第 1 章 计算统计的动机与基本问题
在概率论、数理统计和计量经济学课程中,我们已经见过很多漂亮的统计公式:密度函数、似然函数、最小二乘估计、极大似然估计、后验分布、期望和积分等。这些公式告诉我们统计推断的目标是什么,但当我们真的要把它们用于数据分析时,还会遇到一个更具体的问题:这些量究竟如何由计算机算出来?
这正是计算统计要回答的问题。计算统计关心的不是把统计理论替换成程序,而是研究统计理论如何通过可靠、稳定和可复现的计算过程落地。理论告诉我们要计算什么,计算方法决定我们能否把它算出来,以及算出来的结果是否可信。
本章从几个简单例子出发,说明为什么统计推断离不开计算。后续章节中的线性代数、求根、优化、数值积分、随机模拟、重采样和 MCMC 方法,都可以看作对这些基本问题的系统回答。
1.1 统计建模的计算流程
一次完整的统计分析通常不只是“套一个模型”或“调用一个函数”。从计算统计的角度看,统计建模可以理解为以下流程:
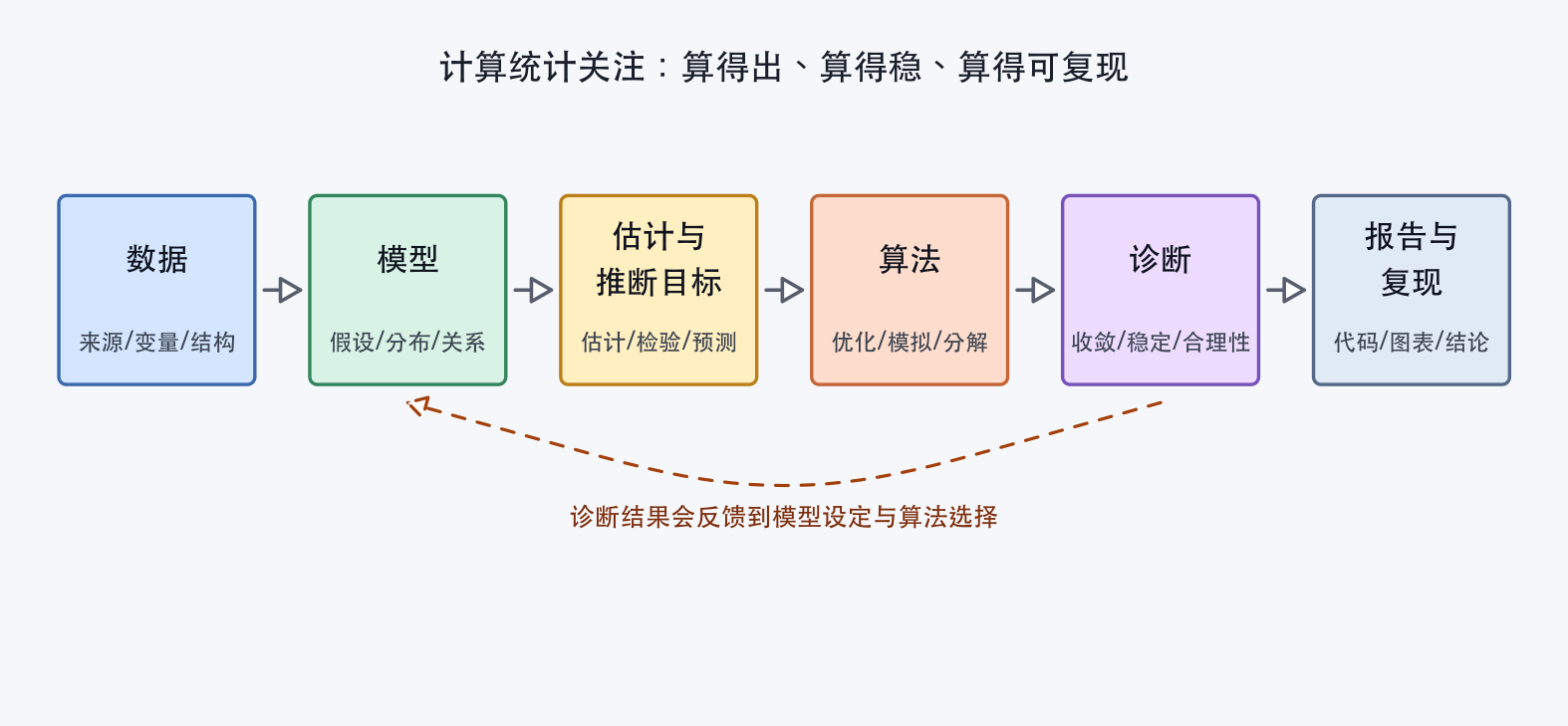
图1.1: 统计建模的计算流程
- 数据。明确数据来源、变量含义、缺失值、异常值和数据结构。
- 模型。根据研究问题写出统计模型,例如线性模型、广义线性模型、层次模型或隐变量模型。
- 估计与推断目标。确定需要计算的对象,例如参数估计、标准误、置信区间、后验分布、预测分布或检验统计量。
- 算法。选择可执行的计算方法,例如矩阵分解、数值优化、数值积分、Monte Carlo、Bootstrap 或 MCMC。
- 诊断。检查算法是否收敛、结果是否稳定、模型是否合理、预测表现是否可靠。
- 报告与复现。用可复现的代码、图表和文字说明数据、模型、算法和结论。
这个流程强调一个事实:统计模型只有通过算法才能变成实际结果。模型设定回答“用什么结构描述数据”,算法实现回答“如何把这个结构算出来”,诊断和报告则回答“这个结果是否可信、是否可以被别人复现”。
1.2 从公式到计算
在课堂上推导统计公式时,我们通常默认实数可以被精确表示,代数运算可以无限精确地完成,矩阵只要可逆就可以写出逆矩阵,积分只要存在就可以被计算出来。但计算机并不在这个理想世界里工作。
首先,计算机只能用有限精度表示数字。非常大的数可能导致上溢,非常小的数可能导致下溢,两个几乎相等的数相减也可能造成严重的精度损失。其次,数学表达式的形式和实际计算时应采用的算法并不总是相同。一个公式在纸面上很简洁,直接翻译成代码却可能又慢又不稳定。再次,很多统计问题本身并没有解析解,例如复杂似然函数的极大化、高维积分、隐变量模型和贝叶斯后验分布,这些都需要算法来近似完成。
因此,学习计算统计时要反复追问三个问题:
- 统计理论要求我们计算什么?
- 这个量在计算机上应当如何稳定地计算?
- 算法误差、随机误差和数值误差会怎样影响统计结论?
1.3 例子:对数概率
在统计建模中,概率密度或似然函数常常是很多小概率的乘积。直接计算这些乘积容易出现下溢,因此我们通常转而计算对数概率。以标准正态分布为例:
dnorm(40) 的真实密度非常接近 0,在浮点数表示中会被直接显示为 0;而对数密度仍然可以被稳定表示。对于似然函数
\[ L(\theta)=\prod_{i=1}^n f(y_i \mid \theta), \]
我们通常计算的是对数似然
\[ \ell(\theta)=\log L(\theta)=\sum_{i=1}^n \log f(y_i \mid \theta). \]
这不仅可以避免数值下溢,也把乘法转化为加法,使求导、优化和程序实现都更加方便。类似地,如果需要计算密度比
\[ \frac{f(x)}{g(x)}, \]
