第 12 章 MCMC 方法基础
第 10 章介绍的 Monte Carlo 方法有一个隐含前提:我们能够从目标分布中独立抽样。这个前提在很多统计问题中并不容易满足。直接抽样可能找不到反函数;拒绝抽样和重要性抽样需要一个与目标分布足够接近的提议分布;一旦参数维度升高,构造这样的提议分布会迅速变难。
MCMC(Markov chain Monte Carlo,马尔科夫链 Monte Carlo)的想法是换一个角度:不再要求每次都从固定分布中独立抽样,而是构造一条会逐步移动的随机链。当前样本决定下一步往哪里试探;如果这条链的长期分布正好是目标分布,那么运行足够久之后,链上的样本就可以用来近似目标分布下的积分、概率和分位数。
在贝叶斯统计中,我们经常希望从后验分布
\[ p(\theta\mid y)\propto p(y\mid\theta)p(\theta) \]
中抽样。右边的似然和先验通常容易计算,但归一化常数
\[ p(y)=\int p(y\mid\theta)p(\theta)\,d\theta \]
可能很难计算。MCMC 的关键优势是:许多算法只需要后验密度的比例,而不需要知道这个归一化常数。
本章先介绍马尔科夫链的基本概念,然后讲 Metropolis–Hastings、随机游走 Metropolis、Gibbs 抽样和Metropolis within Gibbs。最后用诊断指标说明为什么 MCMC 输出不能只看“抽了多少次”。
12.1 为什么需要 MCMC
设目标分布为 \(\pi(x)\),我们希望计算
\[ E_\pi\{h(X)\}=\int h(x)\pi(x)\,dx. \]
如果能够独立生成 \(X_1,\ldots,X_M\sim\pi\),则可以用
\[ \frac{1}{M}\sum_{m=1}^M h(X_m) \]
近似这个期望。独立 Monte Carlo 的困难在于:在很多实际模型中,我们只能计算 \(\tilde\pi(x)\),并且知道
\[ \pi(x)=\frac{\tilde\pi(x)}{\int \tilde\pi(u)\,du}. \]
分母常常不可得。拒绝抽样和重要性抽样也可以利用未归一化密度,但它们对提议分布要求较高:若提议分布的质量集中在目标分布很少出现的区域,模拟效率会很低;若目标分布有多个峰或强相关结构,提议分布更难设计。
MCMC 不要求每个样本彼此独立。它让提议分布依赖当前状态,例如从当前位置附近提出一个候选点。这样即使我们没有一个全局上完美的提议分布,也可以通过局部移动逐步探索目标分布。
独立 Monte Carlo 和 MCMC 的差异可以粗略概括如下:
| 方法 | 样本关系 | 主要难点 | 常见用途 |
|---|---|---|---|
| 直接抽样 | 独立 | 需要能从目标分布抽样 | 标准分布、共轭模型 |
| 拒绝抽样 | 独立 | 需要包住目标分布的提议分布 | 低维分布 |
| 重要性抽样 | 独立但带权重 | 权重可能极不稳定 | 低维积分、方差缩减 |
| MCMC | 通常相关 | 需要检查收敛和混合 | 高维后验、复杂模型 |
12.2 马尔科夫链的基本概念
马尔科夫链是一列随机变量
\[ X_0,X_1,X_2,\ldots \]
满足如下性质:给定当前状态 \(X_t\) 后,下一状态 \(X_{t+1}\) 的条件分布不再依赖更早历史,即
\[ P(X_{t+1}\in A\mid X_t,X_{t-1},\ldots,X_0) = P(X_{t+1}\in A\mid X_t). \]
MCMC 的目标不是“让样本有马尔科夫性”本身,而是构造一条马尔科夫链,使它的平稳分布为目标分布\(\pi(x)\)。直观地说,如果链已经运行足够久,它在不同区域停留的相对频率会接近 \(\pi(x)\) 给出的概率。
这也带来两个实践问题:
- 早期样本可能仍受初始值影响,因此常舍弃一段 burn-in;
- MCMC 样本通常自相关,样本数相同并不意味着信息量相同。
下面的算法和诊断都围绕这两个问题展开。
12.3 Metropolis–Hastings 算法
Metropolis–Hastings 算法是最基本的 MCMC 算法之一。设目标密度为 \(\pi(x)\),可以只知道它的比例。从当前状态 \(x_t\) 出发,先从提议分布 \(q(x^\ast\mid x_t)\) 中生成候选值 \(x^\ast\),再以一定概率接受它。
接受概率为
\[ \alpha = \min\left\{ 1, \frac{\pi(x^\ast)q(x_t\mid x^\ast)} {\pi(x_t)q(x^\ast\mid x_t)} \right\}. \]
若接受,则 \(x_{t+1}=x^\ast\);若拒绝,则 \(x_{t+1}=x_t\)。注意,即使候选值被拒绝,也必须把当前值再次记录为一次样本。这些“重复值”正是算法维持目标分布所需要的一部分。
Metropolis–Hastings 算法
- 给定初始值 \(x_0\)。
- 对 \(t=0,1,\ldots,T-1\):从 \(q(x^\ast\mid x_t)\) 中生成候选值 \(x^\ast\);计算接受概率
\[ \alpha = \min\left\{ 1, \frac{\pi(x^\ast)q(x_t\mid x^\ast)} {\pi(x_t)q(x^\ast\mid x_t)} \right\}; \]
