` 期滞后输入和 `\(k\)` 个节点。 - 例如, NNAR(9,5) 模型是一个使用滞后9期观测值 `\((y_{t-1},y_{t-2},\dots,y_{t-9})\)` 作为输入,预测 `\(y_t\)` 的神经网络,且该神经网络中隐藏层有5个神经元。 NNAR( `\(p,0\)` ) 模型相当于 ARIMA( `\(p,0,0\)`) 模型,但这里不包含为确保平稳性而对参数的限制。 - 对于季节性数据,可以考虑增加同一季节的最后观测值作为输入。例如, NNAR(3,1,2) `\(_{12}\)` 模型的输入为 `\(y_{t-1}\)` , `\(y_{t-2}\)` , `\(y_{t-3}\)` , `\(y_{t-12}\)` ,隐藏层中有两个神经元。更一般地, NNAR( `\(p,P,k\)`) `\(_m\)` 模型的输入为 `\((y_{t-1},y_{t-2},\dots,y_{t-p},y_{t-m},y_{t-2m},y_{t-Pm})\)` ,隐藏层有 `\(k\)` 个神经元。 NNAR( `\(p,P,0\)`) `\(_m\)` 模型相当于 ARIMA( `\(p,0,0\)`)( `\(P\)`,0,0) `\(_m\)` 模型,但不包含为确保平稳性而对参数的限制。 --- # 神经网络自回归 - 函数 `nnetar()`可用于拟合 NNAR( `\(p,P,k\)`) `\(_m\)` 模型。 - 使用神经网络进行预测的时候,计算会迭代进行。比如向前预测一步时,我们只需要将历史数据作为输入。向前预测两步时,需要将历史数据和向前一步预测值作为神经网络的输入。这样的迭代会继续向后进行,直到所有需要的预测值都被计算出来。 --- # 例:太阳黑子 .pull-left[ 太阳的表面含有磁区,这些磁区看起来像黑色的点。它们会影响无线电波的传播,因此电信公司喜欢预测太阳黑子的活动,以便为将来的困难做好准备。太阳黑子的一个周期为9到14年。下图中展示了 NNAR(10,6) 模型未来30年的预测值。我们进行了`lambda=0`的Box-Cox 变换,以确保预测值始终为正数值。 ```r fit <- nnetar(sunspotarea, lambda=0) autoplot(forecast(fit,h=30)) + xlab("时间") + ylab("太阳黑子活动") ``` ] .pull-right[ <img src="BF-L6-advanced_files/figure-html/sunspotnnetar-out-1.png" style="display: block; margin: auto;" /> ] --- class: inverse, center, middle # 预测组合 --- # 模型组合 把不同的模型组合在一起进行预测通常会得到比最优预测更优的结果。 - 简单组合: `\(f^{c}=\frac{1}{P} \sum_{i=1}^{P} f_{i}\)`。 - 基于回归的组合: `\(f^{c}= \sum_{i=1}^{P} \beta_i f_{i}\)`。 - 基于特征的组合: `\(f^{c}= \sum_{i=1}^{P} \omega_i f_{i}\)`。 --- # 模型组合 <img src="BF-L6-advanced_files/figure-html/unnamed-chunk-5-1.png" style="display: block; margin: auto;" /> --- # 示例:澳大利亚外出就餐的月度支出数据 我们使用以下模型进行预测: ETS , ARIMA , STL-ETS , NNAR 和 TBATS ;我们对过去5年(60个月)的观察结果进行比较。 .scroll-output[ ```r train <- window(auscafe, end=c(2012,9)) h <- length(auscafe) - length(train) ETS <- forecast(ets(train), h=h) ARIMA <- forecast(auto.arima(train, lambda=0, biasadj=TRUE), h=h) STL <- stlf(train, lambda=0, h=h, biasadj=TRUE) NNAR <- forecast(nnetar(train), h=h) TBATS <- forecast(tbats(train, biasadj=TRUE), h=h) Combination <- (ETS[["mean"]] + ARIMA[["mean"]] + STL[["mean"]] + NNAR[["mean"]] + TBATS[["mean"]])/5 autoplot(auscafe) + autolayer(ETS, series="ETS", PI=FALSE) + autolayer(ARIMA, series="ARIMA", PI=FALSE) + autolayer(STL, series="STL", PI=FALSE) + autolayer(NNAR, series="NNAR", PI=FALSE) + autolayer(TBATS, series="TBATS", PI=FALSE) + autolayer(Combination, series="Combination") + xlab("年") + ylab("十亿美元") + ggtitle("澳大利亚外出就餐月支出") ``` <img src="BF-L6-advanced_files/figure-html/unnamed-chunk-6-1.png" style="display: block; margin: auto;" /> ] --- # 预测评价 ```r c(ETS=accuracy(ETS, auscafe)["Test set","RMSE"], ARIMA=accuracy(ARIMA, auscafe)["Test set","RMSE"], `STL-ETS`=accuracy(STL, auscafe)["Test set","RMSE"], NNAR=accuracy(NNAR, auscafe)["Test set","RMSE"], TBATS=accuracy(TBATS, auscafe)["Test set","RMSE"], Combination=accuracy(Combination, auscafe)["Test set","RMSE"]) ``` ``` ## ETS ARIMA STL-ETS NNAR TBATS Combination ## 0.13699696 0.15919858 0.19310148 0.33548889 0.09406039 0.07217230 ``` --- # 参考 参考预测组合综述论文: Xiaoqian Wang, Rob Hyndman, Feng Li, Yanfei Kang (2023). Forecast combinations: an over 50-year review. International Journal of Forecasting 39(4): 1518-1547. https://yanfei.site/docs/paper/fcreview.pdf --- class: inverse, center, middle # Bagging --- # Bagging (**B**ootstrap **agg**regat**ing**) .pull-left[ ```r bootseries <- bld.mbb.bootstrap(debitcards, 10) %>% as.data.frame() %>% ts(start=2000, frequency=12) autoplot(debitcards) + autolayer(bootseries, colour=TRUE) + autolayer(debitcards, colour=FALSE) + xlab("时间") + ylab("Bootstrap 序列") + guides(colour="none") ``` ] .pull-right[ <img src="BF-L6-advanced_files/figure-html/bagging-out-1.png" style="display: block; margin: auto;" /> ] --- # Bagging - Bootstrap 得到的时间序列可以用来提高预测的准确性。 - 如果我们对每一个 Bootstrap 时间序列进行预测,并对预测结果进行平均,那么我们会得到相比直接对原始时间序列进行预测更好的预测结果。 - 这个过程称为"bagging"。 --- # Bagging .pull-left[ ```r etsfc <- debitcards %>% ets() %>% forecast(h=36) baggedfc <- debitcards %>% baggedETS() %>% forecast(h=36) autoplot(debitcards) + autolayer(baggedfc$mean, series="BaggedETS") + autolayer(etsfc$mean, series="ETS") + guides(colour=guide_legend(title="Forecasts")) + xlab("时间") + ylab("借记卡月支出") ``` ] .pull-right[ <img src="BF-L6-advanced_files/figure-html/baggingeg-out-1.png" style="display: block; margin: auto;" /> ] --- class: inverse, center, middle # 预测现实 --- class: inverse, middle > "In theory, there is no difference between theory and practice. But, in practice, there is." > -- Benjamin Brewster (1882). --- # 预测现实 1:周数据、日数据及日以下数据 周数据很难进行预测是因为季节周期(一年中的周数)非常大且非整数。一年中的平均周数是 52.18 。我们考虑的大多数方法都是基于整数季节周期进行的。即使我们将周数据的季节周期近似为52,大多数方法也难以有效地处理这么大的季节周期数据。 1. STL 分解,并将非季节性方法应用于季节调整数据 2. 动态谐波回归模型 --- # 示例:周度美国成品汽油产品供应量 .scroll-output[ ```r gasoline %>% stlf() %>% autoplot() + xlab("时间") ``` <img src="BF-L6-advanced_files/figure-html/unnamed-chunk-8-1.png" style="display: block; margin: auto;" /> ] --- # 日数据及日以下数据 - 日数据和日以下数据难以预测的原因与周数据相比则有所不同 —— 它们通常涉及多个季节模式,所以我们需要使用一种能处理这种复杂季节性数据的方法。 - STL、动态谐波回归或者 TBATS。 - 适用于常规季节性的时间序列。