第 5 章 求根算法
在统计计算中,我们经常需要求解形如\(f(x)=0\)的方程。这里的未知量可以是一个临界值、一个分位数、一个参数估计量,也可以是某个迭代算法中的中间变量。比如:
- 求 \(x^2-5=0\) 的根,可以得到 \(\sqrt 5\) 的数值近似;
- 求 \(F(x)-0.95=0\),可以得到分布函数 \(F\) 的 95% 分位数;
- 求对数似然的一阶导数 \(\ell'(\theta)=0\),可以得到最大似然估计;
- 在某些模型中,参数更新没有闭式解,也需要通过数值求根完成。
本章介绍一维求根的基本方法。重点不是把所有可能的算法列完,而是让读者掌握三件事:如何把统计问题写成求根问题,如何选择合适的数值算法,以及如何判断一个算法是否可靠收敛。
5.1 求根问题的基本设定
设 \(f(x)\) 是一维函数,我们希望找到 \(x^\ast\),使得
\[ f(x^\ast)=0. \]
数值算法通常无法在有限步内得到完全精确的根,而是得到一个近似值 \(\hat x\)。因此,我们需要先明确什么叫“足够接近”。常用停止条件有两类:
- 函数值足够小:\(|f(\hat x)|<\epsilon\);
- 相邻迭代值变化足够小:\(|x_{n+1}-x_n|<\epsilon\)。
实际编程时,通常还会设置最大迭代次数 max_iter,以避免算法在不收敛时无限运行。一个写得稳妥的求根函数,除了返回根的近似值,也应该返回迭代次数、是否收敛、最后的函数值等信息。
下面先从最可靠的二分法讲起。
5.2 二分法
二分法(bisection method)也称区间减半法,是一维连续函数求根中最稳健的方法之一。它的核心依据是介值定理:如果 \(f(x)\) 在区间 \([a,b]\) 上连续,且 \(f(a)\) 与 \(f(b)\) 异号,即
\[ f(a)f(b)<0, \]
那么 \([a,b]\) 内至少存在一个根。
二分法的思想很朴素:每次取区间中点,判断根落在左半区间还是右半区间,然后把区间长度缩小一半。
二分法
- 选择初始区间 \([a,b]\),要求 \(f(a)f(b)<0\)。
- 计算中点 \(c=(a+b)/2\)。
- 如果 \(|f(c)|<\epsilon\) 或 \(|b-a|<\epsilon\),停止迭代,输出 \(c\)。
- 如果 \(f(a)f(c)<0\),令 \(b\leftarrow c\);否则令 \(a\leftarrow c\)。
- 重复第 2–4 步,直到满足停止条件。
下面给出一个 R 实现。注意这里不直接打印每一步,而是把迭代轨迹保存在 trace 中,便于后面检查和作图。