生成 \(U\sim U(0,1)\),若 \(U\leq\alpha\),令 \(x_{t+1}=x^\ast\),否则令 \(x_{t+1}=x_t\)。
实际编程时,通常在对数尺度上计算接受比:
\[ \log\alpha = \min\left\{ 0, \log\pi(x^\ast)-\log\pi(x_t) +\log q(x_t\mid x^\ast)-\log q(x^\ast\mid x_t) \right\}. \]
这样可以避免很多概率密度相乘导致的上溢和下溢。在贝叶斯后验中,不依赖 \(\theta\) 的归一化常数会在比值中相互抵消:
\[ \frac{p(y\mid\theta^\ast)p(\theta^\ast)/p(y)} {p(y\mid\theta_t)p(\theta_t)/p(y)} = \frac{p(y\mid\theta^\ast)p(\theta^\ast)} {p(y\mid\theta_t)p(\theta_t)}. \]
这就是 MCMC 特别适合贝叶斯计算的原因。
12.4 随机游走 Metropolis
若提议分布为
\[ x^\ast=x_t+\varepsilon,\quad \varepsilon\sim g(\varepsilon), \]
且 \(g(\varepsilon)=g(-\varepsilon)\),则
\[ q(x^\ast\mid x_t)=q(x_t\mid x^\ast). \]
接受概率简化为
\[ \alpha=\min\left\{1,\frac{\pi(x^\ast)}{\pi(x_t)}\right\}. \]
这就是随机游走 Metropolis 算法。提议步长很重要:步长太小,链每次都只挪动一点;步长太大,候选值经常落在低密度区域而被拒绝。
下面从一个双峰混合正态分布中抽样。这个例子展示 MCMC 可以只利用目标密度的相对大小。
set.seed(2026)
log_target_mix <- function(x) {
log(0.35 * dnorm(x, mean = -2, sd = 0.7) +
0.65 * dnorm(x, mean = 2, sd = 1))
}
rw_metropolis <- function(x0, n_iter, proposal_sd, log_target) {
x <- numeric(n_iter)
x[1] <- x0
accepted <- logical(n_iter)
for (t in 2:n_iter) {
proposal <- rnorm(1, mean = x[t - 1], sd = proposal_sd)
log_alpha <- log_target(proposal) - log_target(x[t - 1])
if (log(runif(1)) < log_alpha) {
x[t] <- proposal
accepted[t] <- TRUE
} else {
x[t] <- x[t - 1]
}
}
list(samples = x, accept_rate = mean(accepted[-1]))
}
fit_mix <- rw_metropolis(
x0 = -8,
n_iter = 10000,
proposal_sd = 1.2,
log_target = log_target_mix
)
burn <- 2000
post_mix <- fit_mix$samples[(burn + 1):length(fit_mix$samples)]
c(accept_rate = fit_mix$accept_rate,
posterior_mean = mean(post_mix),
posterior_sd = sd(post_mix))
#> accept_rate posterior_mean posterior_sd
#> 0.6656 0.7546 2.0587par(mfrow = c(1, 2))
plot(fit_mix$samples, type = "l", xlab = "Iteration", ylab = "x",
main = "Trace plot")
abline(v = burn, col = "gray50", lty = 2)
hist(post_mix, breaks = 40, freq = FALSE, main = "Posterior samples",
xlab = "x", border = "white", col = "gray85")
curve(exp(log_target_mix(x)), from = -5, to = 5, add = TRUE,
col = "red", lwd = 2)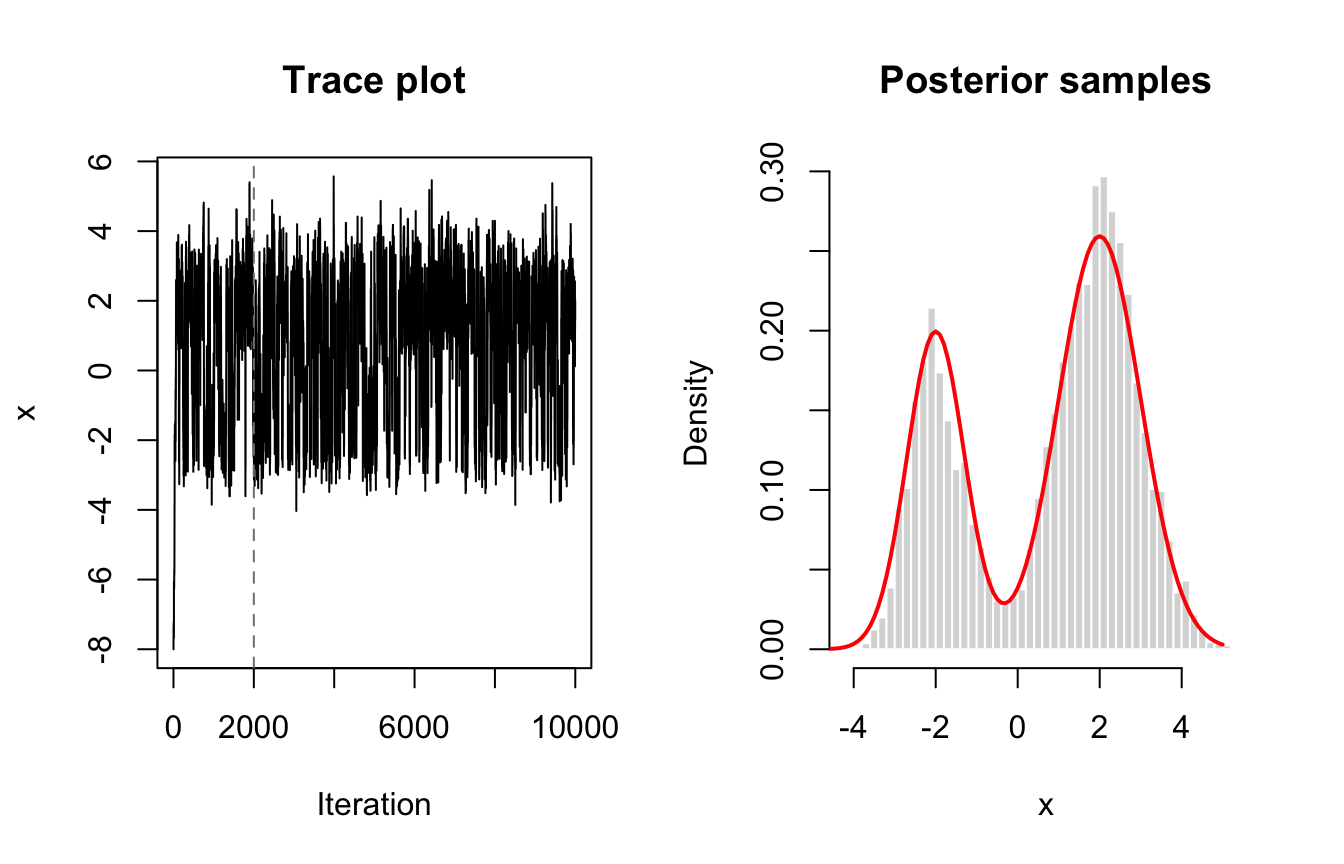
图12.1: 随机游走 Metropolis 的轨迹图与抽样分布。
图中的竖线之前是 burn-in。这个例子中从非常偏的初始值 \(x_0=-8\) 出发,链仍能逐渐进入目标分布的主要区域。但这并不意味着任何 MCMC 输出都可靠。提议步长如果选择不当,链会移动很慢或频繁拒绝。
12.5 提议步长、接受率与自相关
