第 4 章 统计计算中的线性代数方法
4.1 介绍
在计算统计中,线性代数不是一门只用来证明定理的背景课程,而是把统计模型真正算出来的基本语言。只要数据被整理成表格,就已经可以看作一个矩阵;回归模型中的设计矩阵、协方差矩阵、转移概率矩阵、网络邻接矩阵,以及文本和图像的数值表示,也都离不开矩阵。对经济统计专业的学生来说,很多熟悉的问题其实都可以改写成矩阵计算问题:估计一组回归系数,比较多个变量的共同变化,压缩一张图片,或者判断网页、城市、产业部门之间的相互影响。
本章的目标不是重新讲授线性代数课程中的全部概念,而是从计算统计的角度回答一个更实际的问题:当一个统计问题写成矩阵形式以后,怎样才能算得快、算得稳、算得清楚?第 3 章已经讨论过,数学公式可以是正确的,但直接照公式计算未必可靠。线性代数中也有同样的情况。比如,线性回归的最小二乘估计常被写成
\[ \hat\beta = (X^\top X)^{-1}X^\top y. \]
这个公式帮助我们理解估计量的结构,但在实际计算中,通常不建议先显式求出逆矩阵再相乘。更稳妥的做法是使用矩阵分解或专门的线性方程组算法。R 中的 lm()、qr.solve() 等函数背后就体现了这种思想:统计计算不只是“把公式翻译成代码”,还要选择合适的数值方法。
在后续章节中,矩阵方法会反复出现。优化算法需要梯度、Hessian 矩阵和线性近似;Monte Carlo 模拟中常要处理协方差矩阵和相关结构;贝叶斯计算中,正态模型、层级模型和多参数后验分布都离不开矩阵运算。因此,理解本章内容,会让后面的优化、模拟和模型实现更容易读懂。
本章主要介绍四类工具。
- 特征分解:帮助我们理解一个矩阵的主要方向、长期状态和稳定结构。例如,PageRank 可以看作在网页链接网络上的长期状态计算。
- 奇异值分解:适用于更一般的矩阵,是降维、低秩近似、图像压缩和搜索排序中的核心工具。
- 幂方法与 QR 思想:展示大规模矩阵计算中常见的迭代思路。数据规模很大时,我们往往不追求一次性“精确算完”,而是通过稳定的迭代逐步逼近目标。
- 应用案例:通过 PageRank 和 SVD 搜索案例,把抽象矩阵方法放回真实的数据问题中。
阅读本章时,可以暂时把重点放在“每种分解解决什么问题”和“为什么这样计算更可靠”上,而不必一开始就纠结所有证明细节。能够用 R 识别矩阵对象、调用合适函数、解释计算结果,并知道什么时候要避免直接求逆,就是本章最重要的学习目标。
4.2 特征分解
4.2.1 特征分析
理解特征值和特征向量,最好先从“矩阵对向量做了什么”开始。一个 \(n \times n\) 的矩阵 \(A\) 乘以向量 \(x\) 以后,通常会同时改变 \(x\) 的长度和方向。但是有些特殊方向很稳定:矩阵作用以后,向量仍然留在原来的直线上,只是被拉长、压缩或反向。也就是说,
\[ Ax = \lambda x. \]
这里的 \(x\) 称为矩阵 \(A\) 的特征向量(eigenvector),\(\lambda\) 称为对应的特征值(eigenvalue)。如果 \(\lambda > 1\),表示这个方向被放大;如果 \(0 < \lambda < 1\),表示这个方向被压缩;如果 \(\lambda < 0\),表示方向发生反向;如果 \(\lambda = 0\),表示这个方向被压缩到零。
在二维情况下,特征分析(eigenanalysis)可以用图4.1来理解1。
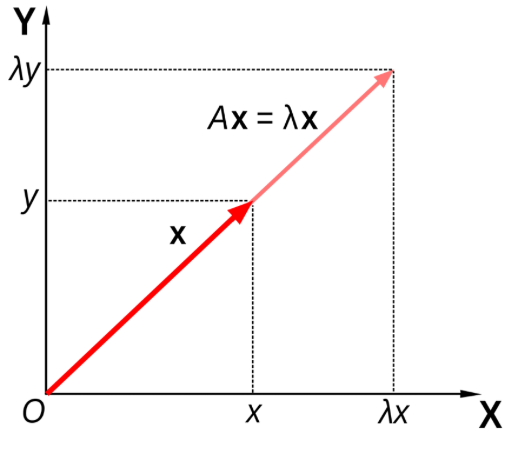
图4.1: 二维矩阵的特征分析
下面用一个很小的例子看 R 如何计算特征值和特征向量。
A <- matrix(c(2, 1,
1, 2), nrow = 2, byrow = TRUE)
eig <- eigen(A)
eig$values
#> [1] 3 1
round(eig$vectors, 3)
#> [,1] [,2]
#> [1,] 0.707 -0.707
#> [2,] 0.707 0.707
v1 <- eig$vectors[, 1]
round(cbind(A_v1 = as.vector(A %*% v1),
lambda_v1 = as.vector(eig$values[1] * v1)), 3)
#> A_v1 lambda_v1
#> [1,] 2.121 2.121
#> [2,] 2.121 2.121最后一行把 \(Av_1\) 和 \(\lambda_1 v_1\) 放在一起比较。两列数相同,说明第一个特征向量确实满足 \(Av_1=\lambda_1v_1\)。需要注意的是,特征向量的符号没有唯一性:如果 \(v\) 是特征向量,那么 \(-v\) 也是同一个特征方向的特征向量。因此,读 R 的输出时,不要过度解释正负号本身,而要关注它代表的方向。
在统计问题中,这种“特殊方向”非常有用。例如,协方差矩阵的特征向量可以表示变量共同变化的主要方向,特征值则表示这些方向上方差的大小。后面学习主成分分析、降维和 SVD 时,这个思想会反复出现。
4.2.2 矩阵的特征分解过程
