第 2 章 R 语言与可复现计算
2.1 统计语言的历史
在现代统计计算中,最早被统计广泛使用的编程语言应该是20世纪Fortran(Formula Translation的缩写)语言。虽然Fortran语言运行速度较快,但是由于Fortran语言语法书写较为繁琐而且需要编译,逐渐被不需要编译的脚本语言所取代。Fortran语言的第一个替代版本是贝尔实验室S编程语言。S语言由约翰·钱伯斯(John Chambers)于1976年在贝尔实验室(Bell Labs)创立。
R语言是受Scheme语言(一种函数式编程语言)启发,并对S语言加以开源实现, 最新版本的R语言与早期的S有一些重要的区别。R语言书由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman创建,并由RDevelopment Core团队开发,S语言之父Chambers也是R核心开发团队的成员。读者可能注意到,R语言的命名以前两个R作者的名字首字母命名。R语言项目于1992年构思,1995年发布了最初版本,2000年2月29日发布了稳定的beta版本(v1.0),截止2020年,已经到v4.0版本。
R的许多功能通过用户创建的R包得到扩展,这些包涵盖专门的统计技术,图形设备,导入/导出功能,报告工具(Rmarkdown,knitr,Sweave)等。R的安装除了包含一组核心软件包,还有大量的发布到CRAN, Bioconductor,Omegahat,GitHub等超过15,000个贡献软件包供使用。
近些年来,由于大数据的迅猛发展,R也被广泛集成到大数据计算平台。例如R是大数据分布式计算平台Apache Spark支持的五种语言之一。
现代计算机与数据科学发展催生了很多很有特色的针对数据处理和建模的开源编程语言,如擅长数据科学处理的Python语言,语法简介且计算高效的Julia语言,具有大数据分布式计算基因的Scala语言。R语言由于其在统计计算领域的30多年的主导地位,现在仍然是主流统计计算的入门语言。没有编程基础的读者学习了R语言,一般都可以触类旁通,快速上手其他语言。
2.2 R 语言介绍
本书使用 R 语言。R 是什么呢?在 R 的官网上是这么描述的:
“… a freely available language and environment for statistical computing and graphics which provides a wide variety of statistical and graphical techniques: linear and nonlinear modelling, statistical tests, time series analysis, classification, clustering, etc….”
所以 R 是免费的、几乎适用于任何操作系统的一种语言和环境。在 R 里可安装上千个包,几乎可以做任何你想做的事情,具体来讲,它主要用于统计计算和统计图,包括线性和非线性模型、统计检验、时间序列分析、分类、聚类等。我们推荐通过 Rstudio 使用 R。
安装 R 和 RStudio
在 R 中可以在控制台(console)执行所有命令,但是更方便的是写 R 脚本(scripts),这时需要一个编辑器(editor)。Rstudio 是一个 R 语言的集成开发环境(Integrated Development Environment,IDE),它因为集成了编辑、调试(debugging)、可视化、R Markdown、R Notebook 等强大功能、非常受 R 用户的欢迎。下面给出 R 和 Rstudio 的下载地址。