bisection_root <- function(f, a, b, tol = 1e-8, max_iter = 100) {
fa <- f(a)
fb <- f(b)
if (!is.finite(fa) || !is.finite(fb)) {
stop("f(a) 和 f(b) 必须是有限数值。")
}
if (fa == 0) {
return(list(root = a, value = fa, iter = 0,
converged = TRUE, trace = data.frame(iter = 0, x = a, fx = fa)))
}
if (fb == 0) {
return(list(root = b, value = fb, iter = 0,
converged = TRUE, trace = data.frame(iter = 0, x = b, fx = fb)))
}
if (fa * fb > 0) {
stop("初始区间两端函数值必须异号。")
}
trace <- data.frame(iter = integer(), x = numeric(), fx = numeric())
for (iter in seq_len(max_iter)) {
c <- (a + b) / 2
fc <- f(c)
trace <- rbind(trace, data.frame(iter = iter, x = c, fx = fc))
if (abs(fc) < tol || abs(b - a) < tol) {
return(list(root = c, value = fc, iter = iter,
converged = TRUE, trace = trace))
}
if (fa * fc < 0) {
b <- c
fb <- fc
} else {
a <- c
fa <- fc
}
}
c <- (a + b) / 2
list(root = c, value = f(c), iter = max_iter,
converged = FALSE, trace = trace)
}5.2.1 例:求 \(\sqrt 5\)
求 \(\sqrt 5\) 可以转化为求
\[ f(x)=x^2-5 \]
在区间 \([0,4]\) 上的根。
f <- function(x) x^2 - 5
bis <- bisection_root(f, a = 0, b = 4, tol = 1e-8)
bis$root
#> [1] 2.236
bis$value
#> [1] -3.118e-09
bis$iter
#> [1] 30
sqrt(5)