特征分解(eigendecomposition)又称谱分解(spectral decomposition),就是用矩阵的特征值和特征向量重新表示这个矩阵。它的核心思想是:如果我们把坐标系换到由特征向量构成的坐标系里,矩阵 \(A\) 的作用就会变得很简单,只是在每个特征方向上乘以一个数。
如果 \(n \times n\) 的矩阵 \(A\) 具有 \(n\) 个线性独立的特征向量,那么 \(A\) 是可对角化的,此时有
\[A = Q \Lambda Q^{-1},\]
其中 \(Q\) 是由特征向量组成的矩阵,第 \(i\) 列是第 \(i\) 个特征向量 \(q_i\);\(\Lambda\) 是对角矩阵,对角线上的元素是对应的特征值,即 \(\Lambda_{ii}=\lambda_i\)。
这个表达式可以按三个步骤理解:
- \(Q^{-1}\):把原来的向量转换到特征向量坐标系中。
- \(\Lambda\):在每个特征方向上分别乘以对应的特征值。
- \(Q\):把结果转换回原来的坐标系。
因此,特征分解把一个复杂的矩阵变换,拆成了“换坐标、按方向缩放、再换回来”。
如果 \(A\) 是一个 \(n \times n\) 的实对称阵,那么
- \(A\) 的 \(n\) 个特征根都为实数。
- \(A\) 有 \(n\) 个互相正交的特征向量。
因此,实对称矩阵可以写成更简洁的形式:
\[ A = Q \Lambda Q^\top, \]
其中 \(Q\) 是正交矩阵,满足 \(Q^{-1}=Q^\top\)。这一类矩阵在统计中尤其重要,因为协方差矩阵、相关系数矩阵、许多二次型矩阵都是实对称矩阵。
并不是所有矩阵都能漂亮地写成 \(A=Q\Lambda Q^{-1}\)。如果矩阵不能对角化,数值软件通常会使用 Schur 分解等更一般的方法,把矩阵转化为上三角或准上三角形式。本章不展开 Schur 分解的细节,只需要记住:特征分解是理解矩阵结构的重要工具,但实际计算中还会根据矩阵性质选择更稳定的数值方法。
4.2.3 特征分解可以帮助我们做什么?
理解矩阵幂与长期行为
特征分解最直接的好处,是让矩阵的高次幂变得容易理解。若 \(A = Q\Lambda Q^{-1}\),则
\[ A^k = Q\Lambda^k Q^{-1}. \]
因为 \(\Lambda\) 是对角矩阵,所以 \(\Lambda^k\) 只需要把每个特征值分别做 \(k\) 次方即可。以 \(A^{20}\) 为例:
\[ A^{20} = Q\Lambda^{20}Q^{-1}. \]
这在 Markov 链、人口转移、产业结构转移、网页排序等问题中很常见:如果一个状态不断被同一个矩阵更新,那么长期行为往往由最大的几个特征值及其对应的特征向量决定。
理解逆矩阵与数值稳定性
如果 \(A\) 可对角化,并且所有特征值都不为 0,那么
\[ A^{-1} = Q\Lambda^{-1} Q^{-1}. \]
这里 \(\Lambda^{-1}\) 只需要把每个非零特征值取倒数。这个公式提醒我们:如果某些特征值非常接近 0,那么它们的倒数会非常大,计算结果就容易对误差极其敏感。在线性回归中,多重共线性常常就表现为 \(X^\top X\) 的某些特征值很小。
因此,在统计计算里,特征分解不仅可以帮助我们“算”,还可以帮助我们判断一个问题是否容易算。实际编程时,通常应优先使用 solve(A, b)、qr.solve()、Cholesky 分解、QR 分解或 SVD 等方法求解线性方程组,而不是先显式计算 solve(A) 再相乘。
4.3 奇异值分解
特征分解很有用,但它有一个明显限制:它主要针对方阵,而且并不是每个方阵都能被良好地对角化。实际统计数据却常常不是方阵。比如,\(n\) 个样本、\(p\) 个变量构成的数据矩阵通常是 \(n \times p\) 的;一张灰度图像可以看作“像素行数 \(\times\) 像素列数”的矩阵;文本–词频矩阵、用户–商品评分矩阵也往往是长方形矩阵。
这时,奇异值分解(singular value decomposition,SVD)就登场了。SVD 可以用于任意实矩阵,是统计计算中最重要、最稳定的矩阵分解工具之一。它可以帮助我们理解矩阵的秩、判断病态程度、做降维、做低秩近似,也可以作为最小二乘、主成分分析和推荐系统等方法的计算基础。
从几何上看,SVD 把一个矩阵变换拆成三步:
- 先在输入空间中旋转或反射坐标轴;
- 再沿若干个互相垂直的方向进行伸缩;
- 最后在输出空间中再旋转或反射一次。
其中“伸缩”的大小就是奇异值。奇异值越大,说明矩阵在对应方向上的作用越强;奇异值越小,说明对应方向上的信息越弱,甚至可能主要是噪声。
4.3.1 奇异值和奇异向量
设 \(A\) 是一个 \(m \times n\) 的矩阵。奇异值 \(\sigma\) 是矩阵 \(A^\top A\) 的非负特征值的平方根。与奇异值对应的两类向量分别称为右奇异向量(right singular vector)和左奇异向量(left singular vector)。
如果 \(\sigma_j>0\),对应的右奇异向量为 \(v_j\),左奇异向量为 \(u_j\),那么它们满足