R 工作目录
当我们打开 R 或者 Rstudio 时,会有默认的工作目录,我们可以通过 getwd() 函数来看一下当前的工作目录。
开始任何一个任务之前,应该设置对应的工作目录,这可以通过 setwd() 来完成。当然可以在 R 的设置中也可以设置默认的初始工作目录。
2.3 R 中的数据结构
R 是基于对象(objects)的,对象可以是 R 中的任何存在,如常数、数据结构、函数、图等。给定任何一个对象,可以通过 str() 来了解该对象的结构。R 中常用的基础数据结构有向量(vector)、列表(list)、矩阵(matrix)、数据框(data frame)等。
2.3.1 向量
向量是 R 中最基础的数据结构,向量分为逻辑型(logical)、整数型(integer)、数值型(Numeric)和字符型(character)几个类型。向量通过可以通过 c() 来创建,其中 “c”代表“combine”:
num_x <- c(1.2, 4.5, 6)
int_x <- c(1L, 6L, 80L)
log_x <- c(TRUE, FALSE, T, F, F)
cha_x <- c('yanfei', 'feng')
cha_x
#> [1] "yanfei" "feng"也可以通过比如以下方式直接生成一个向量:
2.3.4 数据框
数据框是 R 中最常用的数据结构,它是一种特殊的列表,这种列表中的每个元素长度都相等,因此它是兼有矩阵和列表的特性的二维结构。数据框可以通过 data.frame() 来创建:
df <- data.frame(x = 1:10, y = letters[1:10])
str(df)
#> 'data.frame': 10 obs. of 2 variables:
#> $ x: int 1 2 3 4 5 6 7 8 9 10
#> $ y: chr "a" "b" "c" "d" ...数据框也可以用 rbind() 和 cbind() 来合并。数据框的列可以为列表,如:
2.3.5 子集提取
在 R 中有三种操作符可以提取不同数据结构的子集:
[可以返回与原数据相同的数据类型。[[用于提取列表和数据框的子集。$可以依据变量名字提取列表和数据框的子集。
下面举例说明。
提取数据框的子集
x <- data.frame(a = 1:10, b = letters[1:10], d = rnorm(10))
x$a # 提取x的a元素,相当于 x[[1]]
#> [1] 1 2 3 4 5 6 7 8 9 10
x[1] # 返回的还是数据框
#> a
#> 1 1
#> 2 2
#> 3 3
#> 4 4
#> 5 5
#> 6 6
#> 7 7
#> 8 8
#> 9 9
#> 10 10
head(x) # 查看x的前6行
#> a b d
#> 1 1 a 0.5470
#> 2 2 b 0.1562
#> 3 3 c -0.9316
#> 4 4 d -0.4291
#> 5 5 e 0.1161
#> 6 6 f 1.1881
tail(x) # 查看x的后6行
#> a b d
#> 5 5 e 0.1161
#> 6 6 f 1.1881
#> 7 7 g -1.8455