直接计算两个很小密度的比值可能不稳定,更稳妥的方式通常是
\[ \exp\{\log f(x)-\log g(x)\}. \]
这类看似细小的处理,正是统计理论与计算实现之间的第一道桥。
1.4 例子:线性回归不是直接求逆
线性回归是统计学中最熟悉的模型之一。矩阵形式下,
\[ y=X\beta+\varepsilon, \]
普通最小二乘估计常被写作
\[ \hat{\beta}=(X^\top X)^{-1}X^\top y. \]
这个公式非常适合帮助我们理解估计量的数学结构,但它并不意味着在程序中应该先计算 \((X^\top X)^{-1}\)。直接求逆通常计算成本更高,也更容易受到共线性和舍入误差的影响。更好的做法是把问题看作线性方程组
\[ X^\top X\beta=X^\top y, \]
然后直接求解这个方程组,或者使用 QR 分解等更稳定的矩阵算法。
下面用一个小模拟比较三种写法。第一种是直接照公式求逆,第二种是解正规方程,第三种使用 QR 分解。
set.seed(2026)
n <- 500
p <- 20
X <- cbind(1, matrix(rnorm(n * p), n, p))
beta <- c(1, runif(p, -1, 1))
y <- as.vector(X %*% beta + rnorm(n))
beta_inverse <- solve(t(X) %*% X) %*% t(X) %*% y
beta_normal <- solve(crossprod(X), crossprod(X, y))
beta_qr <- qr.coef(qr(X), y)
head(cbind(
inverse = beta_inverse,
normal_equation = beta_normal,
qr = beta_qr
))
#> qr
#> [1,] 1.02395 1.02395 1.02395
#> [2,] -0.30539 -0.30539 -0.30539
#> [3,] -0.33121 -0.33121 -0.33121
#> [4,] 0.89234 0.89234 0.89234
#> [5,] 0.37613 0.37613 0.37613
#> [6,] 0.03115 0.03115 0.03115在这个例子中,三种方法给出的结果非常接近。但当自变量之间高度相关时,差别就会明显起来。
W <- cbind(X, X[, 2] + rnorm(n, sd = 1e-12))
try(solve(crossprod(W), crossprod(W, y)))
#> [,1]
#> [1,] 1.02395
#> [2,] 10.38623
#> [3,] -0.33121
#> [4,] 0.89234
#> [5,] 0.37613
#> [6,] 0.03115
#> [7,] -0.48098
#> [8,] -0.96696
#> [9,] -0.58794
#> [10,] 0.86654
#> [11,] -0.46078
#> [12,] -0.49981
#> [13,] -0.03785
#> [14,] -0.44683
#> [15,] -0.81376
#> [16,] 1.03388
#> [17,] -0.71488
#> [18,] 0.08452
#> [19,] 0.64947
#> [20,] -0.69984
#> [21,] 0.77328
#> [22,] -10.69162
tail(qr.coef(qr(W), y))