\[A v = \sigma u.\]
更具体地说,
\[ A v_j = \sigma_j u_j,\qquad A^\top u_j = \sigma_j v_j. \]
这里 \(v_j\) 是输入空间中的方向,\(u_j\) 是输出空间中的方向,\(\sigma_j\) 则告诉我们:矩阵 \(A\) 会把 \(v_j\) 这个方向映射到 \(u_j\) 这个方向,并把长度放大为原来的 \(\sigma_j\) 倍。
4.3.2 奇异值分解
对于任意矩阵 \(A \in \mathbb{R}^{m \times n}\),令 \(p=\min\{m,n\}\),则存在正交矩阵
\[ U = [u_1,\ldots,u_m] \in \mathbb{R}^{m\times m} \]
和
\[ V = [v_1,\ldots,v_n] \in \mathbb{R}^{n\times n}, \]
使得
\[\begin{equation} U^\top A V = \Sigma, \tag{4.1} \end{equation}\]
也就是
\[\begin{equation} A = U\Sigma V^\top. \tag{4.2} \end{equation}\]
其中 \(\Sigma \in \mathbb{R}^{m\times n}\) 是一个“对角型”矩阵,对角线元素满足
\[ \sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_p \geq 0. \]
\(\sigma_j\) 称为第 \(j\) 个奇异值,\(u_j\) 和 \(v_j\) 分别称为对应的左奇异向量和右奇异向量。
如果矩阵 \(A\) 的秩为 \(r\),即只有 \(r\) 个正的奇异值,那么 SVD 常写成更紧凑的形式:
\[\begin{equation} A = U_r D_r V_r^\top, \tag{4.3} \end{equation}\]其中 \(U_r=[u_1,\ldots,u_r]\),\(V_r=[v_1,\ldots,v_r]\),
\[ D_r=\operatorname{diag}(\sigma_1,\ldots,\sigma_r). \]
这个式子也可以写成外积加和形式:
\[ A=\sum_{j=1}^{r}\sigma_j u_j v_j^\top. \]
这句话很重要:SVD 把一个矩阵拆成若干个简单矩阵的加和,每一项 \(\sigma_j u_j v_j^\top\) 都是一个秩为 1 的矩阵。排在前面的项贡献最大,排在后面的项贡献较小。这正是低秩近似和数据压缩能够成立的原因。
下面用 R 计算一个小矩阵的 SVD,并验证 \(A=U\Sigma V^\top\)。
A <- matrix(c(3, 2,
2, 3,
1, 1), nrow = 3, byrow = TRUE)
s <- svd(A)
s$d
#> [1] 5.196 1.000
A_reconstructed <- s$u %*% diag(s$d) %*% t(s$v)
round(A_reconstructed, 6)
#> [,1] [,2]
#> [1,] 3 2
#> [2,] 2 3
#> [3,] 1 1重构得到的矩阵与原矩阵相同,只是由于浮点数计算,输出中可能出现极小的舍入误差。R 中 svd() 返回的 d 是奇异值,u 是左奇异向量矩阵,v 是右奇异向量矩阵。对于长方形矩阵,R 默认返回的是紧凑形式,通常已经足够用于统计计算。
4.3.3 奇异值分解的一些性质
SVD 的几个性质值得记住。
- \(A\) 的非零奇异值是 \(A^\top A\) 和 \(AA^\top\) 的非零特征值的平方根。
- \(A\) 的秩等于其非零奇异值的个数。
- 若 \(A\) 是中心化后的数据矩阵,则 \(A^\top A\) 与样本协方差矩阵只差一个常数倍。因此,SVD 与主成分分析有直接关系。
- 如果奇异值下降很快,说明矩阵中的主要信息可以用少数几个方向概括;如果很多奇异值都不小,说明数据结构更复杂,难以用低维结构解释。
- 矩阵的病态程度可以用条件数(condition number)\(\kappa\) 来衡量:
\[ \kappa(A) = \frac{\sigma_{\max}}{\sigma_{\min}}, \]
其中 \(\sigma_{\max}\) 是最大奇异值,\(\sigma_{\min}\) 是最小的非零奇异值。条件数越大,矩阵越接近奇异,相关计算越容易受到舍入误差和数据扰动的影响。
4.4 奇异值分解的应用
4.4.1 矩阵的低秩估计
根据公式 (4.3),\(A\) 可以写成外积加和形式:
\[ A = \sum_{i=1}^r \sigma_i u_i v_i^\top = \sigma_1 u_1 v_1^\top + \cdots + \sigma_r u_r v_r^\top. \]
如果只保留前 \(k\) 项,\(1 \leq k < r\),就得到秩为 \(k\) 的近似矩阵:
\[ A_k = \sum_{i=1}^k \sigma_i u_i v_i^\top = \sigma_1 u_1 v_1^\top + \cdots + \sigma_k u_k v_k^\top. \]
如果后面的奇异值 \(\sigma_{k+1},\ldots,\sigma_r\) 很小,那么 \(A\) 和 \(A_k\) 的差别也会很小。在谱范数意义下,最优秩 \(k\) 近似的误差为
\[ \|A-A_k\|_2=\sigma_{k+1}. \]
这说明:当奇异值快速下降时,用少数几个方向就能保留矩阵的主要信息。
4.4.2 图像压缩
图像压缩是理解低秩近似的好例子。一张灰度图像可以看作一个矩阵:矩阵中的每个元素表示一个像素点的灰度值。若原图像对应一个 \(m\times n\) 的矩阵 \(A\),直接存储需要 \(mn\) 个数。若用秩为 \(k\) 的近似矩阵
\[ A_k = U_k D_k V_k^\top \]
来表示,则只需要存储 \(U_k\)、\(D_k\) 和 \(V_k\),大约需要
\[ mk+k+nk=k(m+n+1) \]
个数。当 \(k\) 远小于 \(m\) 和 \(n\) 时,存储量会明显下降。如果前几个奇异值已经保留了图像的大部分信息,那么压缩后的图像看起来仍然比较清楚。
例4.1 基于矩阵的低秩近似对以下图片进行压缩。

library(jpeg)
ykang <- readJPEG('./figs/ykang.jpg')
r <- ykang[,,1]
g <- ykang[,,2]
b <- ykang[,,3]
ykang.r.svd <- svd(r)
ykang.g.svd <- svd(g)
ykang.b.svd <- svd(b)
rgb.svds <- list(ykang.r.svd, ykang.g.svd, ykang.b.svd)
for (j in seq.int(4, 200, length.out = 8)) {
a <- sapply(rgb.svds, function(i) {
ykang.compress <-
i$u[,1:j] %*%
diag(i$d[1:j]) %*%
t(i$v[,1:j])
}, simplify = 'array')
writeJPEG(a, paste('./figs/', 'ykang_svd_rank_',
round(j,0), '.jpg', sep=''))
}以下三张压缩后的图像对应的秩分别为 200、116 和 32。比较它们的清晰程度,可以直观看到:秩越高,保留的信息越多;秩越低,压缩越强,但细节损失也越明显。
![]()
![]()
![]()
读者可以思考:如果原图像大小为 \(m\times n\),当 \(k=32\) 时,\(k(m+n+1)\) 是否小于 \(mn\)?如果小很多,为什么图像仍能保留主要轮廓?
4.4.3 伪逆
在线性回归中,我们常写最小二乘估计为
\[ \hat\beta=(X^\top X)^{-1}X^\top y. \]
这个公式要求 \(X^\top X\) 可逆。但在实际数据中,可能出现变量完全共线、变量数多于样本数,或者设计矩阵不是满秩等情况。此时普通逆矩阵不存在,伪逆(pseudoinverse)就提供了一种更一般的解决办法。
如果 \(A\) 的紧凑 SVD 为
\[ A = U_rD_rV_r^\top, \]
则 \(A\) 的 Moore–Penrose 伪逆定义为
\[ A^+ = V_rD_r^{-1}U_r^\top. \]
其中 \(D_r^{-1}\) 是把所有非零奇异值取倒数组成的对角矩阵。伪逆可以用于求解最小二乘问题
\[ \min_x \|Ax-b\|_2^2. \]
当方程有唯一最小二乘解时,\(x=A^+b\) 与通常的最小二乘解一致;当解不唯一时,伪逆给出欧氏长度最小的那个解。
下面用 R 写一个简单的伪逆函数。
pinv <- function(A, tol = sqrt(.Machine$double.eps)) {
s <- svd(A)
keep <- s$d > tol * max(s$d)
s$v[, keep, drop = FALSE] %*%
diag(1 / s$d[keep], nrow = sum(keep)) %*%
t(s$u[, keep, drop = FALSE])
}
x <- c(1, 2, 3, 4)
y <- c(1.1, 1.9, 3.2, 3.9)
X <- cbind(1, x)
coef_pinv <- pinv(X) %*% y
coef_qr <- qr.solve(X, y)
round(cbind(pinv = coef_pinv, qr = coef_qr), 4)
#> qr
#> 0.10 0.10
#> x 0.97 0.97在这个简单例子中,伪逆解和 QR 分解得到的最小二乘解相同。实际建模时,R 的 lm() 内部使用更稳定的线性代数算法,不需要我们手工写伪逆;但理解伪逆有助于理解为什么 SVD 可以处理秩亏或近似秩亏的问题。