#> 8 8 h -0.2789
#> 9 9 i -2.3050
#> 10 10 j -2.4771
nrow(x) # x的行数
#> [1] 10
ncol(x) # x的列数
#> [1] 3
names(x) # x的列名
#> [1] "a" "b" "d"2.4 R 中的数据输入输出
2.5 R 中的控制语句
2.5.2 for 循环
R 中 for 循环的写法为:
对于向量 vector 中的每一个元素 x,循环执行对应的代码。我们举一个例子:
x <- c("a", "b", "c", "d")
for(i in 1:4) {
## 打印 x 中的第 i 个元素
print(x[i])
}
#> [1] "a"
#> [1] "b"
#> [1] "c"
#> [1] "d"在这个例子中,我们也可以避免使用索引(index):
x <- c("a", "b", "c", "d")
for(x.ele in x) {
print(x.ele)
}
#> [1] "a"
#> [1] "b"
#> [1] "c"
#> [1] "d"在高维的数据结构中,for 循环可以是嵌套的:
2.5.4 循环函数
虽然 for 和 while 循环非常有用,但是在命令行执行循环语句的过程尤其繁琐,这时我们可以使用循环函数,常用的循环函数有:
lapply():对一个列表的每一个元素循环执行一个函数。sapply():和lapply相同,但是它可以简化输出结果。apply():对一个数组的边(如一个矩阵的行或列)执行一个函数。tapply():对于一个向量的子集执行一个函数。mapply():和lapply相似,但它适用于多元情形。
lapply()
lapply() 执行以下操作:
它对一个列表的每个元素进行循环。
它对一个列表的每个元素执行一个函数,这个函数是由你来制定的。
它返回的是一个列表。
lapply()中的 “l” 代表 “list”。
我们来看两个例子:
x <- 1:4
lapply(x, runif)
#> [[1]]
#> [1] 0.385
#>
#> [[2]]
#> [1] 0.5223 0.4924
#>
#> [[3]]
#> [1] 0.81271 0.07891 0.63233
#>
#> [[4]]
#> [1] 0.4900 0.2271 0.4985 0.7481在第一个例子中,我们分别求了列表 x 中每个元素的均值,也就是把 x 中的每个元素分别传递给 mean() 函数的第一个参数,最终返回的仍然是一个列表。在第二个例子中,我们得到的列表每个元素分别是不同长度的均匀分布的随机数。
sapply()
sapply() 函数和 lapply() 的不同之处在于它们返回的数据结构不同。sapply() 函数尽可能的简化 lapply() 的输出。我们可以对比一下两个函数:
x <- list(a = 1:5, b = rnorm(10))
lapply(x, mean)
#> $a
#> [1] 3
#>
#> $b
#> [1] -0.2262
sapply(x, mean)
#> a b
#> 3.0000 -0.2262
x <- 1:4
lapply(x, runif)
#> [[1]]
#> [1] 0.7996
#>
#> [[2]]
#> [1] 0.6798 0.9041
#>
#> [[3]]
#> [1] 0.1540 0.4775 0.2319
#>
#> [[4]]