#> [1] -0.71488 0.08452 0.64947 -0.69984 0.77328 NA直接求解正规方程可能因为矩阵接近奇异而失败;QR 分解则可以给出更有信息量的结果,并用 NA 标出无法稳定估计的系数。这个例子说明,统计公式给出的是目标,数值线性代数决定了实现路径。
1.5 例子:没有解析解时怎么办
许多统计推断问题并没有简单解析解。极大似然估计中,我们希望求解
\[ \frac{\partial \ell(\theta)}{\partial \theta}=0, \]
但除了少数简单模型外,这个方程很少能手工解出。实际工作中,我们往往需要 Newton-Raphson、BFGS、随机梯度下降等优化算法。算法是否收敛、初值是否敏感、Hessian 矩阵是否稳定,都会影响最后的估计和推断。
积分问题也类似。假设我们希望计算
\[ E[g(X)] = \int g(x) f(x) dx. \]
如果这个积分不能解析求解,可以使用 Monte Carlo 方法,用随机样本平均值进行近似:
\[ E[g(X)] \approx \frac{1}{N}\sum_{i=1}^N g(X_i), \quad X_i \sim f(x). \]
例如,当 \(X\sim N(0,1)\) 时,理论上 \(E(X^2)=1\)。我们可以用模拟来近似这个结果:
这个估计值不会恰好等于 1,因为它包含 Monte Carlo 误差。但随着样本量增加,估计会逐渐稳定。这种“用随机模拟实现统计推断”的思想,是后续 Monte Carlo、Bootstrap 和 MCMC 方法的共同基础。
1.6 统计计算中的三类误差
在实际数据分析中,结果与真实值之间存在差异,并不一定意味着模型错了或程序错了。计算统计要求我们区分不同来源的误差。
第一类是统计误差。即使计算完全精确,我们也只能观察到有限样本。样本均值不一定等于总体均值,回归系数估计不一定等于真实参数,这些差异来自数据本身的随机性。标准误、置信区间和后验不确定性主要刻画的就是这类误差。
第二类是数值误差。计算机使用有限精度浮点数,矩阵运算、函数求值和迭代算法都可能受到舍入误差、下溢、上溢和病态矩阵的影响。直接计算 \((X^\top X)^{-1}X^\top y\)、直接相乘大量小概率、或者在接近奇异的矩阵上求解线性方程,都可能产生数值不稳定。
第三类是模拟误差。当我们用 Monte Carlo、Bootstrap 或 MCMC 方法近似某个量时,结果会受到模拟次数的影响。模拟次数越多,误差通常越小,但计算成本也越高。因此,模拟方法不仅要给出一个估计值,还要评估这个估计值本身的 Monte Carlo 误差。
这三类误差常常交织在一起。一个预测结果不稳定,可能是样本太小,也可能是模型矩阵病态,还可能是模拟次数不足。学会分辨误差来源,是计算统计训练中的重要能力。
1.7 计算统计的基本问题
从上面的例子可以看出,计算统计至少包含以下几类基本问题。
第一,数值表示与稳定性。计算机中的数字不是数学上的实数,浮点误差、上溢、下溢和病态矩阵都可能改变统计结论。对数概率、标准化、矩阵分解和条件数分析都是为了解决这类问题。
第二,确定性算法。求根、优化、数值积分、矩阵分解和 EM 算法等方法,帮助我们在没有简单公式时完成估计和近似。
第三,随机模拟。当积分、分布或不确定性无法直接计算时,可以通过随机数、Monte Carlo、重采样和 MCMC 方法构造近似推断。
第四,可复现计算。统计分析不仅要算得出,还要能被检查、复现和扩展。R 代码、R Markdown、随机种子、版本管理和规范化的数据分析流程,都是现代统计训练的重要组成部分。
本书后续章节将沿着这条主线展开:先建立 R 与数值计算基础,再讨论确定性算法和随机模拟方法,最后进入统计模型实现和贝叶斯计算。