4.4.4 曲线拟合
曲线拟合可以看作线性代数在统计建模中的一个直接应用。假设我们希望用二次多项式拟合一组数据:
\[ y_i \approx \beta_0+\beta_1x_i+\beta_2x_i^2. \]
把所有样本放在一起,就可以写成矩阵形式:
\[ y \approx X\beta, \]
其中 \(X\) 的第 \(i\) 行为 \((1,x_i,x_i^2)\)。这样,曲线拟合就转化成了最小二乘问题。
set.seed(123)
x <- seq(-1, 1, length.out = 30)
y <- 1 + 2 * x - 1.5 * x^2 + rnorm(length(x), sd = 0.15)
X <- cbind(1, x, x^2)
beta_hat <- qr.solve(X, y)
round(beta_hat, 3)
#> x
#> 0.984 1.946 -1.475
x_grid <- seq(min(x), max(x), length.out = 200)
X_grid <- cbind(1, x_grid, x_grid^2)
y_hat <- as.vector(X_grid %*% beta_hat)
plot(x, y, pch = 19, col = "gray40",
xlab = "x", ylab = "y")
lines(x_grid, y_hat, col = "steelblue", lwd = 2)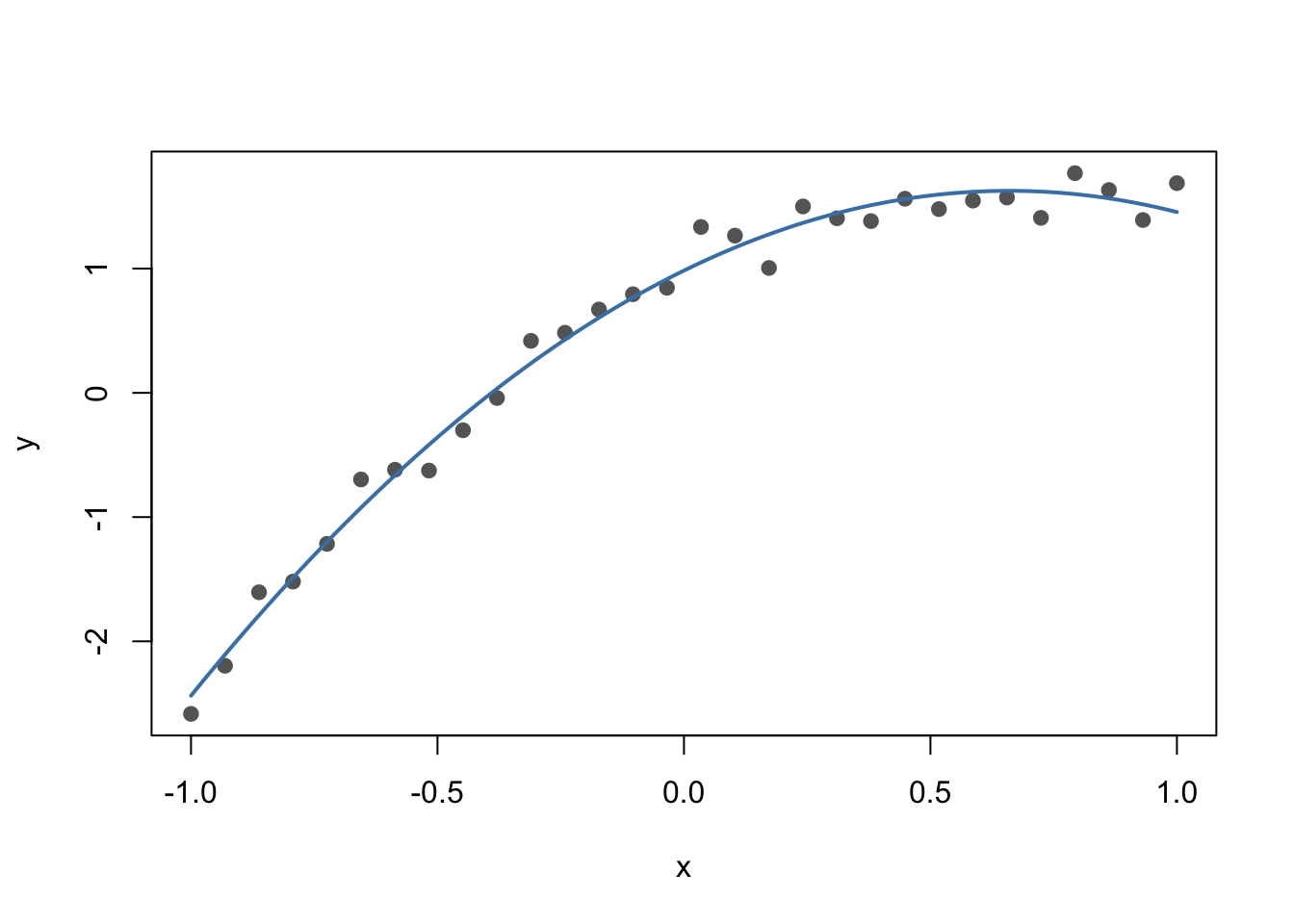
图4.2: 用二次多项式进行曲线拟合
这个例子提醒我们:很多“统计模型”的计算核心其实是矩阵问题。真正编程时,我们通常使用 qr.solve()、lm() 或其他稳定算法求解,而不是直接计算 \((X^\top X)^{-1}X^\top y\)。当多项式次数很高时,设计矩阵可能变得病态,这时 SVD、QR 分解、中心化和标准化都会变得重要。
4.5 数值方法
在小矩阵中,我们可以直接调用 eigen() 或 svd()。但在大规模问题中,矩阵可能有上万甚至上百万行列,直接分解整个矩阵不仅慢,而且可能没有必要。例如,PageRank 只关心最重要的特征向量;低秩近似只关心前几个最大的奇异值。此时,迭代算法就非常重要。
迭代算法的思想是:从一个初始猜测出发,反复进行简单计算,让结果逐步接近目标。当变化已经足够小时,就停止迭代。下面介绍两个经典思想:幂方法和 QR 算法。
4.5.1 幂方法(Power method)
幂方法是计算矩阵最大绝对值特征值及其对应特征向量的经典方法。它背后的想法非常直接:如果不断用矩阵 \(A\) 去乘一个向量,那么在很多情况下,向量的方向会逐渐靠近主特征向量的方向。
对于一个 \(n \times n\) 的矩阵 \(A\),如果 \(q\) 是其对应于特征值 \(\lambda\) 的特征向量,那么 \(Aq = \lambda q\)。进一步有
\[ A^kq = \lambda^kq. \]
假设 \(A\) 有 \(n\) 个线性独立的特征向量 \(q_1,\ldots,q_n\),其特征值满足
\[ |\lambda_1| > |\lambda_2| \geq \cdots \geq |\lambda_n|. \]
如果初始向量 \(x_0\) 在 \(q_1\) 方向上的分量不为 0,则可以写成
\[ x_0 = c_1 q_1+\cdots+c_nq_n,\qquad c_1\neq 0. \]
连续左乘 \(A\),得到
\[\begin{align*} A^kx_0 & = c_1 \lambda_1^k q_1 + \cdots + c_n\lambda_n^kq_n,\\ & = \lambda_1^k\left\{c_1q_1+\sum_{i=2}^n c_i\left(\frac{\lambda_i}{\lambda_1}\right)^kq_i\right\}. \end{align*}\]
由于 \(|\lambda_i/\lambda_1|<1\),当 \(k\) 增大时,后面的分量会逐渐衰减,\(A^kx_0\) 的方向就会越来越接近 \(q_1\)。
不过,\(A^kx_0\) 的长度可能越来越大或越来越小,而我们真正关心的是方向。因此实践中通常使用标准化的幂方法。
标准化的幂方法
选择一个初始向量 \(x_0\),令 \(q_0=x_0/\|x_0\|_2\)。
对于 \(k = 1,2,\ldots\) 重复以下过程:
- 计算 \(z_k = Aq_{k-1}\);
- 标准化 \(q_k=z_k/\|z_k\|_2\);
- 计算 \(\lambda_k=q_k^\top A q_k\);
- 如果 \(\lambda_k\) 或 \(q_k\) 的变化已经足够小,则停止。
下面给出一个简单实现。
power_method <- function(A, max_iter = 1000, tol = 1e-10) {