#> [1] 0.4398 0.8341 0.4688 0.9288
sapply(x, runif)
#> [[1]]
#> [1] 0.1738
#>
#> [[2]]
#> [1] 0.3077 0.8567
#>
#> [[3]]
#> [1] 0.8124 0.3650 0.1968
#>
#> [[4]]
#> [1] 0.1180 0.8431 0.5125 0.5365我们看到在第一个例子中 sapply() 输出的是一个向量,简化了 lapply() 的输出。但是在第二个例子中,sapply() 输出的仍然是一个列表,因为在 lapply() 输出的列表中每个元素的长度不同。假若长度相同,sapply() 则可以简化结果如下:
x <- rep(3, 4)
lapply(x, runif)
#> [[1]]
#> [1] 0.6775 0.9967 0.3191
#>
#> [[2]]
#> [1] 0.9657 0.0935 0.3567
#>
#> [[3]]
#> [1] 0.5989 0.2656 0.7416
#>
#> [[4]]
#> [1] 0.2106 0.1453 0.4369
sapply(x, runif)
#> [,1] [,2] [,3] [,4]
#> [1,] 0.5173 0.5190 0.4298 0.13778
#> [2,] 0.3215 0.9658 0.4672 0.61509
#> [3,] 0.5834 0.4502 0.1323 0.05738apply()
apply() 可以对一个矩阵(或多维数组)的行或者列执行一个函数,如:
options(width = 50)
x <- matrix(rnorm(200), 10, 20)
# 对矩阵 x 的列求均值
apply(x, 2, mean)
#> [1] 0.17437 0.07463 -0.31853 0.10154 -0.12579
#> [6] -0.08245 0.52580 0.00473 0.16940 -0.27254
#> [11] 0.12730 0.18771 -0.11926 -0.14678 -0.33212
#> [16] -0.21819 -0.70370 -0.13478 0.23316 -0.40439
# 对矩阵 x 的每一行求 20% 和 75% 分位数
apply(x, 1, quantile, probs = c(0.25, 0.75))
#> [,1] [,2] [,3] [,4] [,5]
#> 25% -0.2880 -0.8593 -0.8059 -0.8780 -0.86641
#> 75% 0.8355 0.3652 0.5570 0.4038 0.06178
#> [,6] [,7] [,8] [,9] [,10]
#> 25% -0.6624 -0.8198 -1.267 -0.86620 -0.1495
#> 75% 0.8106 1.0479 1.215 0.07795 0.9440mapply()
mapply() 适用于多元情形。比如:
mapply(rep, 1:4, 4:1)
#> [[1]]
#> [1] 1 1 1 1
#>
#> [[2]]
#> [1] 2 2 2
#>
#> [[3]]
#> [1] 3 3
#>
#> [[4]]
#> [1] 4可以代替繁琐的重复编程:
list(rep(1, 4), rep(2, 3), rep(3, 2), rep(4, 1))