下面比较三个随机游走步长。为了让比较集中,我们使用同一个目标分布和同一个初始值。
mcmc_ess <- function(x, max_lag = NULL) {
x <- as.numeric(x)
n <- length(x)
if (is.null(max_lag)) {
max_lag <- min(n - 1, 1000)
}
ac <- as.numeric(acf(x, plot = FALSE, lag.max = max_lag)$acf)[-1]
first_negative <- which(ac < 0)[1]
if (!is.na(first_negative)) {
ac <- ac[seq_len(first_negative - 1)]
}
tau <- 1 + 2 * sum(ac)
n / max(tau, 1)
}
proposal_sd <- c(0.1, 1.2, 10)
names(proposal_sd) <- paste0("sd = ", proposal_sd)
fits_sd <- lapply(
proposal_sd,
function(s) rw_metropolis(-8, 10000, s, log_target_mix)
)
post_sd <- lapply(fits_sd, function(f) f$samples[(burn + 1):length(f$samples)])
tuning_summary <- data.frame(
proposal_sd = proposal_sd,
accept_rate = sapply(fits_sd, `[[`, "accept_rate"),
mean = sapply(post_sd, mean),
ess = sapply(post_sd, mcmc_ess)
)
knitr::kable(tuning_summary, row.names = FALSE, digits = 3)| proposal_sd | accept_rate | mean | ess |
|---|---|---|---|
| 0.1 | 0.957 | 0.111 | 5.219 |
| 1.2 | 0.659 | 0.599 | 242.917 |
| 10.0 | 0.198 | 0.753 | 766.341 |
par(mfrow = c(3, 1), mar = c(3.5, 4, 2, 1))
for (i in seq_along(fits_sd)) {
plot(fits_sd[[i]]$samples[1:2500], type = "l", xlab = "Iteration",
ylab = "x", main = names(proposal_sd)[i])
}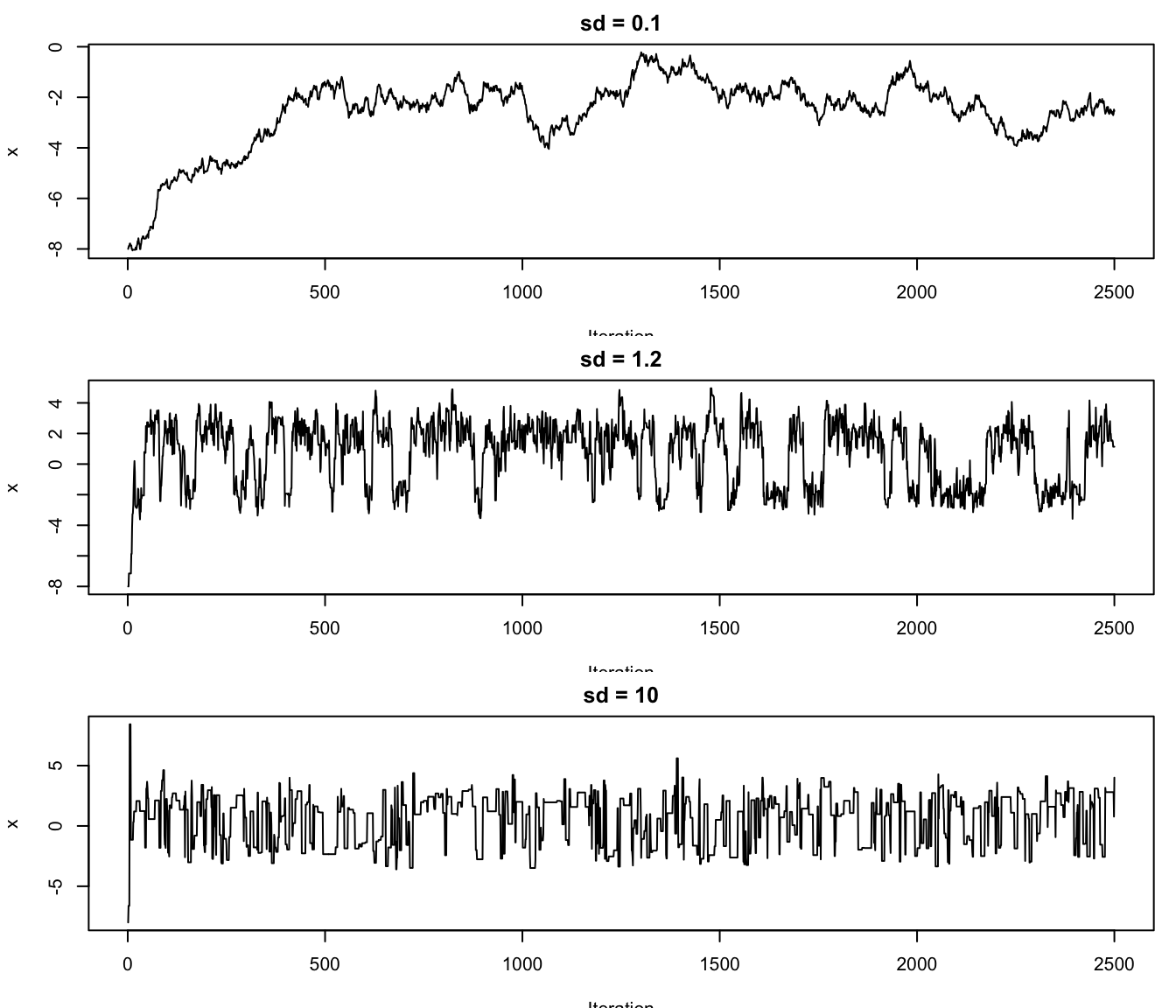
图12.2: 不同提议步长下的 MCMC 轨迹。
par(mfrow = c(1, 3), mar = c(4, 4, 2, 1))
for (i in seq_along(post_sd)) {
acf(post_sd[[i]], main = names(proposal_sd)[i])
}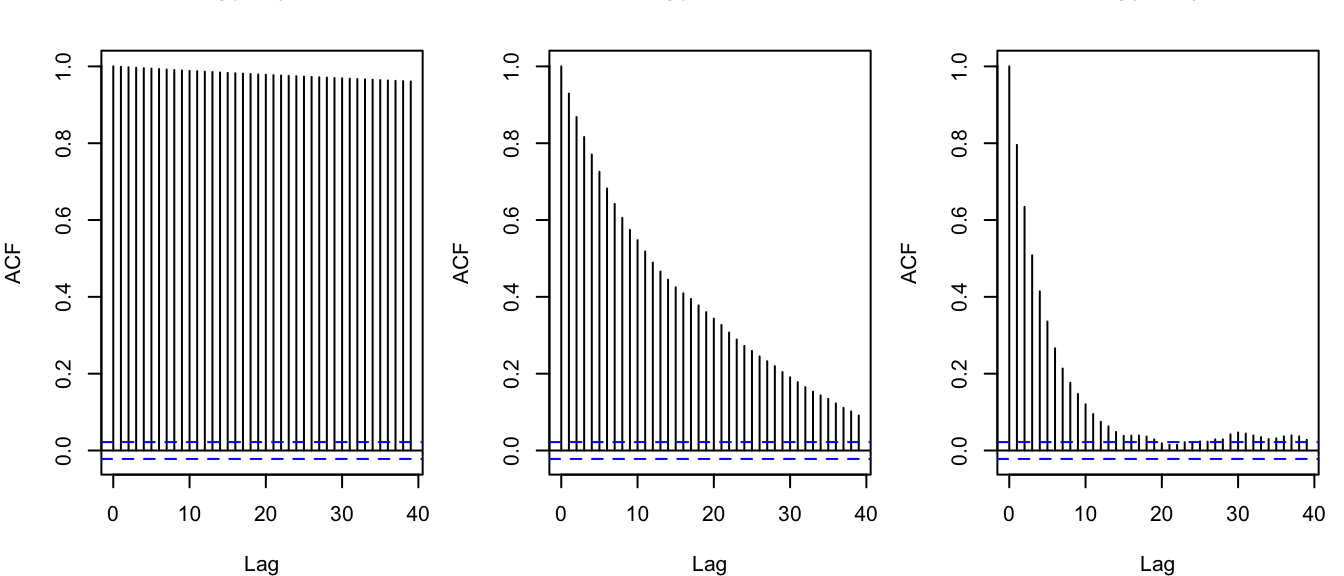
图12.3: 不同提议步长下的自相关函数。
接受率不是越高越好。如果步长太小,候选值总是在当前值附近,因此大多被接受,但链移动很慢,自相关很强。若步长太大,候选值经常落到低密度区域,被拒绝的次数增多,链也会停留在原地。对随机游走Metropolis 来说,接受率过高或过低都值得警惕。实际应用中常先通过短链试运行调节步长,再运行正式链。
12.6 Monte Carlo 误差与有效样本量
独立 Monte Carlo 中,样本均值的方差为
\[ \operatorname{Var}\left(\frac{1}{M}\sum_{m=1}^M X_m\right) = \frac{\operatorname{Var}(X)}{M}. \]
MCMC 样本有相关性,因此多了协方差项:
\[ \begin{aligned} \operatorname{Var}\left(\frac{1}{M}\sum_{m=1}^{M} X_m\right) &= \frac{1}{M^2}\operatorname{Var}\left(\sum_{m=1}^M X_m\right)\\ &= \frac{\operatorname{Var}(X)}{M} +\frac{2}{M^2}\sum_{i=1}^M\sum_{j>i}\operatorname{Cov}(X_i,X_j). \end{aligned} \]
若相邻样本正相关,样本均值的方差会比独立抽样更大。有效样本量(effective sample size, ESS)把相关样本折算为“相当于多少个独立样本”:
\[ \operatorname{Var}\left(\bar X\right) \approx \frac{\operatorname{Var}(X)}{M_{\mathrm{ESS}}}. \]
ESS 不是新的样本数,而是衡量链效率的指标。两个链都运行 10000 次,ESS 可能相差很大。报告 MCMC结果时,迭代次数、burn-in、接受率、ESS 和基本诊断图应该一起看。