#> [1] 2.236二分法最突出的优点是可靠:只要函数连续、初始区间两端异号,它就一定会把包含根的区间不断缩小。缺点也很明显:它只利用了函数值的正负信息,因此收敛速度比较慢。
5.2.2 使用二分法时要注意什么
二分法看起来简单,但在实际使用时仍有几个容易忽略的问题。
第一,函数必须在区间内连续。比如 \(f(x)=1/x\) 在 \([-1,1]\) 两端异号,但 \(x=0\) 不是根,而是函数不连续点。
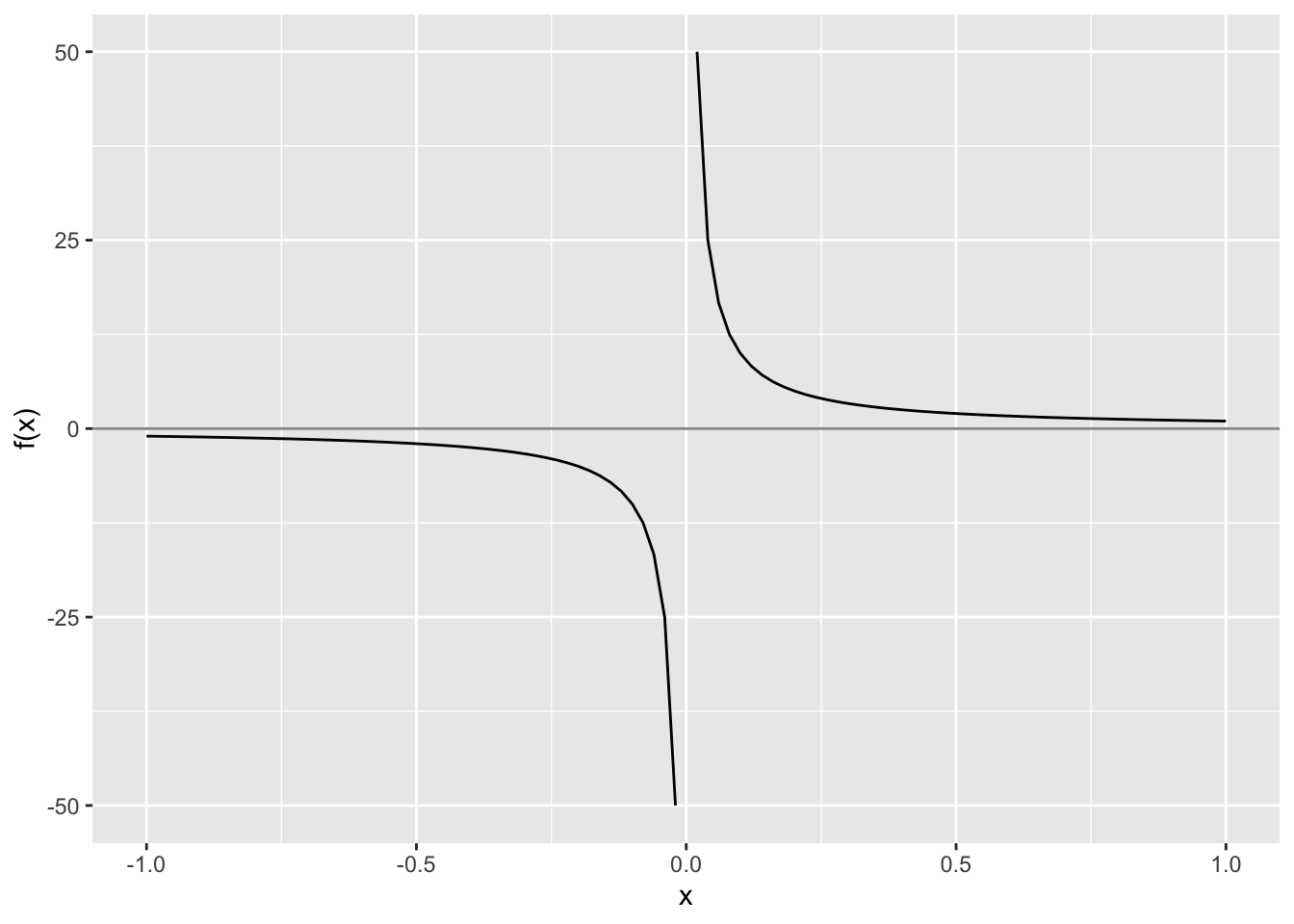
图5.1: 两端异号不一定表示中间有根:函数可能不连续
第二,如果根的位置只是“擦过”横轴,函数在根的两侧没有变号,二分法无法直接使用。例如 \(f(x)=x^2\) 在 \(x=0\) 有根,但任意对称区间两端函数值同号。
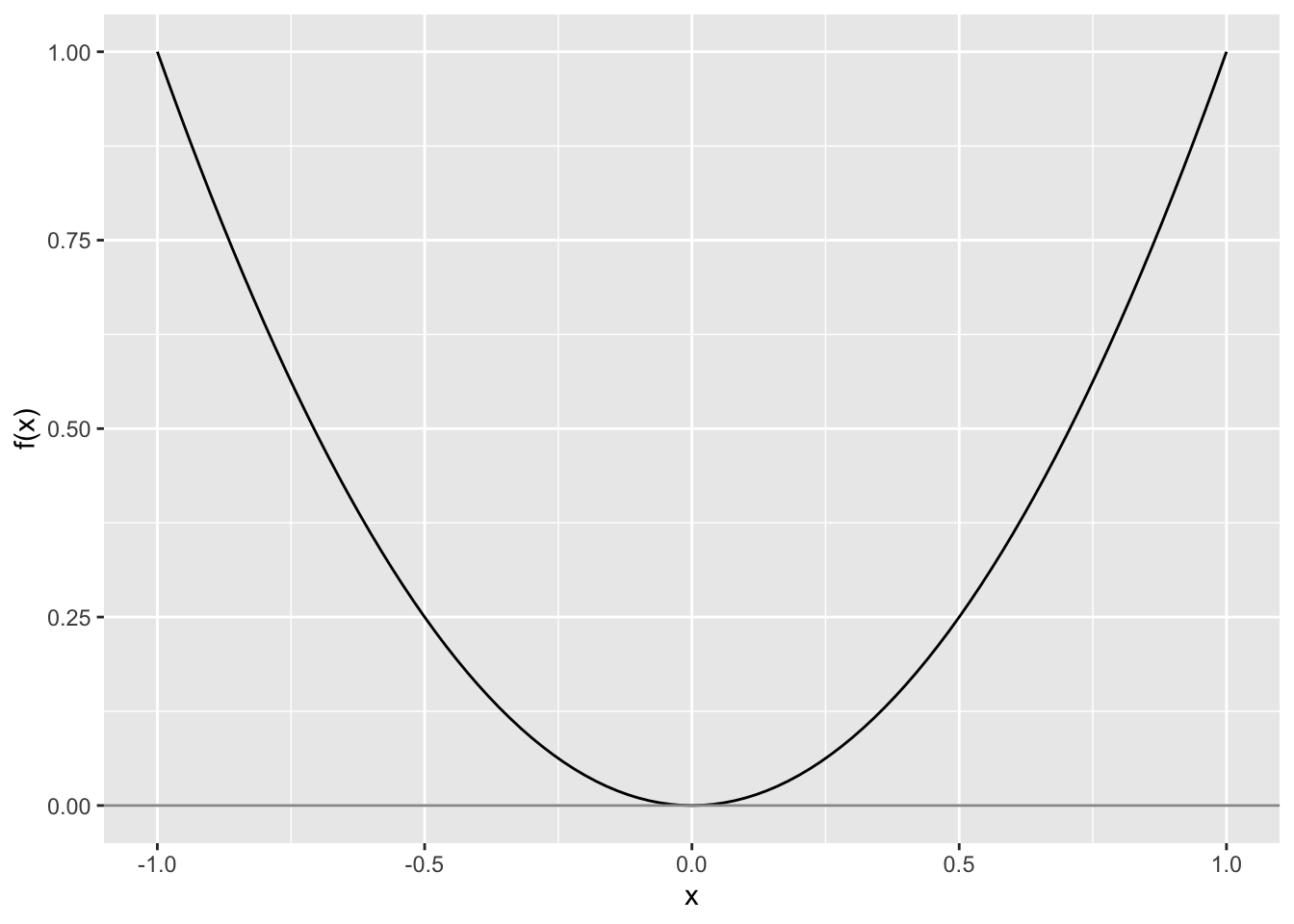
图5.2: 函数在根处没有变号时,二分法无法直接定位根
第三,如果区间内有多个根,二分法通常只能找到其中一个。要找出多个根,需要先把大区间划分成若干小区间,再检查每个小区间是否存在变号。
5.3 牛顿法
二分法可靠但慢。牛顿法(Newton method,也称 Newton–Raphson method)则通常收敛很快。它的思想是:在当前点 \(x_n\) 附近,用切线近似函数,然后取切线与横轴的交点作为新的估计。
假设 \(f\) 可导,且 \(x^\ast\) 是 \(f(x)=0\) 的根。在当前点 \(x_n\) 处做一阶泰勒展开:
\[ f(x) \approx f(x_n) + f'(x_n)(x-x_n). \]
令右边等于 0,得到
\[ x = x_n - \frac{f(x_n)}{f'(x_n)}. \]
于是牛顿法的迭代公式为
\[ x_{n+1}=x_n-\frac{f(x_n)}{f'(x_n)}. \]
牛顿法
- 选择初始点 \(x_0\)。
- 计算 \(f(x_n)\) 和 \(f'(x_n)\)。
- 若 \(|f(x_n)|<\epsilon\),停止迭代。
- 若 \(f'(x_n)\) 过小,需要停止或更换方法。
- 更新
\[ x_{n+1}=x_n-\frac{f(x_n)}{f'(x_n)}. \]
- 重复第 2–5 步。
下面的图给出了牛顿法的几何直觉。
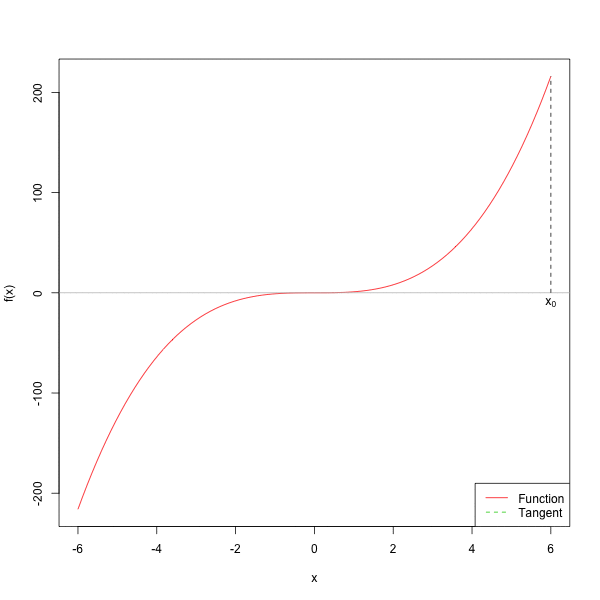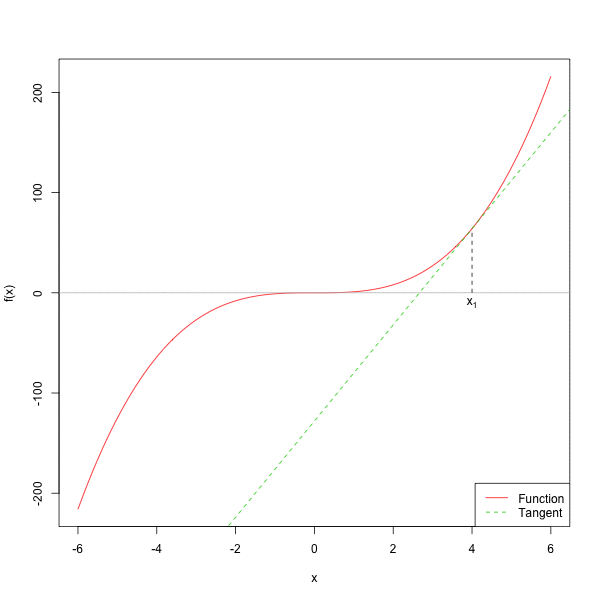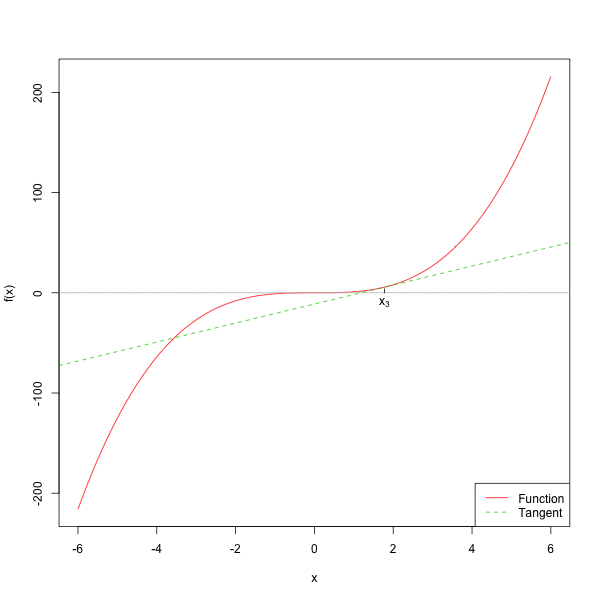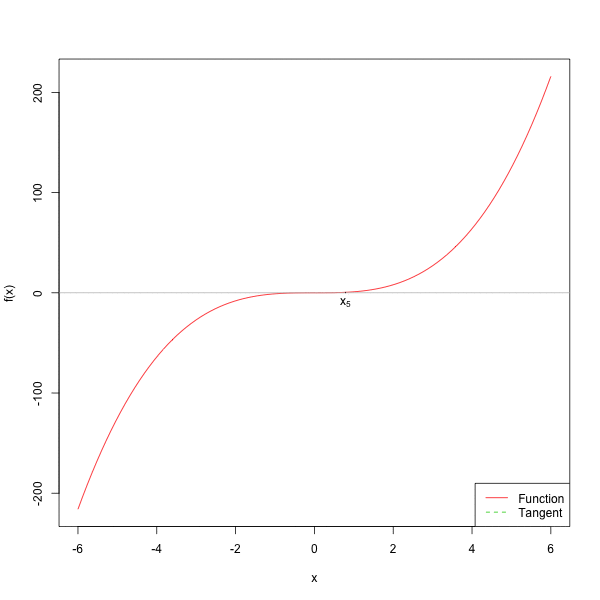