#> [[1]]
#> [1] 1 1 1 1
#>
#> [[2]]
#> [1] 2 2 2
#>
#> [[3]]
#> [1] 3 3
#>
#> [[4]]
#> [1] 4mapply() 在当需要将函数向量化时非常有用,比如:
f <- function(x = 1:3, y) c(x, y)
f(1:3, 1:3)
#> [1] 1 2 3 1 2 3
mapply(f, 1:3, 1:3)
#> [,1] [,2] [,3]
#> [1,] 1 2 3
#> [2,] 1 2 3对于函数 f(),我们对比 f(1:3, 1:3) 和 mapply(f, 1:3, 1:3) 可以很容易的理解 mapply() 可以将两对向量的元素分别传递给 f()。R 函数 Vectorize() 也可以通过向量化自动实现相同的效果:
2.6 如何写 R 函数
什么时候应该写一个 R 函数呢?当你发现你在重复执行一段代码(可能只对其中的参数做了细微改变)时,这时候就应该考虑写 R 函数了!在 R 中的函数是通过 function() 来定义的,它向其它的 R 对象一样,是以对象的形式存在的:
其中 expression 是一段 R 代码,通过参数 arg_1, arg_2, … 来计算函数的输出 value。函数的调用可以用 name(expr_1, expr_2, …)。下面我们来看一个例子:
f <- function(num = 1) {
myname <- "Yanfei \n"
for (i in seq_len(num)) {
cat(myname)
}
myname.length <- nchar(myname) * num
return(myname.length)
}
mynamel <- f(3)
#> Yanfei
#> Yanfei
#> Yanfei
print(mynamel)
#> [1] 24在这个例子中,我们定义了函数 f(),其中
f()有一个参数num,这个函数中设置了默认值num = 1,因此如果我们执行f(),则默认参数num = 1。如果不设置默认值,执行f()就会报错。f()循环打印 “Yanfei”,打印次数是由参数num设定的。函数的输出为打印到控制台中的字符个数。
2.7 如何在 R 中绘图
“The simple graph has brought more information to the data analyst’s mind than any other device.” – John Tukey
在 R 中绘图的方式有很多种,如 R 中的基础绘图(base graphics,基于 graphics 包)、基于 ggplot2 包 (Wickham 2016)、基于 lattice 包 (Sarkar 2008)、基于 plotly 包 (Sievert 2020) 等等。
2.7.1 R 中的基础绘图
R 中的基础做图包含用于绘制最常见图形的函数,如适用于定量数据的条形图、饼图,以及适用于定性数据的直方图、箱线图、折线图、散点图等。 此外,还可以绘制分位数(QQ)图,等高线图、三维图等。 graphics 包中包含的常用的绘图函数如表 2.1 所示 (Adler 2010)。
| R 函数 | 描述 |
|---|---|
barplot() |
条形图 |
pie() |
饼图 |
hist() |
直方图 |