12.7 多维目标分布中的 Metropolis
随机游走 Metropolis 可以直接推广到多维参数。设 \(x\) 是向量,提议可以写成
\[ x^\ast=x_t+\varepsilon,\quad \varepsilon\sim N(0,\Sigma_q). \]
此时 \(\Sigma_q\) 决定每个方向的步长和相关结构。若目标分布各参数强相关,而提议分布没有沿着相关方向移动,链会呈现来回折返的低效轨迹。
下面从一个二维混合正态分布中抽样。
log_mvn <- function(x, mean, Sigma) {
x <- as.matrix(x)
if (ncol(x) != length(mean)) {
x <- matrix(x, ncol = length(mean))
}
dx <- sweep(x, 2, mean)
Sigma_inv <- solve(Sigma)
logdet <- as.numeric(determinant(Sigma, logarithm = TRUE)$modulus)
-0.5 * (ncol(x) * log(2 * pi) + logdet +
rowSums((dx %*% Sigma_inv) * dx))
}
log_sum_exp2 <- function(a, b) {
m <- pmax(a, b)
m + log(exp(a - m) + exp(b - m))
}
mu1 <- c(-1, 1)
mu2 <- c(2, -2)
Sigma1 <- matrix(c(1, 0.25, 0.25, 1.5), 2, 2)
Sigma2 <- matrix(c(2, -0.5, -0.5, 2), 2, 2)
log_target_2d <- function(x) {
x <- as.matrix(x)
if (ncol(x) != 2) {
x <- matrix(x, ncol = 2)
}
a <- log(0.45) + log_mvn(x, mu1, Sigma1)
b <- log(0.55) + log_mvn(x, mu2, Sigma2)
log_sum_exp2(a, b)
}
rw_metropolis_vec <- function(x0, n_iter, proposal_sd, log_target) {
samples <- matrix(NA_real_, n_iter, length(x0))
samples[1, ] <- x0
accepted <- logical(n_iter)
for (t in 2:n_iter) {
current <- samples[t - 1, ]
proposal <- current + rnorm(length(x0), sd = proposal_sd)
log_alpha <- log_target(proposal) - log_target(current)
if (log(runif(1)) < log_alpha) {
samples[t, ] <- proposal
accepted[t] <- TRUE
} else {
samples[t, ] <- current
}
}
list(samples = samples, accept_rate = mean(accepted[-1]))
}
set.seed(1)
fit_2d <- rw_metropolis_vec(
x0 = c(-4, -4),
n_iter = 12000,
proposal_sd = 1.6,
log_target = log_target_2d
)
fit_2d$accept_rate
#> [1] 0.5218x_grid <- seq(-5, 6, length.out = 80)
y_grid <- seq(-6, 5, length.out = 80)
grid_2d <- expand.grid(x = x_grid, y = y_grid)
z_2d <- matrix(exp(log_target_2d(as.matrix(grid_2d))),
length(x_grid), length(y_grid))
image(x_grid, y_grid, z_2d, col = gray.colors(20, start = 1, end = 0.65),
xlab = "x1", ylab = "x2")
contour(x_grid, y_grid, z_2d, add = TRUE, drawlabels = FALSE)
lines(fit_2d$samples[1:2500, 1], fit_2d$samples[1:2500, 2],
col = "#D55E00AA")
points(fit_2d$samples[1, 1], fit_2d$samples[1, 2], pch = 19)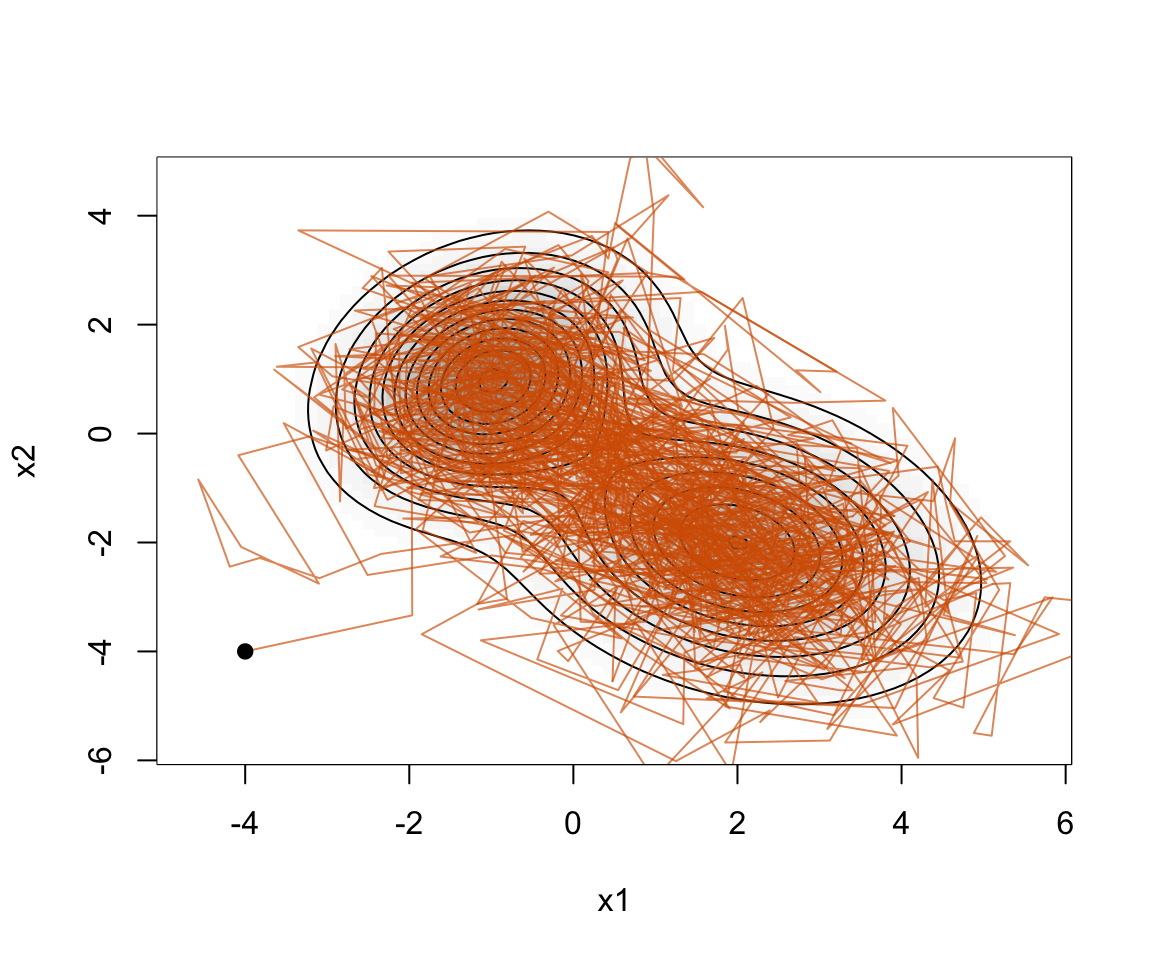
图12.4: 二维目标分布上的随机游走 Metropolis 轨迹。
这个例子说明,多维 MCMC 不只是“一维算法重复几次”。提议分布的尺度和形状会影响链穿越不同区域的能力。在真实贝叶斯模型中,参数可能有更强的相关性和更复杂的后验几何结构,这也是现代工具使用Hamiltonian Monte Carlo 等算法的原因。第 20 章会进一步介绍这些工具。