下面实现一个更适合教学和调试的 newton_root()。这里要求用户同时给出 \(f(x)\) 和 \(f'(x)\),这样比自动求导更清楚,也更容易扩展到统计模型中的 score 方程。
newton_root <- function(f, df, x0, tol = 1e-8, max_iter = 100) {
x <- x0
trace <- data.frame(iter = 0, x = x, fx = f(x))
for (iter in seq_len(max_iter)) {
fx <- f(x)
dfx <- df(x)
if (abs(fx) < tol) {
return(list(root = x, value = fx, iter = iter - 1,
converged = TRUE, trace = trace))
}
if (!is.finite(dfx) || abs(dfx) < .Machine$double.eps) {
return(list(root = x, value = fx, iter = iter - 1,
converged = FALSE, trace = trace,
reason = "导数过小或不是有限数值。"))
}
x <- x - fx / dfx
trace <- rbind(trace, data.frame(iter = iter, x = x, fx = f(x)))
}
list(root = x, value = f(x), iter = max_iter,
converged = FALSE, trace = trace,
reason = "达到最大迭代次数。")
}5.3.1 例:再次求 \(\sqrt 5\)
对 \(f(x)=x^2-5\),有 \(f'(x)=2x\)。
f <- function(x) x^2 - 5
df <- function(x) 2 * x
nr <- newton_root(f, df, x0 = 5)
nr$root
#> [1] 2.236
nr$value
#> [1] 8.429e-13
nr$iter
#> [1] 5
nr$trace
#> iter x fx
#> 1 0 5.000 2.000e+01
#> 2 1 3.000 4.000e+00
#> 3 2 2.333 4.444e-01
#> 4 3 2.238 9.070e-03
#> 5 4 2.236 4.106e-06
#> 6 5 2.236 8.429e-13在这个例子中,牛顿法只需很少几步就得到高精度近似。这也是牛顿法在统计计算中非常常用的原因。
5.3.2 牛顿法什么时候会出问题