捕捉像复活节、农历新年这些移动事件的季节性是十分困难的。即使有月度数据也很棘手,因为这些节日可能在三月或四月(复活节),一月或二月(农历新年),也可能在一年中的任何时候。 - 处理移动节日的最佳方法是使用虚拟变量作为协变量,此时可以使用动态回归模型/其他形式的回归模型,在此模型中,自变量中可以包含描述节日效应的虚拟变量(也可以是傅里叶项)。 --- # 预测现实 2:计数时间序列 .pull-left[ ```r productC %>% croston() %>% autoplot() + xlab("时间") + ggtitle('某石油公司润滑剂销量') ``` 参考 [`tsintermittent`](https://cran.r-project.org/package=tsintermittent) 包。 ] .pull-right[ <img src="BF-L6-advanced_files/figure-html/count-out-1.png" style="display: block; margin: auto;" /> ] --- # 预测现实 3:历史数据有限 - 如何使用很少的数据点来拟合时间序列模型? - 取决于要估计的模型参数的数量和数据的随机性。 - 对于 ARIMA 建模通常给出最小样本量为30。 - 对于数据量有限的数据,推荐简单模型。 --- # 预测现实 4:历史数据太长 - 大多数时间序列模型对长期时间序列都不适用。 1. 真实数据并非来自我们使用的模型。当观测值数量不太大(比如大约200个)时,模型通常可以很好的近似生成数据的过程。但最终当你得到足够多的数据时,真正的数据生成过程与模型之间的差异开始变得更加明显。 2. 由于观测样本量增加,模型参数的优化变得更加耗时。 - 如何处理这些问题取决于模型的目的。可以使用更加灵活和复杂的模型,但这仍然需要假定模型结构适用于整个数据周期。更好的方法通常是允许模型本身随时间变化。 - 如果你只对预测接下来的少数观测值感兴趣,一个简单的方法就是抛弃最早的观测值,只用最近的观测值拟合模型。 --- # 预测现实 5:缺失和异常处理 - 当缺失值引发报错时,至少有两种方法可以解决问题。首先,假如有足够长的观测序列可以用来进行有意义的预测时,我们可以只选取最后一个缺失值之后的数据部分。或者,我们可以用估计值替换缺失值。`na.interp()`函数可以实现这个过程。 - 函数 `tsoutliers()` 函数用于识别离群值,并提供可能的替换值。 - 另一个有用的函数是 `tsclean()`,它能够标识并替换离群值,也能够替换缺失值。 --- # 示例:每天早上的黄金价格 .scroll-output[ ```r gold2 <- na.interp(gold) autoplot(gold2, series="Interpolated") + autolayer(gold, series="Original") + scale_color_manual(values=c(`Interpolated`="red",`Original`="gray")) + xlab("时间") ``` <img src="BF-L6-advanced_files/figure-html/unnamed-chunk-9-1.png" style="display: block; margin: auto;" /> ] --- # 示例:每天早上的黄金价格 ```r tsoutliers(gold) ``` ``` ## $index ## [1] 770 ## ## $replacements ## [1] 494.9 ``` --- # 示例:每天早上的黄金价格 .scroll-output[ ```r gold %>% tsclean() %>% ets() %>% forecast(h=50) %>% autoplot() + xlab("时间") ``` <img src="BF-L6-advanced_files/figure-html/unnamed-chunk-11-1.png" style="display: block; margin: auto;" /> ] --- # 预测现实 6:数据量大且相关 - 全局模型 (M5 竞赛) - 预测组合 (M 竞赛) - No-Free-Lunch(M4 竞赛) --- # 基于特征的预测组合 <img src="figures/forecastdiag.jpg" width="80%" style="display: block; margin: auto;" /> --- # 基于特征的组合 <img src="figures/fforma.png" style="display: block; margin: auto;" /> --- # 什么是特征? - 信息熵 - 自相关性 - 异常性 - 等等 - 详见 **tsfeatures** 包。 --- # 怎样学习权重 `\(\omega_i\)`? - 优化理论 - 机器学习 - 例: `xgboost` - 详见 [M4metalearning 包](https://github.com/robjhyndman/M4metalearning/blob/master/docs/metalearning_example.md) --- # 预测现实 6:领域相关 - 参考预测百科论文: https://yanfei.site/docs/paper/ftp.pdf - 在线版:https://forecasting-encyclopedia.com/ --- # 课程报告 任选感兴趣领域的时间序列数据,根据其特点,选择适当的预测方法完成预测。报告应使用规定封面,内容详实,包括且不限于: - 研究意义 - 研究方法 - 研究结果 - 结论