12.8 Gibbs 抽样
Gibbs 抽样是另一类常见 MCMC 方法。若多维目标分布为 \(\pi(x_1,\ldots,x_d)\),并且每个条件分布
\[ \pi(x_j\mid x_{-j}) \]
都容易抽样,就可以轮流从条件分布中更新每个分量。这里 \(x_{-j}\) 表示除 \(x_j\) 以外的其他分量。
以二维情形为例,若当前状态为 \((x^{(t)},y^{(t)})\),Gibbs 抽样做如下更新:
\[ x^{(t+1)}\sim \pi(x\mid y^{(t)}), \]
\[ y^{(t+1)}\sim \pi(y\mid x^{(t+1)}). \]
注意第二步使用的是刚更新后的 \(x^{(t+1)}\),而不是旧的 \(x^{(t)}\)。对于更多参数,也按相同原则依次使用最新状态。
Gibbs 抽样可以看成 Metropolis–Hastings 的特殊情况。若用条件分布 \(\pi(x\mid y)\) 作为更新 \(x\) 的提议分布,则接受概率为
\[ \begin{aligned} \alpha &= \min\left\{ 1, \frac{\pi(x^\ast,y)\pi(x^{(t)}\mid y)} {\pi(x^{(t)},y)\pi(x^\ast\mid y)} \right\}\\ &= \min\left\{ 1, \frac{\pi(x^\ast\mid y)\pi(y)\pi(x^{(t)}\mid y)} {\pi(x^{(t)}\mid y)\pi(y)\pi(x^\ast\mid y)} \right\} =1. \end{aligned} \]
所以 Gibbs 候选值总是被接受。它的优点是不需要调提议分布;缺点是必须能从条件分布中方便抽样。如果参数之间强相关,逐个坐标更新也可能移动很慢。
12.9 Gibbs 抽样示例:二维正态分布
若
\[ \begin{pmatrix}X\\Y\end{pmatrix} \sim N\left[ \begin{pmatrix}0\\0\end{pmatrix}, \begin{pmatrix}1&\rho\\ \rho&1\end{pmatrix} \right], \]
则条件分布为
\[ X\mid Y=y\sim N(\rho y,1-\rho^2), \]
\[ Y\mid X=x\sim N(\rho x,1-\rho^2). \]
这些条件分布都是一维正态分布,因此可以直接 Gibbs 抽样。
gibbs_bvn <- function(n_iter, rho, x0 = c(0, 0)) {
xy <- matrix(NA_real_, n_iter, 2)
xy[1, ] <- x0
cond_sd <- sqrt(1 - rho^2)
for (t in 2:n_iter) {
xy[t, 1] <- rnorm(1, mean = rho * xy[t - 1, 2], sd = cond_sd)
xy[t, 2] <- rnorm(1, mean = rho * xy[t, 1], sd = cond_sd)
}
colnames(xy) <- c("x", "y")
xy
}
set.seed(123)
rho <- 0.8
xy_gibbs <- gibbs_bvn(6000, rho)
xy_post <- xy_gibbs[1001:6000, ]
rbind(mean = colMeans(xy_post),
sd = apply(xy_post, 2, sd))
#> x y
#> mean -0.006374 -0.01195
#> sd 0.982053 0.98836
cor(xy_post[, 1], xy_post[, 2])
#> [1] 0.798plot(xy_post[, 1], xy_post[, 2], pch = 20, col = "#0072B255",
xlab = "x", ylab = "y", asp = 1)
theta <- seq(0, 2 * pi, length.out = 200)
Sigma <- matrix(c(1, rho, rho, 1), 2, 2)
ellipse <- cbind(cos(theta), sin(theta)) %*% chol(Sigma) *
sqrt(qchisq(0.80, df = 2))
lines(ellipse, col = "red", lwd = 2)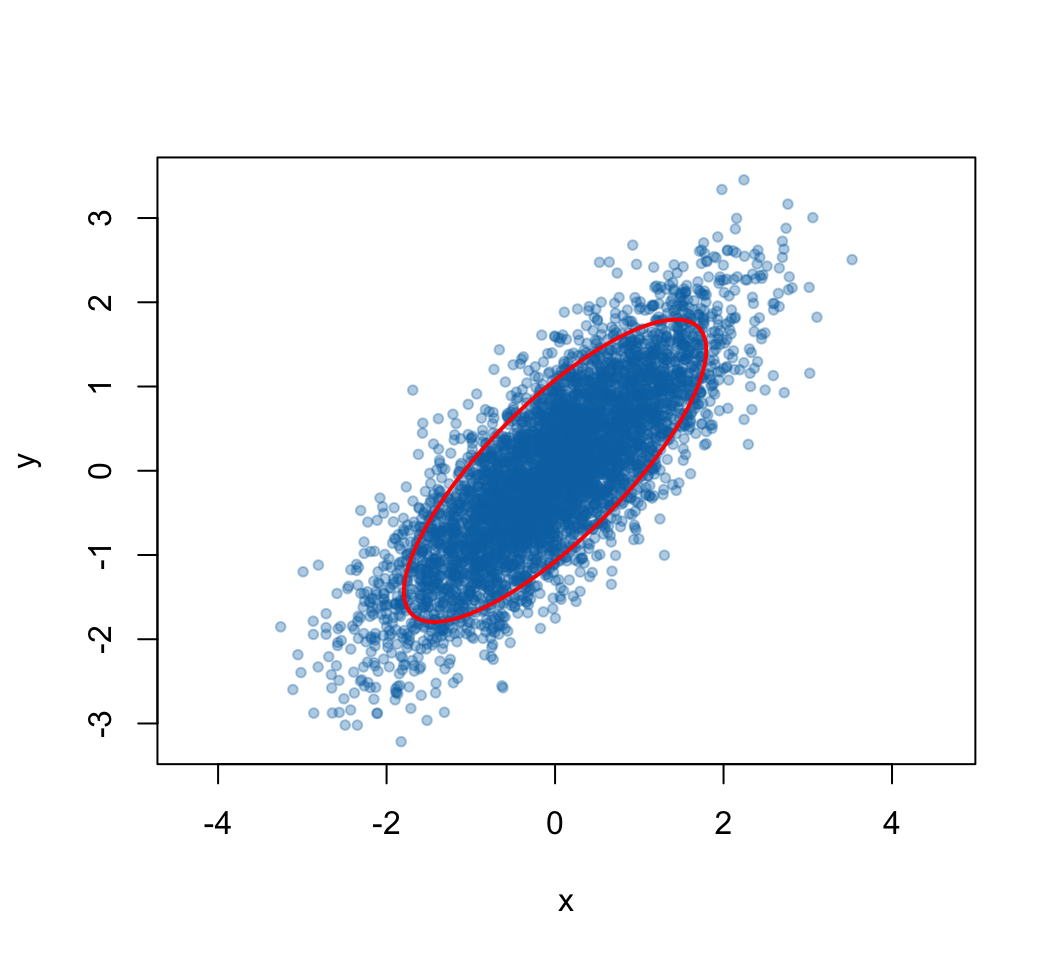
图12.5: 二维正态分布的 Gibbs 抽样结果。
图中的红线是目标二维正态分布的一个等密度椭圆。样本云大致沿着椭圆方向展开,说明 Gibbs 抽样捕捉到了两个变量之间的相关性。
12.10 Metropolis within Gibbs
Gibbs 抽样要求完整条件分布容易抽样。若某个条件分布只知道未归一化形式,或者没有标准随机数生成器,可以在该条件更新中嵌入 Metropolis–Hastings 步骤。这种方法称为 Metropolis within Gibbs。
以参数 \(\theta=(\theta_1,\theta_2,\theta_3)\) 为例,一次迭代可以写成:
- 从 \(\pi(\theta_1\mid\theta_2^{(t)},\theta_3^{(t)},y)\) 抽样,或对这个条件分布做一次 MH 更新;
- 从 \(\pi(\theta_2\mid\theta_1^{(t+1)},\theta_3^{(t)},y)\) 抽样,或做一次 MH 更新;
- 从 \(\pi(\theta_3\mid\theta_1^{(t+1)},\theta_2^{(t+1)},y)\) 抽样,或做一次 MH 更新。
这个思路在贝叶斯回归和层次模型中很常见。它把一个高维问题拆成多个低维更新,通常比一次性为整个参数向量设计高维提议分布更容易。第 18 章中的未知方差回归模型和逻辑回归模型,都可以用这里的思想进行后验抽样。
12.11 案例:银行电话营销的贝叶斯逻辑回归
本节把前面的 MCMC 方法用到一个真实数据案例中。UCI Machine Learning Repository 的 Bank Marketing数据集记录了葡萄牙一家银行的电话营销活动,目标变量 y 表示客户最终是否认购定期存款。该数据集来自 Moro、Laureano 和 Cortez 对银行直接营销问题的研究;本书使用其中较小的 bank.csv 文件,它是完整数据的 10% 随机样本,共 4521 条记录。数据说明见https://doi.org/10.24432/C5K306。
银行营销问题适合用二元响应模型描述。令 \(y_i=1\) 表示第 \(i\) 个客户认购定期存款,\(y_i=0\) 表示未认购。设 \(x_i=(1,x_{i1},\ldots,x_{ip})^\top\) 为解释变量向量,其中第一个分量为截距项。逻辑回归模型为
\[ P(y_i=1\mid x_i,\beta) = \frac{\exp(x_i^\top\beta)} {1+\exp(x_i^\top\beta)}. \]
这里 \(\beta=(\beta_0,\beta_1,\ldots,\beta_p)^\top\) 是回归系数向量,\(\beta_0\) 为截距项。对每个系数给定独立正态先验
\[ \beta_j\sim N(0,5^2),\quad j=0,1,\ldots,p. \]
这个先验表示:在没有数据以前,我们允许系数有较宽范围,但不把极端大的系数看作常见情形。给定数据后,后验密度正比于
\[ p(\beta\mid y,X) \propto \prod_{i=1}^n \left[ \frac{\exp(x_i^\top\beta)} {1+\exp(x_i^\top\beta)} \right]^{y_i} \left[ \frac{1} {1+\exp(x_i^\top\beta)} \right]^{1-y_i} \prod_{j=0}^p \phi(\beta_j;0,5^2). \]
其中 \(X\) 是由所有 \(x_i^\top\) 组成的设计矩阵,\(n\) 是样本量,\(\phi(\beta_j;0,5^2)\) 表示均值为 0、方差为 \(5^2\) 的正态密度。这个后验没有简单闭式形式,因此可以用 Metropolis 算法抽样。
下面读取数据并构造变量。为了把案例聚焦在事前可用于客户筛选的信息上,我们不使用 duration(本次通话时长),因为它只有通话结束后才知道。若把它放入事前预测模型,通常会高估模型对营销筛选的帮助。
bank <- read.csv("data/bank_marketing.csv", sep = ";")
bank$subscribe <- as.integer(bank$y == "yes")
bank$age_z <- as.numeric(scale(bank$age))
bank$balance_z <- as.numeric(scale(bank$balance))
bank$campaign_z <- as.numeric(scale(bank$campaign))
bank$previous_z <- as.numeric(scale(bank$previous))
bank$housing01 <- as.integer(bank$housing == "yes")
bank$loan01 <- as.integer(bank$loan == "yes")
bank$poutcome_success <- as.integer(bank$poutcome == "success")
bank_model <- bank[, c(
"subscribe", "age_z", "balance_z", "campaign_z", "previous_z",
"housing01", "loan01", "poutcome_success"
)]
bank_info <- data.frame(
sample_size = nrow(bank_model),
subscribe_rate = mean(bank_model$subscribe),
predictors = ncol(bank_model) - 1
)
knitr::kable(bank_info, row.names = FALSE, digits = 3)| sample_size | subscribe_rate | predictors |