牛顿法快,但它不如二分法稳健。常见问题包括:
- 初始值离根太远,迭代可能跑到别的地方;
- 导数接近 0,更新步长会非常大;
- 函数形状复杂时,迭代可能震荡或发散;
- 如果函数不可导或导数难以计算,牛顿法使用成本较高。
下面的例子展示导数过小时可能发生的情况。对 \(f(x)=x^3-2x+2\),如果从某些初始点出发,牛顿法可能在两个点附近来回跳动,难以收敛。
f_bad <- function(x) x^3 - 2 * x + 2
df_bad <- function(x) 3 * x^2 - 2
nr_bad <- newton_root(f_bad, df_bad, x0 = 0, max_iter = 8)
nr_bad$converged
#> [1] FALSE
nr_bad$trace
#> iter x fx
#> 1 0 0 2
#> 2 1 1 1
#> 3 2 0 2
#> 4 3 1 1
#> 5 4 0 2
#> 6 5 1 1
#> 7 6 0 2
#> 8 7 1 1
#> 9 8 0 2因此,实际工作中常见做法是:先用图形或网格搜索找到一个较好的初始区间,再使用二分法、牛顿法或 R 的 uniroot()。如果必须使用牛顿法,也应检查是否收敛,并保存迭代诊断信息。
5.4 割线法
牛顿法需要导数。如果导数不好写或计算成本较高,可以使用割线法(secant method)。割线法用最近两个点的函数值近似导数:
\[ f'(x_n)\approx \frac{f(x_n)-f(x_{n-1})}{x_n-x_{n-1}}. \]
代入牛顿法公式,得到
\[ x_{n+1}=x_n-f(x_n)\frac{x_n-x_{n-1}}{f(x_n)-f(x_{n-1})}. \]
割线法不保证像二分法那样稳健,但通常比二分法快,而且不需要显式导数。
secant_root <- function(f, x0, x1, tol = 1e-8, max_iter = 100) {
trace <- data.frame(iter = 0:1, x = c(x0, x1), fx = c(f(x0), f(x1)))
for (iter in 2:max_iter) {
f0 <- f(x0)
f1 <- f(x1)
denom <- f1 - f0
if (abs(denom) < .Machine$double.eps) {
return(list(root = x1, value = f1, iter = iter - 1,
converged = FALSE, trace = trace,
reason = "相邻两点函数值过于接近。"))
}
x2 <- x1 - f1 * (x1 - x0) / denom