q <- rep(1, nrow(A))
q <- q / sqrt(sum(q^2))
lambda_old <- 0
for (iter in seq_len(max_iter)) {
z <- A %*% q
q <- as.vector(z / sqrt(sum(z^2)))
lambda <- as.numeric(t(q) %*% A %*% q)
if (abs(lambda - lambda_old) < tol) break
lambda_old <- lambda
}
list(value = lambda, vector = q, iter = iter)
}
A <- matrix(c(2, 1,
1, 2), nrow = 2, byrow = TRUE)
pm <- power_method(A)
pm$value
#> [1] 3
round(pm$vector, 3)
#> [1] 0.707 0.707
eigen(A)$values[1]
#> [1] 3这个例子中,幂方法得到的最大特征值与 eigen() 的结果一致。对于大规模稀疏矩阵,幂方法的优势在于每一步只需要做矩阵–向量乘法,不必完整分解矩阵。
4.5.2 QR 算法
幂方法主要给出最大的特征值和对应特征向量。如果希望计算多个特征值,QR 算法是更系统的方法。它的基础是 QR 分解:任意合适的矩阵 \(A\) 可以写成
\[ A = QR, \]
其中 \(Q\) 是正交矩阵,\(R\) 是上三角矩阵。QR 算法反复执行下面的步骤:
\[ A_k = Q_kR_k,\qquad A_{k+1}=R_kQ_k. \]
由于
\[ A_{k+1}=R_kQ_k=Q_k^\top A_k Q_k, \]
\(A_{k+1}\) 与 \(A_k\) 是相似矩阵,因此每一步都不改变特征值。更准确地说,QR 迭代的目标不是让任意矩阵都必然“变成”上三角矩阵,而是通过一系列正交相似变换逼近矩阵的 Schur 形式。对一些典型情形,例如可对角化、特征值模长可以分离且满足非退化条件的矩阵,未移位 QR 迭代会使 \(A_k\) 的下三角部分逐渐变小,对角线元素趋近于特征值。若 \(A\) 是实对称矩阵,这个极限形式通常可以理解为对角矩阵;若 \(A\) 是一般实矩阵,极限形式更自然地表述为实 Schur 形式,即准上三角矩阵,其中 \(2\times2\) 小块对应复共轭特征值。
A <- matrix(c(4, 1,
1, 3), nrow = 2, byrow = TRUE)
Ak <- A
for (i in 1:20) {
qr_A <- qr(Ak)
Q <- qr.Q(qr_A)
R <- qr.R(qr_A)
Ak <- R %*% Q
}
round(diag(Ak), 6)
#> [1] 4.618 2.382
round(eigen(A)$values, 6)
#> [1] 4.618 2.382这个例子选用的是实对称矩阵,因此迭代结果表现为逐渐接近对角矩阵,对角线元素接近特征值。实际数值软件中的 QR 算法会加入移位(shift)、Hessenberg 化等技巧,以提高速度和稳定性。对本科阶段而言,重要的是理解:现代矩阵计算并不是通过求特征多项式来得到特征值,而是依靠稳定的矩阵分解和迭代算法。
4.6 案例:PageRank 算法
PageRank 是特征向量思想在网络排序中的经典应用。它最初用于网页排序:如果一个网页被很多重要网页链接,那么这个网页也应该更重要。这个想法可以推广到很多网络问题中,例如企业供应链网络、投入产出网络、城市交通网络和学术引用网络。
基本思想
PageRank 可以理解为一种“加权投票”。网页上的超链接就是选票:如果页面 \(i\) 链接到 \(m\) 个页面,那么它把自己的重要性平均分给这 \(m\) 个页面,每个链接得到 \(1/m\) 的权重。重要页面投出的票,比不重要页面投出的票更有分量。
举例来说,假如有五个页面,它们之间的链接关系如图 4.3 所示。
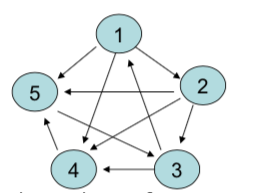
图4.3: 仅有五个页面的链接关系示例。
用邻接矩阵 \(A\) 表示链接关系,矩阵第 \(i\) 行第 \(j\) 列为 1 表示页面 \(i\) 链接到页面 \(j\):
\[ A=\left(\begin{array}{ccccc} 0 & 1 & 0 & 1 & 1 \\ 0 & 0 & 1 & 1 & 1 \\ 1 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 \end{array}\right). \]
把每一行除以该页面的出链数量,得到转移矩阵 \(B\):
\[ B=\left(\begin{array}{ccccc} 0 & 1/3 & 0 & 1/3 & 1/3 \\ 0 & 0 & 1/3 & 1/3 & 1/3 \\ 1/2 & 0 & 0 & 1/2 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 \end{array}\right). \]