density() |
核密度图 |
boxplot() |
箱线图 |
plot() |
散点图 |
smoothScatter() |
带有平滑密度的散点图 |
pairs() |
两两散点图 |
image() |
图像 |
contour() |
等高线图 |
persp() |
三维图 |
条形图
条形图通常用于展示定性变量。以 2019 年中国居民人均消费支出(来源:国家统计局网站)为例:
expense <- data.frame(
消费 = c(6084, 5055, 2862, 2513, 1902, 1338, 1281, 524),
类别 = c("食品烟酒", "居住",
"交通通信", "教育文化娱乐",
"医疗保健", "衣着",
"生活用品及服务", "其他用品及服务"))
par(family = if (knitr::is_latex_output()) "GB1" else "SimHei")
barplot(height = expense$消费,
main = "2019 年中国居民人均消费支出",
ylab = "消费(元)",
names.arg = expense$类别,
border = 'darkblue',
col = "orange3",
las = 2)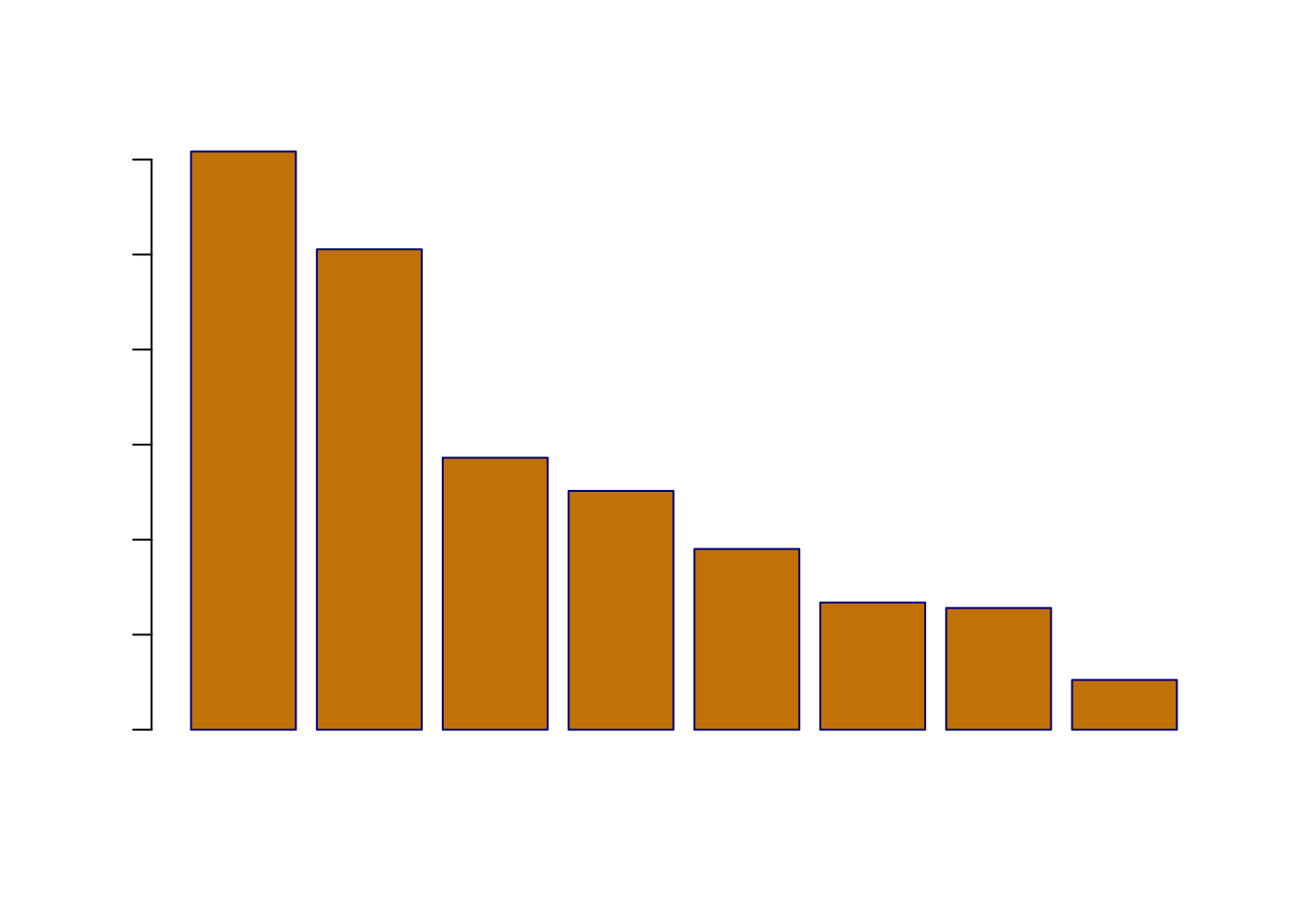
饼图
饼图适于表示数据的结构性特征。再以 2019 年中国居民人均消费支出数据为例,我们可以通过饼图来了解消费结构。
par(family = if (knitr::is_latex_output()) "GB1" else "SimHei")
pie(expense$消费,
labels = expense$类别,
main = "2019 年中国居民人均消费支出结构")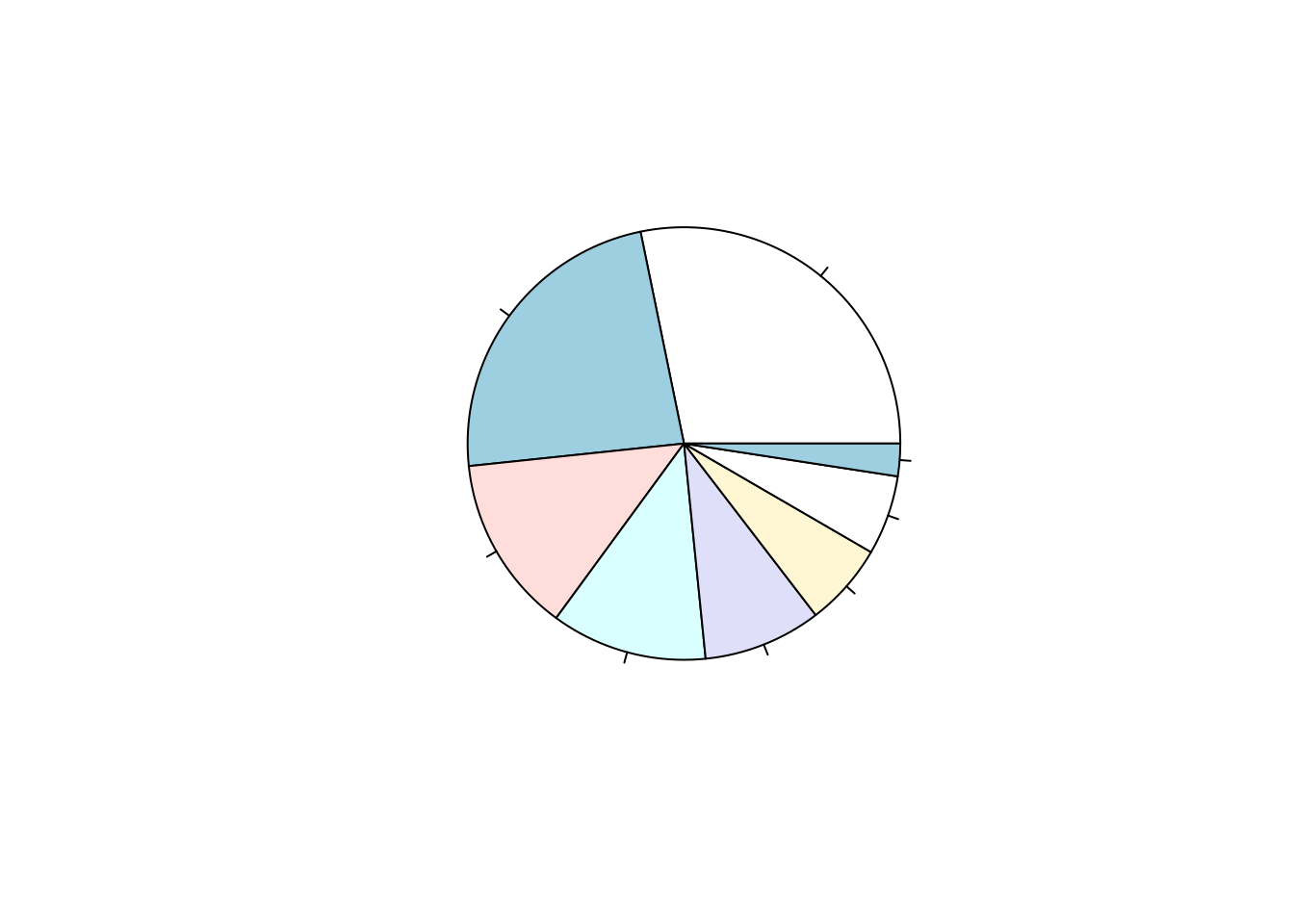
直方图
以下为某个班级 50 名同学的《统计计算》课程考试成绩。
#> [1] 100 84 88 83 72 79 87 91 80 74 89
#> [12] 83 91 94 95 96 74 88 96 94 97 94
#> [23] 78 98 72 77 95 76 79 78 99 88 73
#> [34] 83 86 80 76 90 81 84 79 82 76 78
#> [45] 78 79 92 96 97 90从这组数据中我们可以了解这个班级同学的《统计计算》成绩分布情况,比如我们可以统计出成绩属于每个区间段的学生个数(如表 2.2 所示)。
| 成绩区间 | 学生数 |
|---|---|
| (70, 75] | 5 |
| (75, 80] | 14 |
| (80, 85] | 7 |
| (85, 90] | 8 |
| (90, 95] | 8 |
| (95, 100] | 8 |
直方图可以以图的形式展示以上分布。
par(family = if (knitr::is_latex_output()) "GB1" else "SimHei")
hist(grades, breaks = 4, col = 'orange3', border='darkblue',
main = '某班级《统计计算》考试成绩直方图',
xlab = '成绩', ylab = '频数')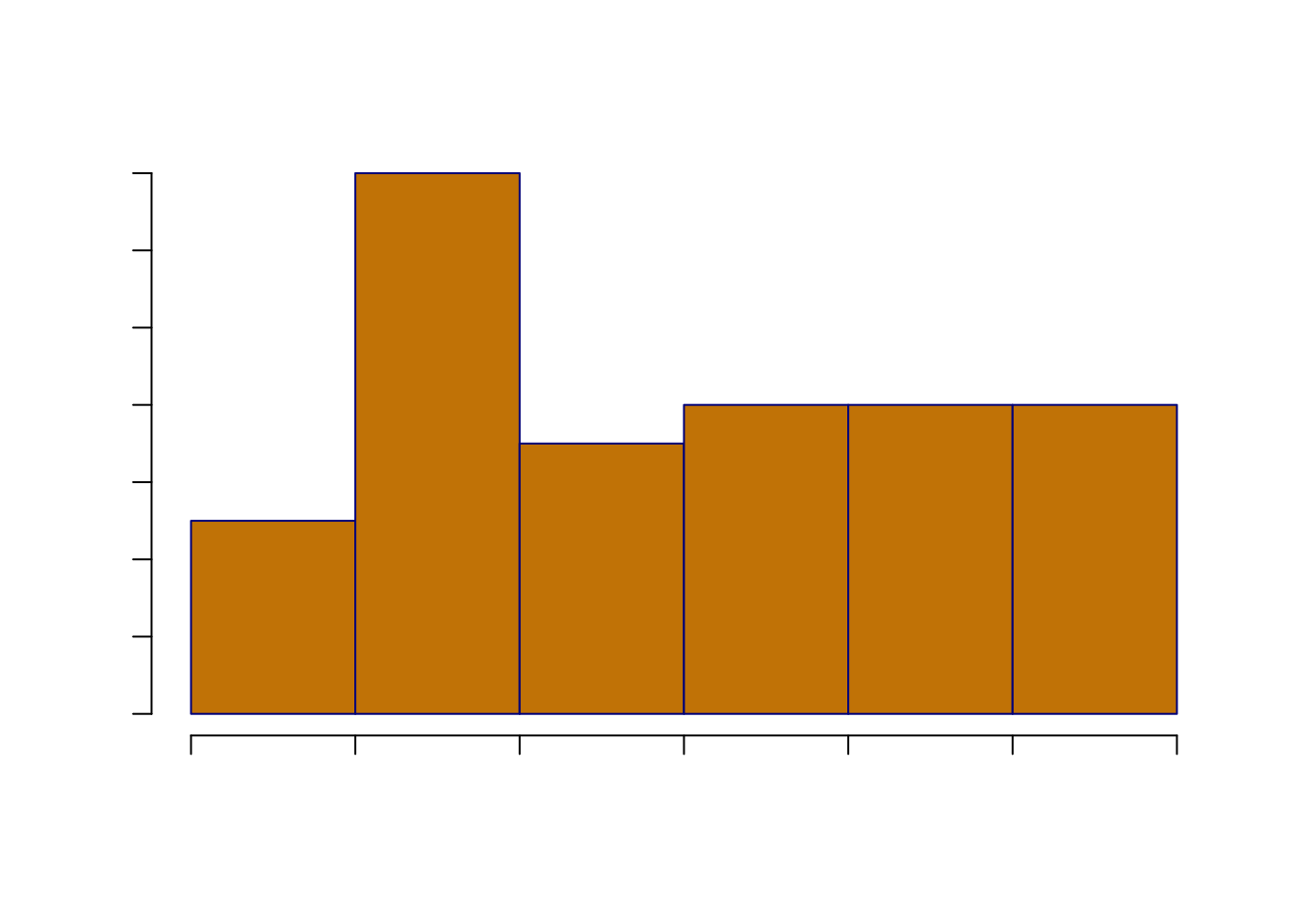