trace <- rbind(trace, data.frame(iter = iter, x = x2, fx = f(x2)))
if (abs(f(x2)) < tol || abs(x2 - x1) < tol) {
return(list(root = x2, value = f(x2), iter = iter,
converged = TRUE, trace = trace))
}
x0 <- x1
x1 <- x2
}
list(root = x1, value = f(x1), iter = max_iter,
converged = FALSE, trace = trace,
reason = "达到最大迭代次数。")
}5.5 收敛速度
比较求根算法时,除了看能否收敛,还要看收敛速度。设迭代序列 \(x_n\) 收敛到真实根 \(x^\ast\),令误差 \(e_n=|x_n-x^\ast|\)。
如果存在常数 \(0<r<1\),使得
\[ \lim_{n\to\infty}\frac{e_{n+1}}{e_n}=r, \]
则称为线性收敛。二分法就是典型的线性收敛算法,每一步把区间长度减半。
如果
\[ \lim_{n\to\infty}\frac{e_{n+1}}{e_n}=0, \]
则称为超线性收敛。割线法在适当条件下超线性收敛,其收敛阶约为 \(1.618\)。
如果存在常数 \(C>0\),使得
\[ e_{n+1}\approx C e_n^2, \]
则称为平方收敛。牛顿法在根附近、导数不为 0 且函数足够光滑时通常具有平方收敛。这意味着一旦进入根附近,正确位数可能会快速增加。
下面比较三个算法求解 \(x^2-5=0\) 时的迭代次数。
f <- function(x) x^2 - 5
df <- function(x) 2 * x
comparison <- data.frame(
method = c("二分法", "牛顿法", "割线法"),
root = c(
bisection_root(f, 0, 4)$root,
newton_root(f, df, 5)$root,
secant_root(f, 2, 5)$root
),
iter = c(
bisection_root(f, 0, 4)$iter,
newton_root(f, df, 5)$iter,
secant_root(f, 2, 5)$iter
)
)
comparison
#> method root iter
#> 1 二分法 2.236 30
#> 2 牛顿法 2.236 5