设页面重要性得分为行向量
\[ r=(r_1,r_2,r_3,r_4,r_5). \]
如果网页重要性已经达到稳定状态,那么一次链接转移以后,重要性分布不应改变,即
\[ r = rB. \]
两边转置可得
\[ r^\top = B^\top r^\top. \]
因此,PageRank 得分就是 \(B^\top\) 对应特征值 1 的特征向量。换句话说,网页排序问题被转化成了一个特征向量计算问题。
R 实现
A <- matrix(c(
0, 1, 0, 1, 1,
0, 0, 1, 1, 1,
1, 0, 0, 1, 0,
0, 0, 0, 0, 1,
0, 0, 1, 0, 0
), nrow = 5, byrow = TRUE)
B <- sweep(A, 1, rowSums(A), "/")
er <- eigen(t(B))
idx <- which.min(Mod(er$values - 1))
r <- Re(er$vectors[, idx])
r <- r / sum(r)
names(r) <- paste0("page", 1:5)
round(r, 3)
#> page1 page2 page3 page4 page5
#> 0.150 0.050 0.300 0.217 0.283
sort(round(r, 3), decreasing = TRUE)
#> page3 page5 page4 page1 page2
#> 0.300 0.283 0.217 0.150 0.050这里先构造行随机矩阵 \(B\),再计算 \(B^\top\) 的特征向量。得分越高,页面越重要。
从幂方法看 PageRank
如果从随机游走的角度看,PageRank 更容易理解。假设一个用户一开始随机进入五个网页之一,因此初始分布为
\[ r_0=\left(\frac15,\frac15,\frac15,\frac15,\frac15\right). \]
用户每次都随机点击当前网页中的一个链接,则
\[ r_1=r_0B,\quad r_2=r_1B,\quad \ldots,\quad r_k=r_{k-1}B. \]
当 \(k\) 足够大时,\(r_k\) 会接近稳定分布。这正是幂方法在 PageRank 中的具体形式。
r_iter <- rep(1 / nrow(B), nrow(B))
for (i in 1:100) {
r_next <- as.vector(r_iter %*% B)
if (max(abs(r_next - r_iter)) < 1e-12) break
r_iter <- r_next
}
round(r_iter, 3)
#> [1] 0.150 0.050 0.300 0.217 0.283
i
#> [1] 100实际 PageRank 还会加入阻尼因子(damping factor)。它表示用户并不总是沿着链接点击,也可能随机跳转到任意页面。若阻尼因子为 \(\alpha\),常用形式为
\[ G=\alpha B + (1-\alpha)\frac{1}{N}\mathbf{1}\mathbf{1}^\top, \]
其中 \(N\) 是页面数,\(\mathbf{1}\mathbf{1}^\top/N\) 表示随机跳转到任意页面的概率矩阵。这个修正可以缓解没有出链的页面、封闭小圈子等问题,也能改善迭代收敛性质。
alpha <- 0.85
n <- nrow(B)
G <- alpha * B + (1 - alpha) * matrix(1 / n, nrow = n, ncol = n)
r_damped <- rep(1 / n, n)
for (i in 1:100) {
r_damped <- as.vector(r_damped %*% G)
}
names(r_damped) <- paste0("page", 1:n)
round(r_damped, 3)
#> page1 page2 page3 page4 page5
#> 0.151 0.073 0.285 0.215 0.276在真实互联网规模下,矩阵非常大且高度稀疏,不会真的把整个矩阵密集存储起来。核心计算仍然是反复做矩阵–向量乘法,但会使用稀疏矩阵存储、分布式计算和工程优化来完成。
4.7 案例:SVD 助力互联网搜索
随着互联网文本快速增长,搜索系统需要从海量文档中找到与用户查询最相关的内容。最直接的方法是看查询词是否在文档中出现,但这种方法容易受到同义词、短文本和噪声词的影响。潜在语义分析(latent semantic analysis,LSA)提供了一个经典思路:先把文本集合表示成一个词语–文档矩阵,再用 SVD 提取低维语义结构,最后在低维空间中比较查询和文档的相似度。
LSA 的基本思路如下。
- 构造词语–文档矩阵 \(A\),其中 \(A_{ij}\) 表示词语 \(i\) 在文档 \(j\) 中出现的频数或权重。
- 对 \(A\) 做标准化或 TF–IDF 加权,降低高频但信息量有限的词的影响。