|---|---|---|
| 4521 | 0.115 | 7 |
为了在数值上稳定地计算对数似然,仍然使用第 7 章中出现过的技巧,避免直接计算log(1 + exp(eta)) 时发生上溢。
X_bank <- model.matrix(
subscribe ~ age_z + balance_z + campaign_z + previous_z +
housing01 + loan01 + poutcome_success,
data = bank_model
)
y_bank <- bank_model$subscribe
log1pexp <- function(x) {
ifelse(x > 0, x + log1p(exp(-x)), log1p(exp(x)))
}
log_posterior_bank <- function(beta) {
eta <- drop(X_bank %*% beta)
loglik <- sum(y_bank * eta - log1pexp(eta))
logprior <- sum(dnorm(beta, mean = 0, sd = 5, log = TRUE))
loglik + logprior
}多维随机游走 Metropolis 的提议分布可以写成
\[ \beta^\ast=\beta^{(t)}+\varepsilon,\quad \varepsilon\sim N(0,\Sigma_q). \]
这里 \(\Sigma_q\) 是提议分布的协方差矩阵。若只给每个参数同一个步长,链可能在某些方向上走得太慢。下面先用普通逻辑回归给出一个初始值和粗略协方差尺度,再用\(2.38^2/p\) 调整提议方差;其中 \(p\) 是参数个数。这个做法只影响 MCMC 的移动效率,不改变目标后验分布。
rw_metropolis_chol <- function(x0, n_iter, proposal_chol, log_target) {
p <- length(x0)
samples <- matrix(NA_real_, n_iter, p)
samples[1, ] <- x0
accepted <- logical(n_iter)
for (t in 2:n_iter) {
current <- samples[t - 1, ]
proposal <- current + as.numeric(rnorm(p) %*% proposal_chol)
log_alpha <- log_target(proposal) - log_target(current)
if (log(runif(1)) < log_alpha) {
samples[t, ] <- proposal
accepted[t] <- TRUE
} else {
samples[t, ] <- current
}
}
list(samples = samples, accept_rate = mean(accepted[-1]))
}
glm_bank <- glm(
subscribe ~ age_z + balance_z + campaign_z + previous_z +
housing01 + loan01 + poutcome_success,
data = bank_model,
family = binomial()
)
p_bank <- length(coef(glm_bank))
proposal_chol <- chol((2.38^2 / p_bank) * vcov(glm_bank))
set.seed(12)
fit_bank <- rw_metropolis_chol(
x0 = coef(glm_bank),
n_iter = 9000,
proposal_chol = proposal_chol,
log_target = log_posterior_bank
)
post_bank <- fit_bank$samples[2001:9000, ]
colnames(post_bank) <- colnames(X_bank)
bank_diag <- data.frame(
accept_rate = fit_bank$accept_rate,
min_ess = min(apply(post_bank, 2, mcmc_ess))
)
knitr::kable(bank_diag, row.names = FALSE, digits = 3)| accept_rate | min_ess |
|---|---|
| 0.279 | 221.5 |
接下来汇总每个系数的后验均值、后验标准差和 95% 后验区间。
bank_coef_summary <- data.frame(
term = colnames(post_bank),
mean = colMeans(post_bank),
sd = apply(post_bank, 2, sd),
q025 = apply(post_bank, 2, quantile, 0.025),
q975 = apply(post_bank, 2, quantile, 0.975)
)
knitr::kable(bank_coef_summary, row.names = FALSE, digits = 3)| term | mean | sd | q025 | q975 |