#> 3 割线法 2.236 6这个比较并不是说某个算法永远最好。二分法慢但稳,牛顿法快但依赖初始值和导数,割线法介于二者之间。实际计算中,算法选择往往取决于函数性质、是否有导数、是否能找到包含根的区间,以及是否需要强可靠性。
5.6 R 中的求根函数
R 自带 uniroot(),它是实际工作中最常用的一维求根工具之一。uniroot() 要求用户给出一个区间,并且区间两端函数值异号。它内部使用比单纯二分法更高效的混合策略,但保持了区间法的可靠性。
f <- function(x) x^2 - 5
uniroot(f, interval = c(0, 4))
#> $root
#> [1] 2.236
#>
#> $f.root
#> [1] 0.0001273
#>
#> $iter
#> [1] 6
#>
#> $init.it
#> [1] NA
#>
#> $estim.prec
#> [1] 6.104e-05在编写统计程序时,如果目标函数是一维连续函数,并且能找到变号区间,通常可以优先考虑 uniroot(),而不是从头写二分法或牛顿法。
5.7 统计计算中的例子
5.7.1 例:用求根计算 Gamma 分布参数
设 \(X_1,\ldots,X_n\) 来自 Gamma 分布,形状参数为 \(\alpha\),速率参数为 \(\beta\)。在最大似然估计中,可以先把 \(\beta\) 写成 \(\alpha/\bar X\),然后 \(\alpha\) 需要满足
\[ \log(\alpha)-\psi(\alpha) = \log(\bar X)-\overline{\log X}, \]
其中 \(\psi(\alpha)\) 是 digamma 函数。这个方程一般没有简单闭式解,因此可以用求根算法。
set.seed(123)
x <- rgamma(200, shape = 3, rate = 2)
c_value <- log(mean(x)) - mean(log(x))
score_alpha <- function(alpha) {
log(alpha) - digamma(alpha) - c_value
}
alpha_hat <- uniroot(score_alpha, interval = c(0.01, 100))$root
beta_hat <- alpha_hat / mean(x)
c(alpha_hat = alpha_hat, beta_hat = beta_hat)
#> alpha_hat beta_hat
#> 3.132 2.202这个例子展示了求根算法和最大似然估计之间的关系。很多统计模型虽然写得出似然函数,但一阶条件未必能手工解出,这时数值求根就是连接理论和计算的桥。
5.7.2 例:混合正态分布的分位数