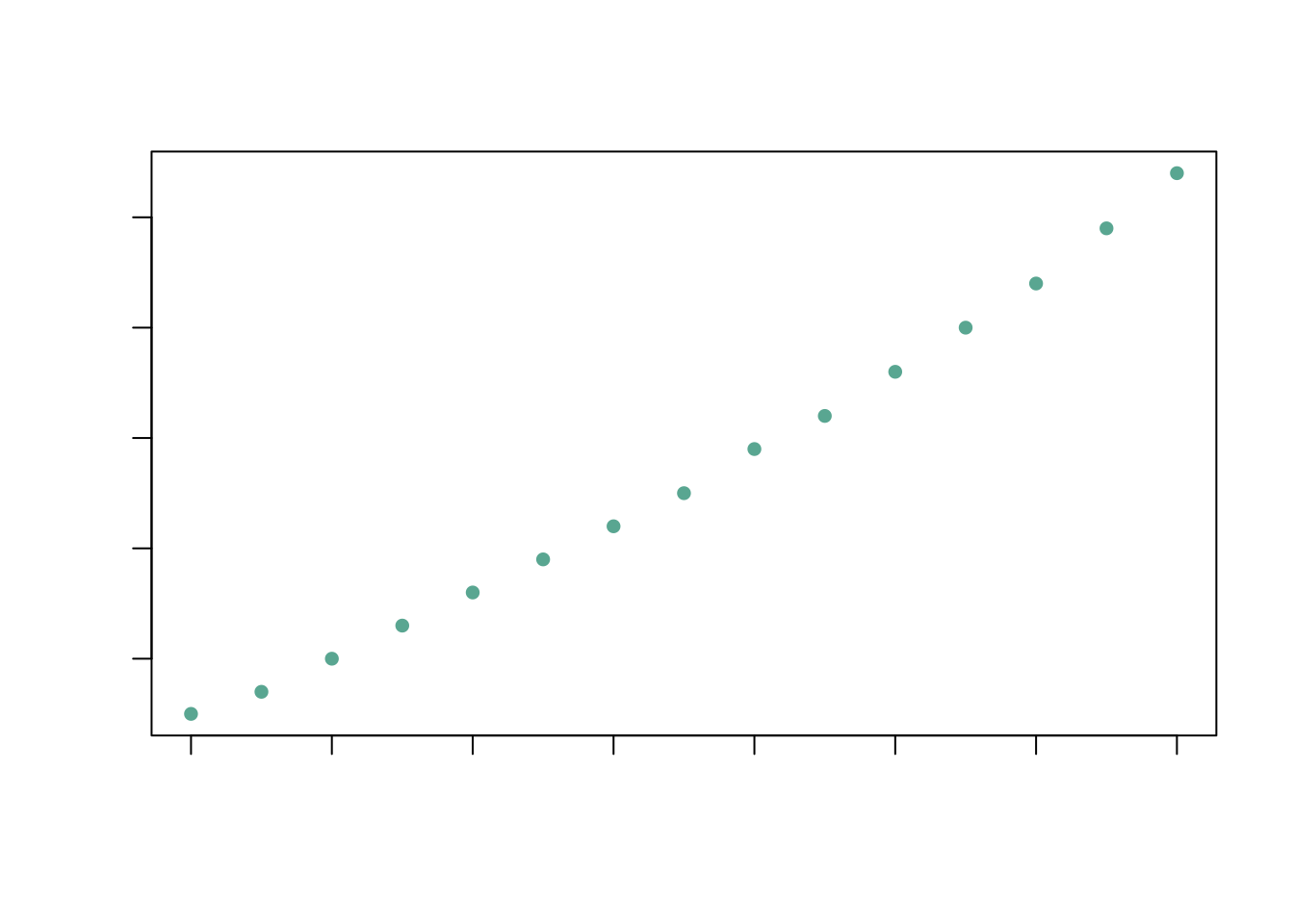
箱线图
箱线图可以基于一组数据的四分位数(quartiles)来展示数据分布。一个一般的箱线图可以展示:
- “最小值”:去除异常值外的最小值。
- “最大值”:去除异常值外的最大值。
- 中位数:一组数据中位于中间位置的数,也叫第二四分位数(the second quartiile,简称 \(Q_2\))或第50百分位数(50th percentile)。
- 第一四分位数(the first quartiile,简称 \(Q_1\)),也叫第25百分位数(25th percentile)。
- 第三四分位数(the third quartiile,简称 \(Q_3\)),也叫第75百分位数(75th percentile)。
其中“最小值”和“最大值”通过四分位距(Interquartile range,简称IQR = \(Q_3\) - \(Q_1\))来确定:
\[ \begin{aligned} “最小值” &= Q_1- 1.5*\mathrm{IQR}, \\ “最大值” & = Q3+ 1.5*\mathrm{IQR}. \end{aligned} \]
下面我们通过箱线图来展示《统计计算》成绩分布情况。
par(family = if (knitr::is_latex_output()) "GB1" else "SimHei")
boxplot(grades, col = 'orange3', main = '统计学考试成绩箱线图')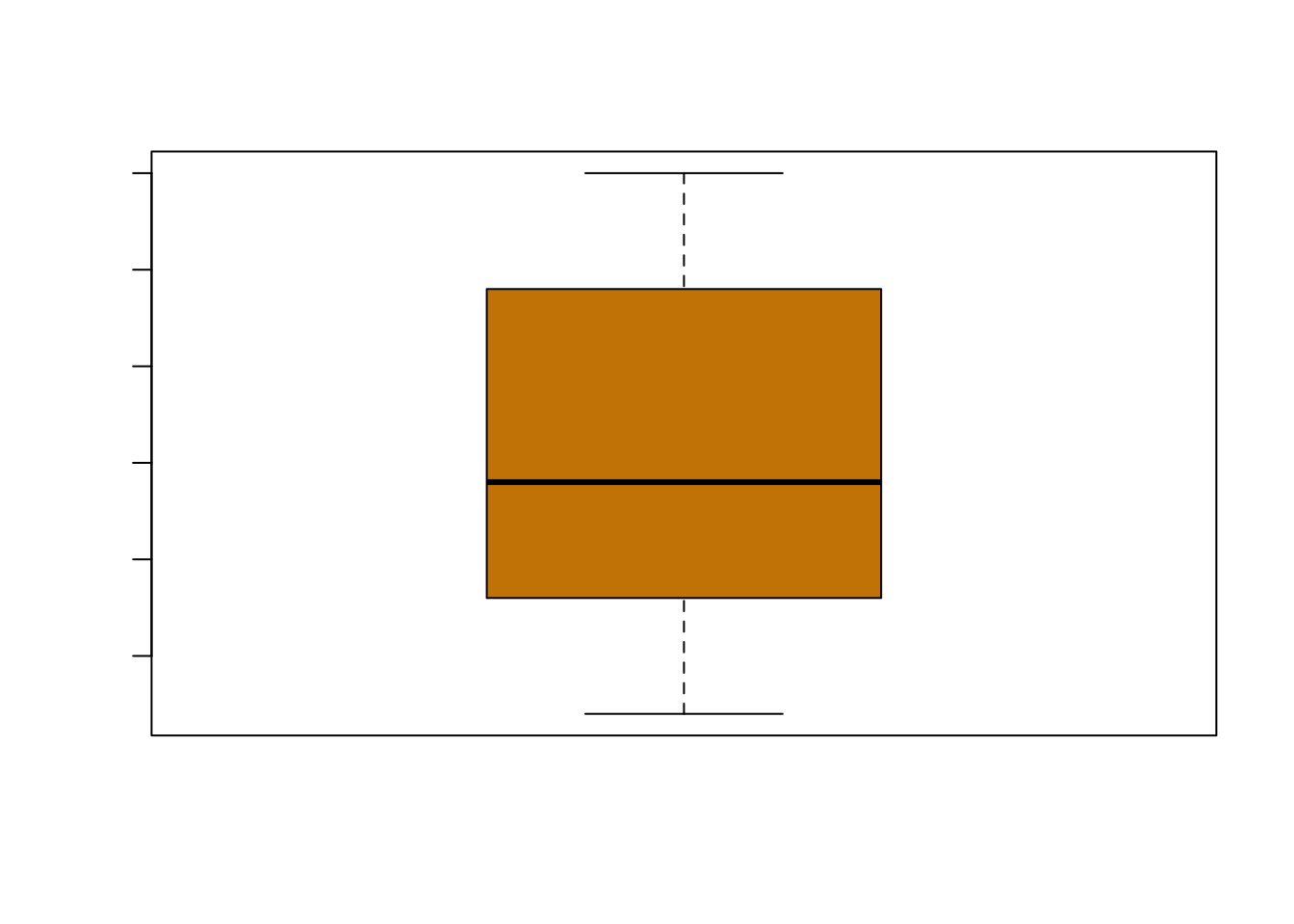
2.7.2 ggplot2
ggplot2是 R 中最美观的绘图框架之一,它有一个精心设计的绘图结构。ggplot2 绘图是基于图形语法(The Grammar of Graphics)的, 这导致它与基础绘图方式非常不同:
ggplot2绘图所需的所有数据通常包含在数据框中,数据框可以通过ggplot()或者对应的 geoms 来提供(稍后会有更多细节)。- 您可以通过向使用
ggplot()创建的现有绘图添加更多层(和主题)来不断增强绘图。
一般来讲,ggplot2 绘图可以遵循以下步骤。
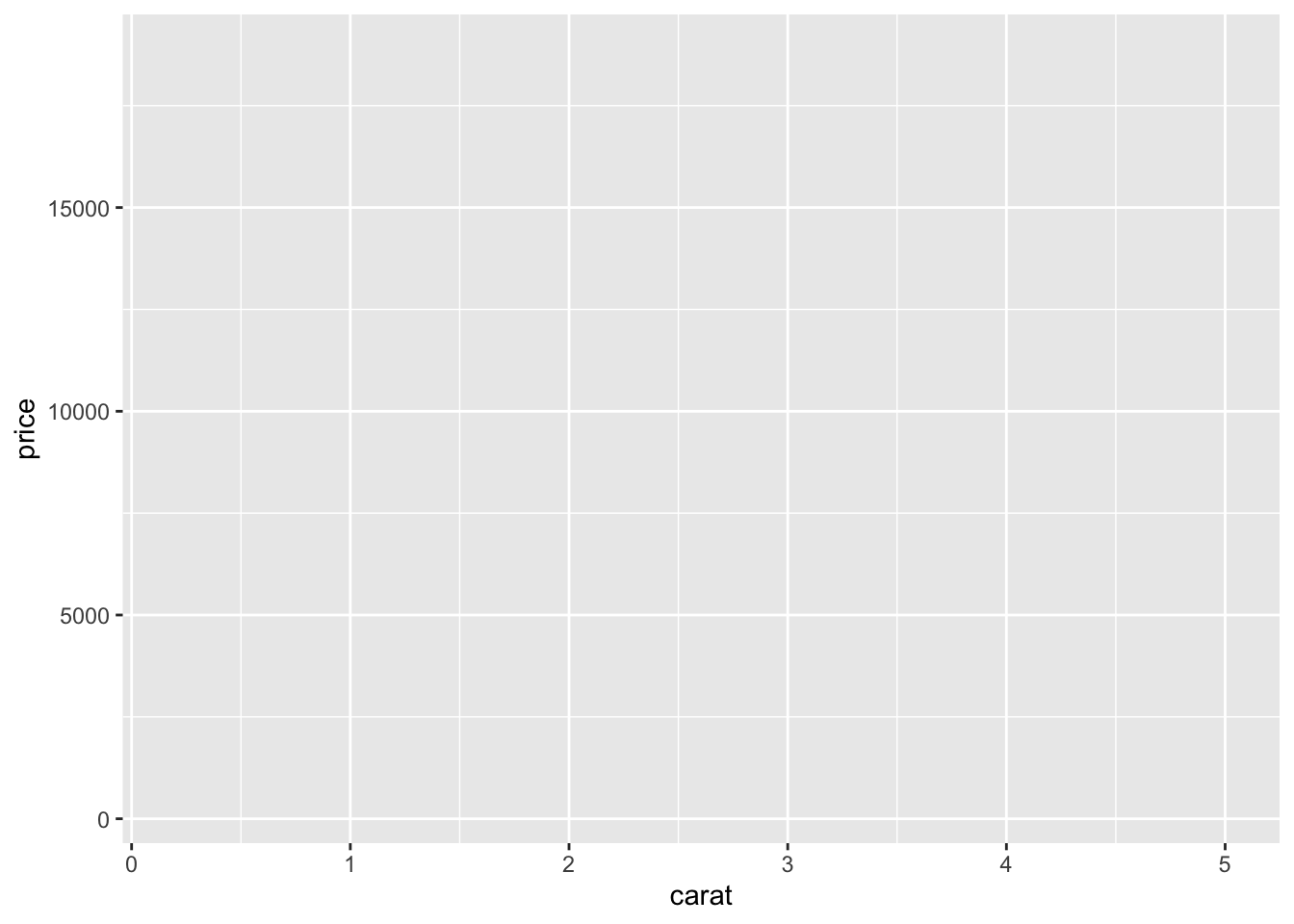
第一步: 初始化
初始化的主要目的是告诉 ggplot2 你所要绘制的数据集。在 ggplot2 绘图框架下,可以通过 ggplot(df) 来提供所要绘制的数据集 df,其中 df 中应该包含绘图所需要的所有变量。这和基础绘图不同,因为 ggplot() 处理的是数据框,而不是单个向量。

你可以通过参数 aes() 在你的 ggplot 图中加入任何美学特征(aesthetics)。比如,你可以通过指定 \(X\) 轴和 \(Y\) 轴来锁定所有图层的变量。
还可以设置颜色、形状等随之变化的变量,如:
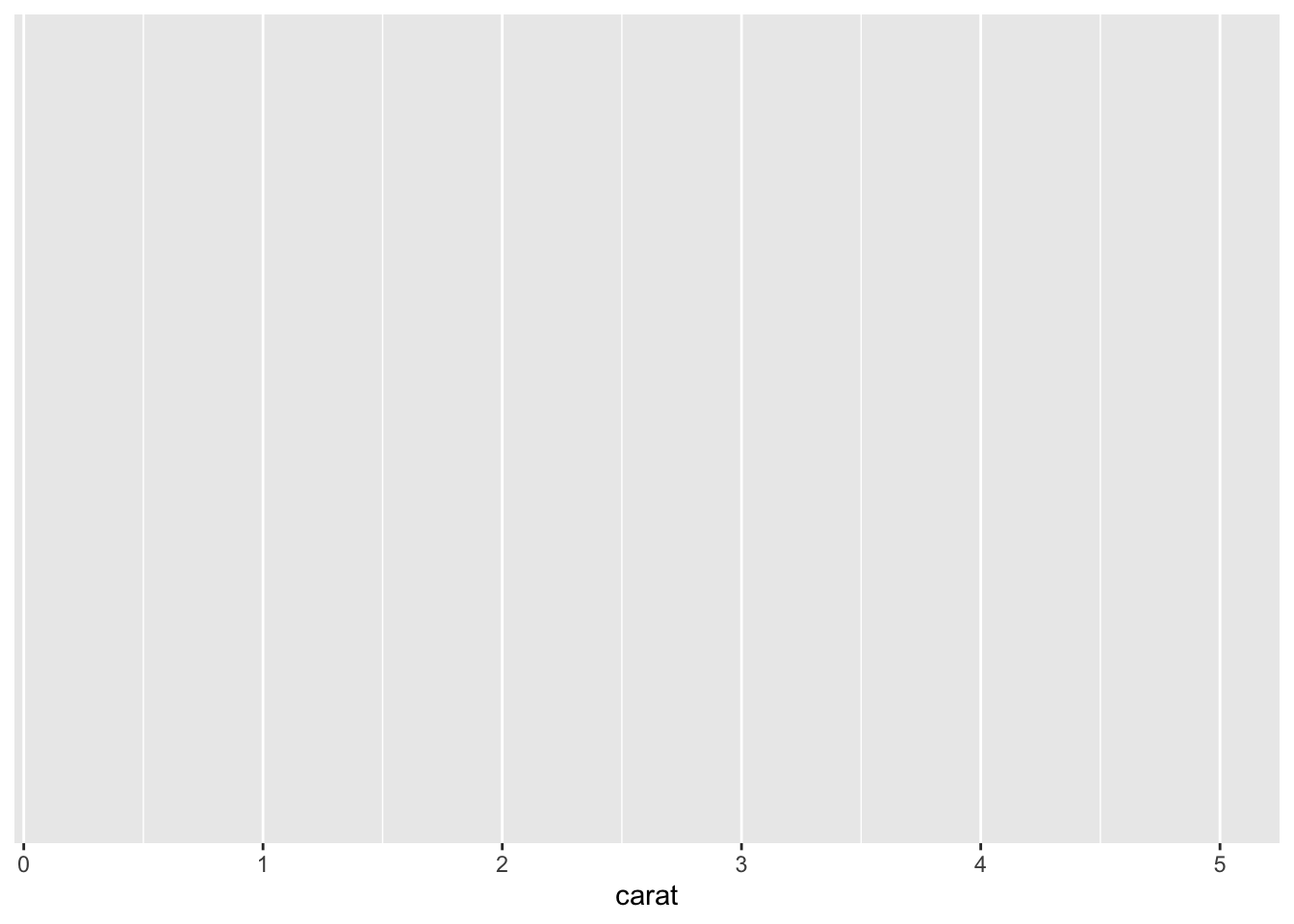 在这种情况下,
在这种情况下,cut 变量的每一个类别会展现成不同的颜色。如果你想固定颜色或者大小,需要在 aes() 参数外设置,如:
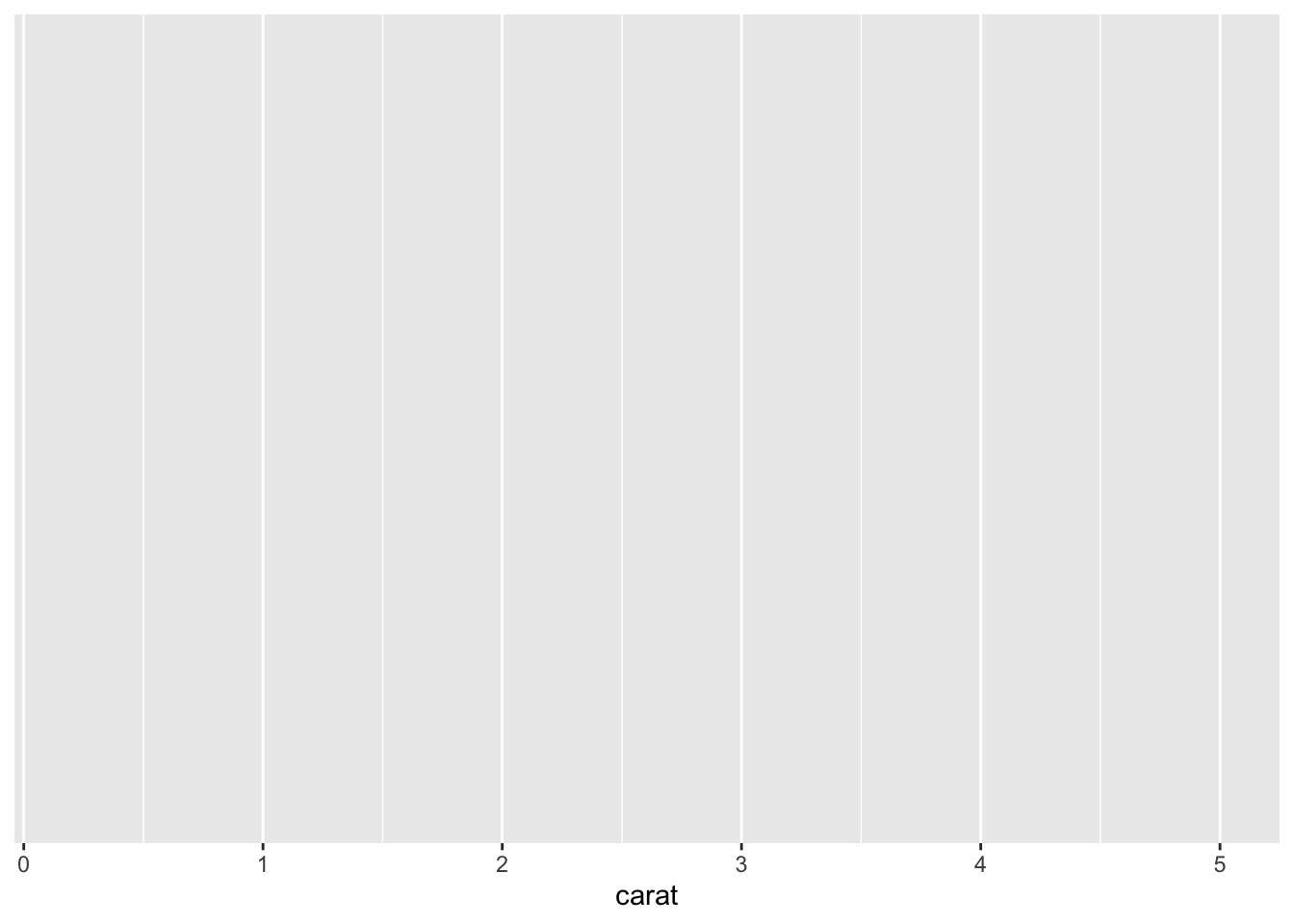
通过上面几个例子,你会发现,它们只是绘制了一个空的 ggplot,即使 aes() 指定了 \(X\) 轴和 \(Y\) 轴,图中也没有点或者线。这是因为你只告诉 ggplot() 要使用什么数据集,它并不认为你是要绘制散点图或折线图,X和Y轴应该使用哪些列。