|---|---|---|---|---|
| (Intercept) | -1.856 | 0.073 | -2.006 | -1.717 |
| age_z | 0.049 | 0.049 | -0.050 | 0.147 |
| balance_z | -0.004 | 0.048 | -0.093 | 0.092 |
| campaign_z | -0.241 | 0.072 | -0.384 | -0.105 |
| previous_z | 0.130 | 0.041 | 0.051 | 0.209 |
| housing01 | -0.562 | 0.102 | -0.766 | -0.365 |
| loan01 | -0.643 | 0.173 | -0.984 | -0.318 |
| poutcome_success | 2.388 | 0.206 | 1.980 | 2.790 |
par(mfrow = c(1, 2))
plot(post_bank[, "campaign_z"], type = "l", xlab = "Iteration",
ylab = expression(beta), main = "campaign_z")
plot(post_bank[, "poutcome_success"], type = "l", xlab = "Iteration",
ylab = expression(beta), main = "poutcome_success")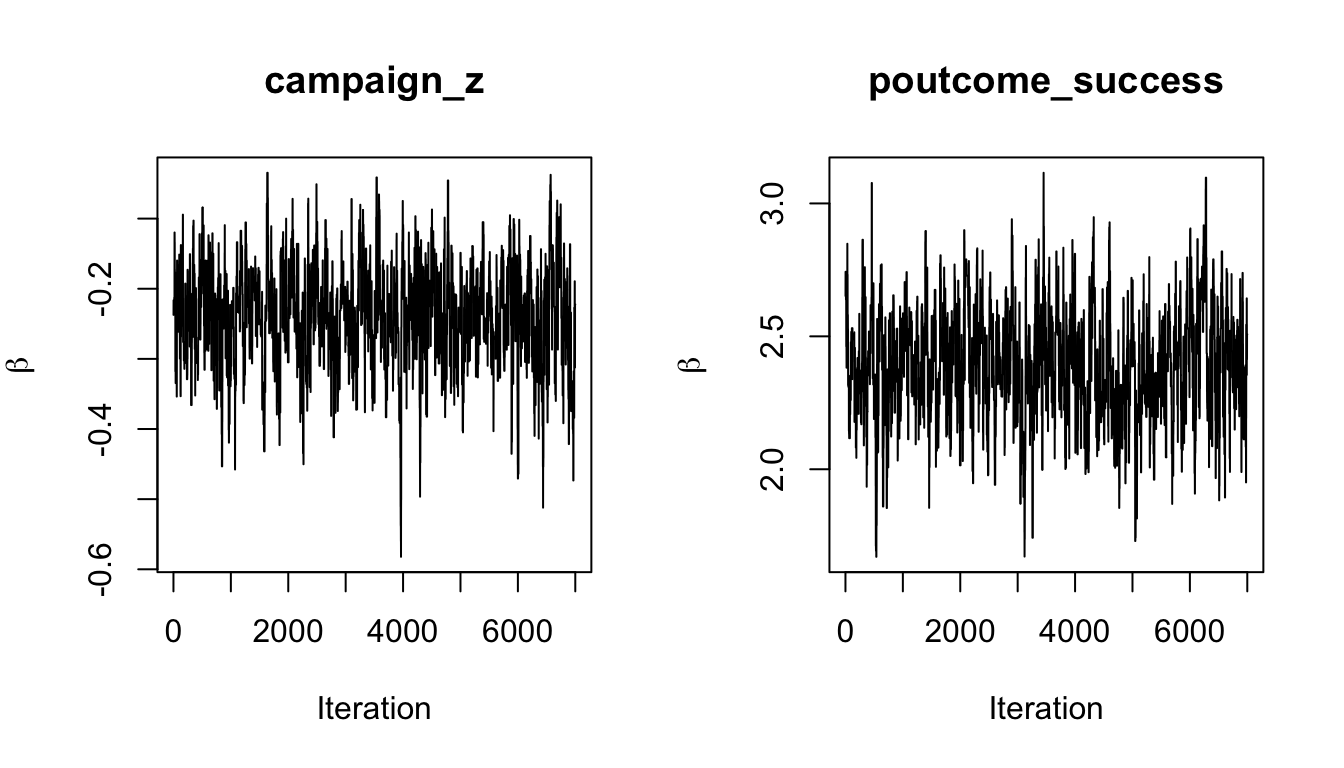
图12.6: 银行电话营销逻辑回归中部分参数的 MCMC 轨迹。
在逻辑回归中,系数表示对数赔率的变化。例如 housing01 的后验若主要小于 0,表示在其他变量相同时,有住房贷款的客户认购定期存款的后验赔率较低;poutcome_success 若明显为正,则表示上一轮营销曾经成功的客户,在本轮认购的概率更高。这里的解释是统计关联,不是因果效应。电话营销数据受到客户选择、营销策略和历史接触安排影响,不能简单理解为“改变某个变量就会导致认购概率改变”。
最后比较两个客户画像的后验预测概率。第一个画像对应住房贷款和个人贷款均为“是”、上一轮营销没有成功记录且本轮接触次数偏多的客户;第二个画像对应无住房贷款、无个人贷款、上一轮营销成功且本轮接触次数偏少的客户。
profile_bank <- data.frame(
age_z = c(0, 0),
balance_z = c(-0.5, 0.5),
campaign_z = c(0.5, -0.5),
previous_z = c(0, 1),
housing01 = c(1, 0),
loan01 = c(1, 0),
poutcome_success = c(0, 1)
)
X_profile <- model.matrix(
~ age_z + balance_z + campaign_z + previous_z +
housing01 + loan01 + poutcome_success,
data = profile_bank
)
p_profile <- plogis(post_bank %*% t(X_profile))
profile_summary <- data.frame(
profile = c("loan-heavy, no prior success", "no loans, prior success"),
mean = colMeans(p_profile),
q025 = apply(p_profile, 2, quantile, 0.025),
q975 = apply(p_profile, 2, quantile, 0.975)
)
knitr::kable(profile_summary, row.names = FALSE, digits = 3)| profile | mean | q025 | q975 |
|---|---|---|---|
| loan-heavy, no prior success | 0.041 | 0.028 | 0.054 |
| no loans, prior success | 0.684 | 0.598 | 0.765 |
这个表给出的不是一个单一预测值,而是订阅概率的后验分布摘要。它体现了贝叶斯计算的一个优势:在给出概率预测的同时,也能保留由于参数不确定性带来的区间信息。
12.12 MCMC 诊断
MCMC 输出不能只看后验均值。至少应检查以下方面:
- trace plot:样本轨迹是否在合理范围内来回移动,而不是卡在某个区域;
- 接受率:随机游走 Metropolis 接受率过高可能表示步长太小,过低可能表示步长太大;
- 自相关:相邻样本相关性越强,有效信息量越少;
- 有效样本量:关注独立信息量,而不是只看迭代次数;
- 多链比较:从不同初始值出发,检查是否得到相似后验结果;
- 后验可解释性:结果是否与数据、模型和先验设定相符。
这些诊断不是形式要求,而是判断模拟近似是否可信的必要步骤。第 20 章会介绍现代贝叶斯软件中常见的 R-hat、ESS 和 divergent transition 等诊断指标。