再看一个分位数问题。设随机变量来自两个正态分布的混合:
\[ F(x)=0.7\Phi(x)+0.3\Phi\left(\frac{x-3}{1.5}\right). \]
要求 95% 分位数,就是求解
\[ F(q)-0.95=0. \]
mix_cdf <- function(x) {
0.7 * pnorm(x, mean = 0, sd = 1) +
0.3 * pnorm(x, mean = 3, sd = 1.5)
}
target <- function(q) mix_cdf(q) - 0.95
q95 <- uniroot(target, interval = c(-4, 8))$root
q95
#> [1] 4.451
mix_cdf(q95)
#> [1] 0.95这个例子说明,即使分布函数可以计算,分位数也未必有闭式表达。求根算法使我们可以直接从定义出发计算分位数。
5.8 本章小结
本章介绍了一维求根问题的三个基本算法。二分法依赖变号区间,收敛慢但非常稳健;牛顿法利用导数信息,在根附近通常收敛很快,但对初始值和导数条件较敏感;割线法不需要显式导数,常作为二分法和牛顿法之间的折中选择。R 中的 uniroot() 是实际工作中求解一维方程的可靠工具。
在计算统计中,求根算法经常出现在最大似然估计、分位数计算、置信区间端点计算和模型参数更新中。面对具体问题时,应先判断函数是否连续、是否能找到变号区间、是否容易计算导数,再选择合适的方法。
求根算法也自然引出下一章的优化算法。许多统计估计问题先表现为“让某个目标函数达到最大或最小”,再通过一阶条件转化为求根问题;但在实际建模中,目标函数往往是多维的,可能带有约束、惩罚项或复杂的数值结构。这时,我们需要从“求一个方程的根”进一步走向“寻找一个目标函数的最优值”。
5.9 练习
用二分法求 \(x^3-x-1=0\) 在区间 \([1,2]\) 上的根,并记录迭代次数。
用牛顿法求 \(x^3-x-1=0\) 的根,分别尝试初始值 \(x_0=1\) 和 \(x_0=10\),比较迭代过程。
对 \(f(x)=\cos(x)-x\),分别使用
bisection_root()、newton_root()、secant_root()和uniroot()求根,比较结果和迭代次数。找一个函数例子,使得二分法可以收敛,但牛顿法从某个初始值出发不收敛。解释原因。
在 Gamma 分布参数估计例子中,把样本量改为 \(n=20,100,1000\),观察 \(\hat\alpha\) 和 \(\hat\beta\) 的变化。
在混合正态分布分位数例子中,计算 90%、95% 和 99% 分位数。观察分位数随概率水平的变化。