第二步: 加图层
ggplot2 中的图层(layers)也叫 “geoms” 。初始化之后,就可以一层一层的加图层了。比如我们可以通过 geom_point() 加入散点图层。
aes() 也可以放在图层 geom_point() 里。
在此基础上还可以加入多个图层,如:
也可以根据 cut 变量展现不同类别的 diamonds。
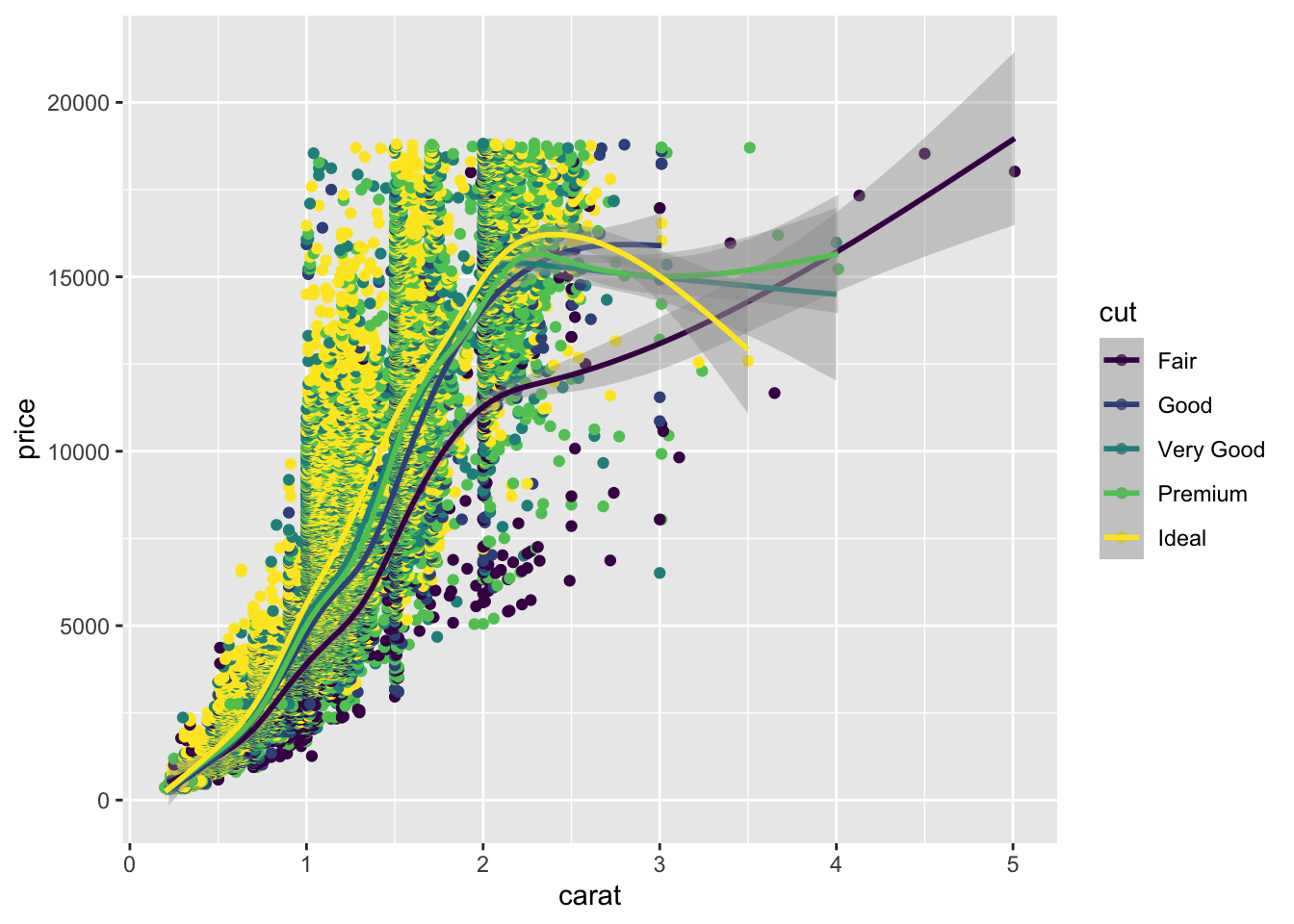
不同类别的 diamonds 可以通过不同的形状来展示。
ggplot(diamonds, aes(x = carat, y = price, color = cut, shape = color)) +
geom_point() +
geom_smooth()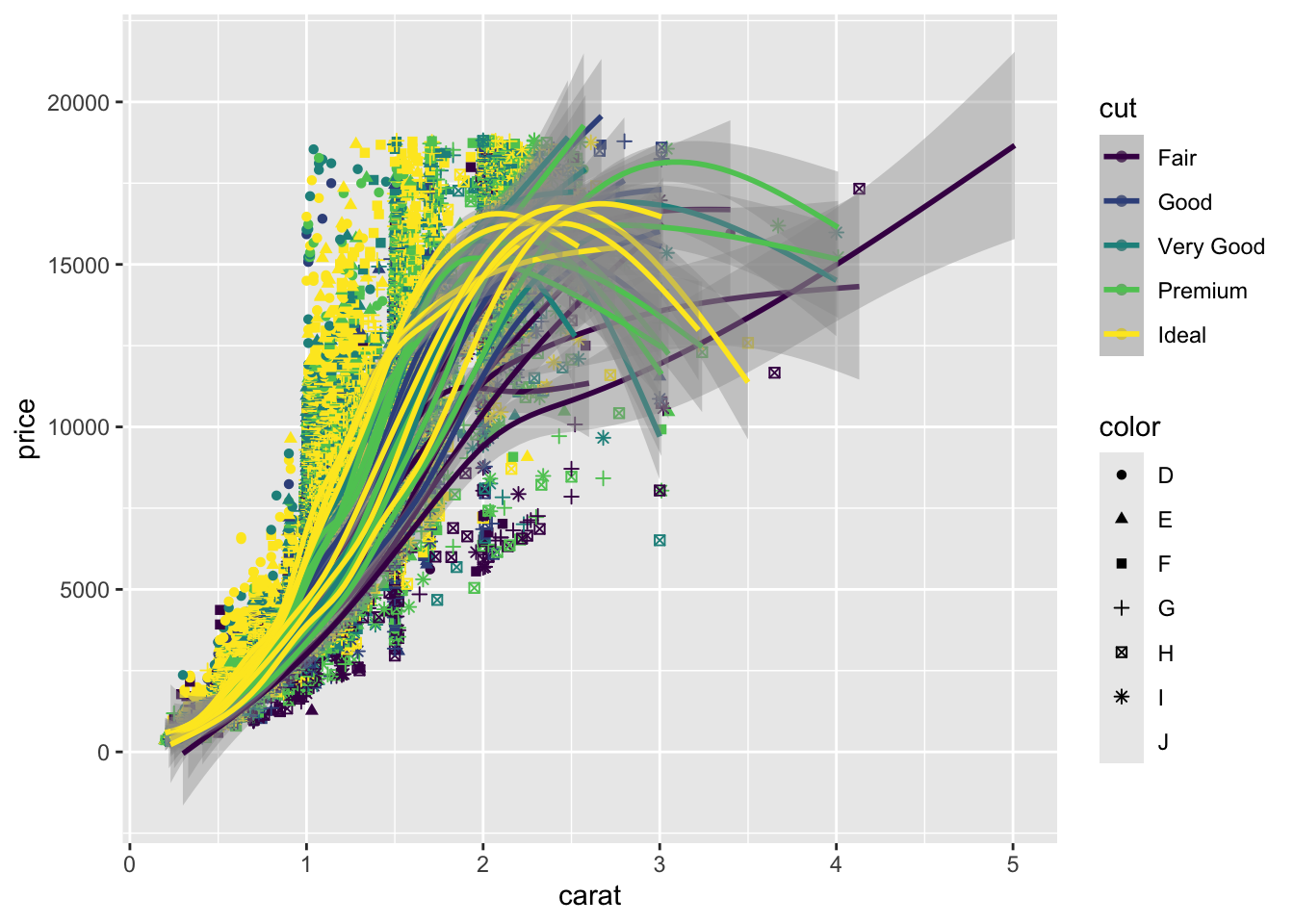
第三步: 加标签
现在我们已经完成了绘图的主要部分,如果你想修改图的标签(如标题、\(X\) 轴或 \(Y\) 轴标签等),可以通过 labs() 来完成。
ggplot(diamonds) +
geom_point(aes(x = carat, y = price, color = cut)) +
labs(title = 'Scatterplot of carat and price',
x = 'Carat', y = 'Price')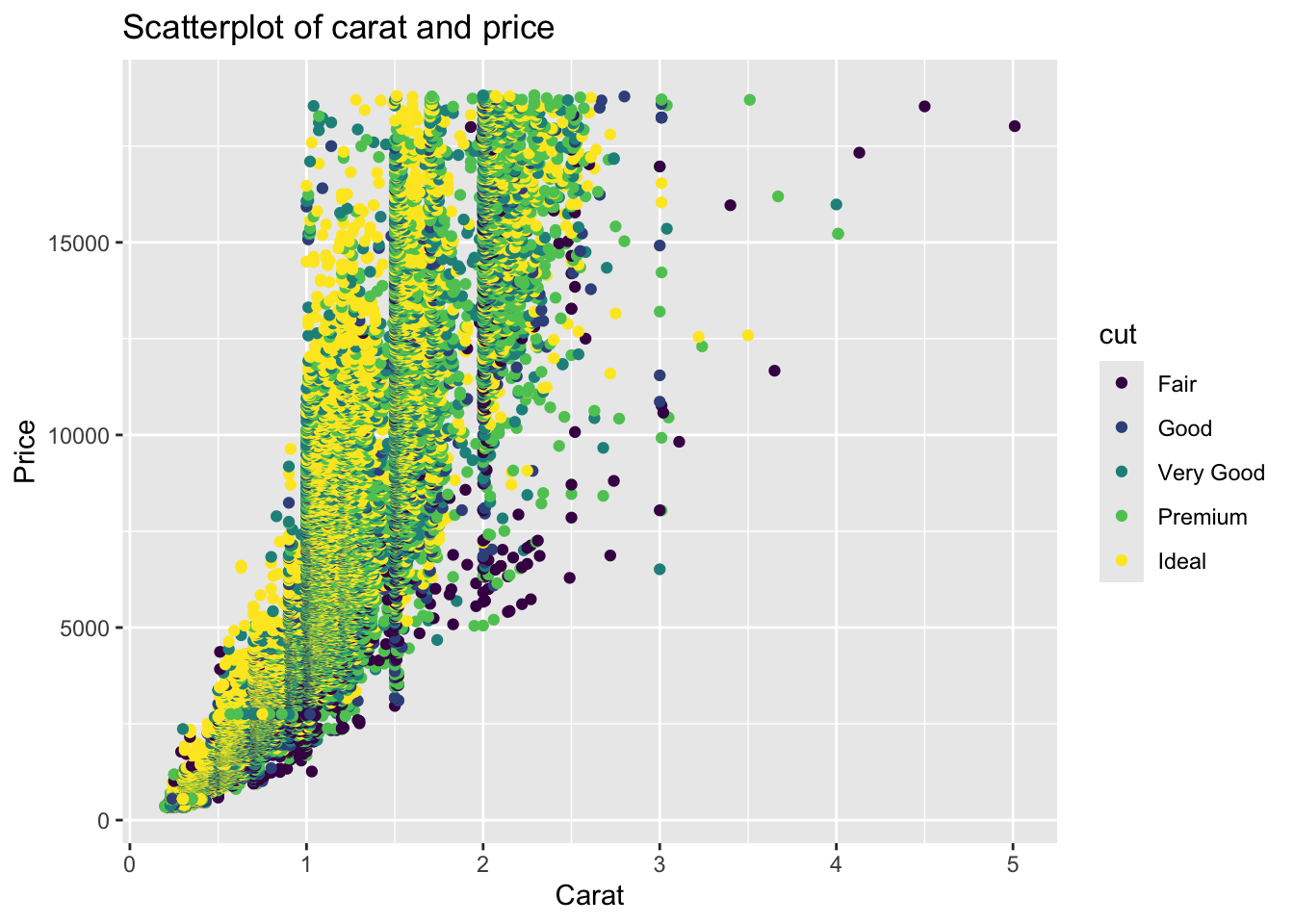
第四步: 修改主题
也许有时候你需要修改图的主题,如调整标题字体、标签字体、修改图例标题等。调整标题字体、标签字体等可以通过 theme() 来完成。
p <- ggplot(diamonds) +
geom_point(aes(x = carat, y = price, color = cut)) +
labs(title = 'Scatterplot of carat and price',
x = 'Carat', y = 'Price')
p1 <- p + theme(plot.title = element_text(size=20, face="bold"),
axis.text.x = element_text(size=15),
axis.text.y = element_text(size=15),
axis.title.x = element_text(size=20),
axis.title.y = element_text(size=20))
p1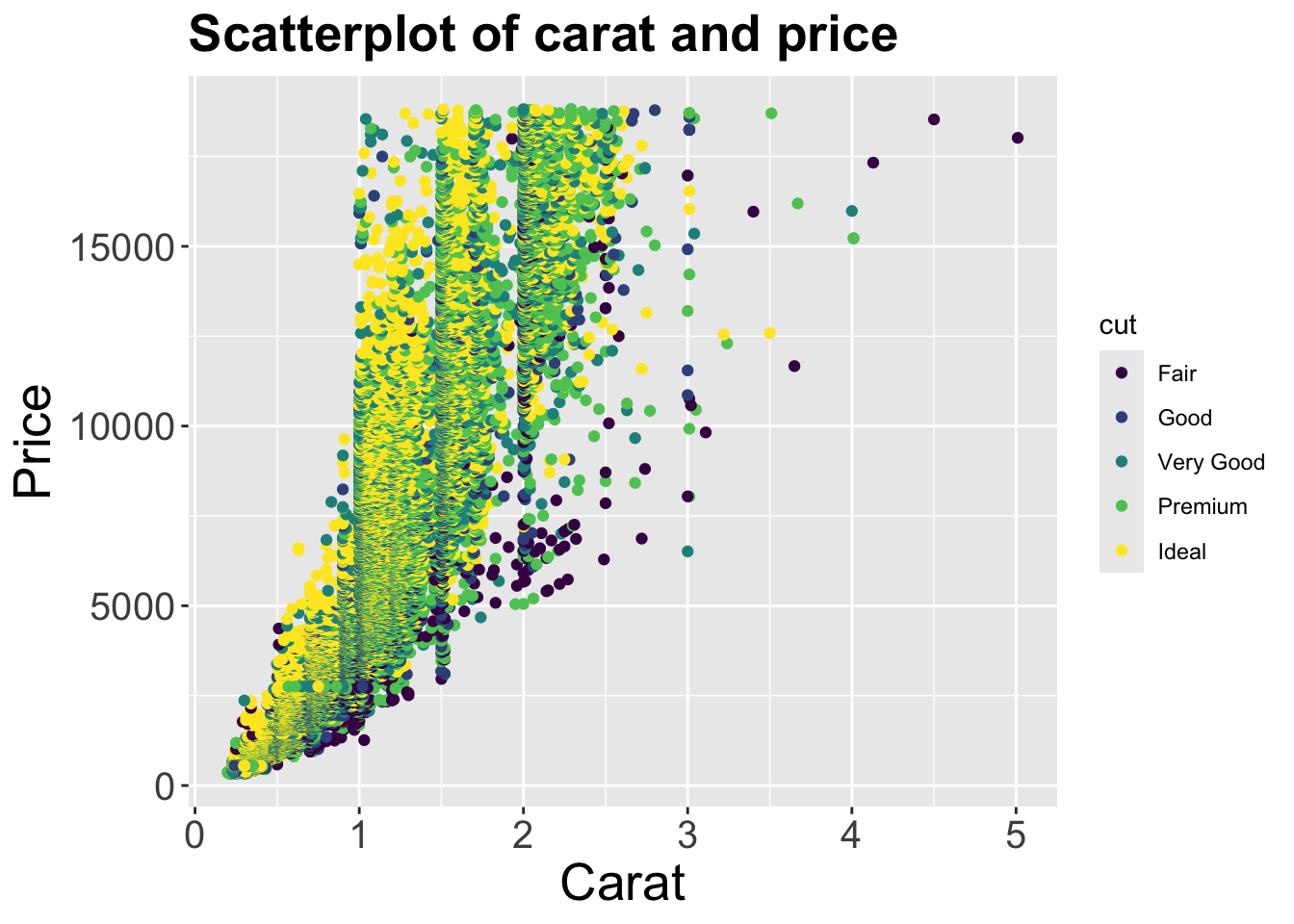
如果你想调整图例标题,则取决于图例所对应的属性,如果是 color,则可以使用 scale_color_discrete() 来调整:
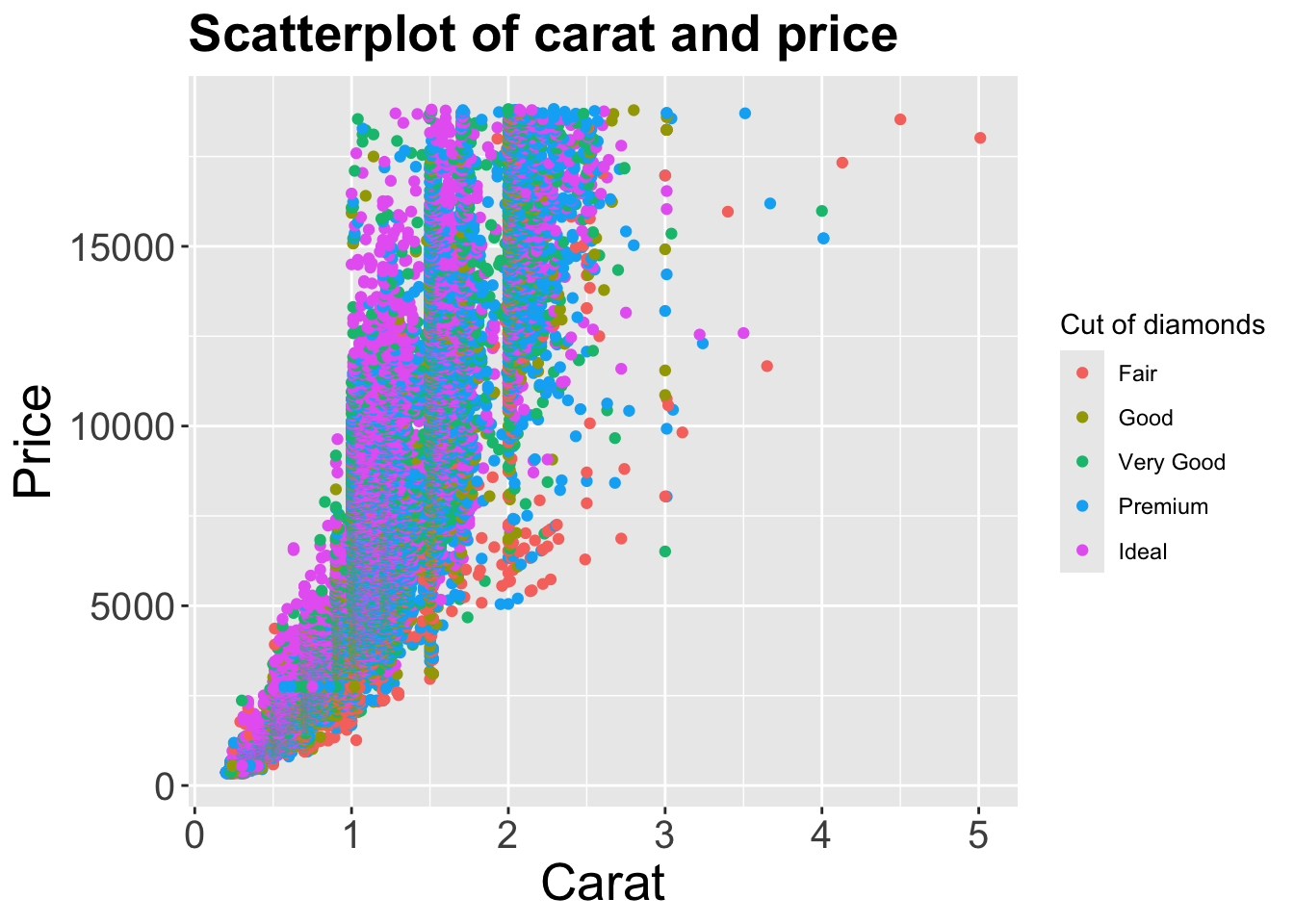 如果图例所对应的属性是
如果图例所对应的属性是 shape,则可以使用 scale_shape_discrete() 来调整。
2.8 有关 R 的学习资源
如果你从来没有用过 R,可以学习 DataCamp 的免费在线课程 “R 入门”,这个课程不包括统计计算的内容,它只是教你 R 语言的基础。DataCamp 上还有 R 相关的其他课程。 此外,Coursera 上的 R 编程课程也非常值得推荐。