- 对加权矩阵做 SVD,并保留前 \(k\) 个奇异值和奇异向量。
- 把文档和查询都投影到这个 \(k\) 维空间中。
- 用余弦相似度衡量查询和文档的接近程度。
本节使用 Hugging Face 上的中文短新闻标题数据 wyp/clue-tnews2。为了保证本书可以在离线环境下稳定编译,下面代码直接写入一个小的真实样本子集;如果希望重新从 Hugging Face Dataset Viewer API 获取数据,可以参考下面的代码。
url <- paste0(
"https://datasets-server.huggingface.co/rows?",
"dataset=wyp/clue-tnews&config=default&split=validation",
"&offset=0&length=30"
)
hf_rows <- jsonlite::fromJSON(url)数据准备
这里每一条新闻标题看作一个文档。数据中 sentence 是新闻标题,keywords 是关键词,label_desc 是新闻类别。为了把重点放在矩阵计算上,我们直接使用数据集提供的关键词构造词语–文档矩阵,而不展开中文分词问题。
tnews <- data.frame(
id = paste0("D", sprintf("%02d", 1:20)),
label_desc = c(
"entertainment", "military", "finance", "culture", "tech",
"finance", "house", "house", "education", "house",
"tech", "education", "entertainment", "car", "car",
"travel", "military", "tech", "finance", "sports"
),
sentence = c(
"江疏影甜甜圈自拍,迷之角度竟这么好看,美吸引一切事物",
"以色列大规模空袭开始!伊朗多个军事目标遭遇打击,誓言对等反击",
"出栏一头猪亏损300元,究竟谁能笑到最后!",
"走进荀子的世界 触摸二千年前的心灵温度",
"图解:全要素 多领域 高效益 天津智能科技军民融合发展",
"区块链投资心得,能做到就不会亏钱",
"你家拆迁,要钱还是要房?答案一目了然",
"军嫂探亲拧包入住,部队家属临时来队房标准有了规定,全面落实!",
"你好,武汉理工大学国旗仪仗队!",
"海口的限购区域有哪些?",
"“你们的产品让人们越来越懒”——农行董事长为何如此评价?",
"美术生去北京画室参加集训会不会影响联考成绩?",
"心直口快马苏没有选择沉默,疑再回应戛纳风波",
"国产新力量,领克02这个价位你能接受?",
"「曝光台」安塞区这些驾驶员,您的驾驶证违法未处理已经逾期未换证了,赶快去车管所办理相关业务去吧!(第十期)",
"瑟图|走走停停,看不够五渔村浪漫风情",
"全球最大飞机墓地:6千架被埋葬的飞机,可随便装备一个军事强国",
"如何解读蚂蚁金服首季亏损?",
"为什么现在超市购物车要用硬币才能使用,之前都不用的呢,这背后有什么利益吗?",
"霍福德定胜负,凯尔特人客胜76人彩带抢镜,史蒂文斯太强了"
),
keywords = c(
"江疏影,美少女,经纪人,甜甜圈",
"伊朗,圣城军,叙利亚,以色列国防军,以色列",
"商品猪,养猪,猪价,仔猪,饲料",
"荀子导读,韩非子,荀卿,劝学,荀子,中国哲学",
"高效益,天津,智能科技,军民融合",
"机会主义,盲人摸象,比特币,区块链,张大千",
"房价,房产,货币化安置,三四线城市,买房",
"包入住,热水器,空房子,部队家属",
"华中农业大学,武汉理工大学,国旗仪仗队,国旗班",
"二手房,海口市,海口,买房,产权式酒店",
"刘自鸿,中国农业银行,电子技术,柔性,柔宇",
"北京,美术生,省统考,画室,联考",
"马苏,戛纳电影节,霍建起,如影随心",
"国产汽车,领克02,价位",
"安塞区,逾期未,道路交通,驾驶证,车管所",
"小渔村,五渔村,浪漫风情",
"军事强国,飞机墓地,美国,b52,运输机",
"阿里巴巴,支付宝,全球化,蚂蚁金服,网商贷,投入",
"超行业,存包柜,消费秩序,服务性,投币购物车",
"霍福德,贝里内利,凯尔特人,76人,绿衫军"
),
stringsAsFactors = FALSE
)
knitr::kable(tnews[, c("id", "label_desc", "sentence")])| id | label_desc | sentence |
|---|---|---|
| D01 | entertainment | 江疏影甜甜圈自拍,迷之角度竟这么好看,美吸引一切事物 |
| D02 | military | 以色列大规模空袭开始!伊朗多个军事目标遭遇打击,誓言对等反击 |
| D03 | finance | 出栏一头猪亏损300元,究竟谁能笑到最后! |
| D04 | culture | 走进荀子的世界 触摸二千年前的心灵温度 |
| D05 | tech | 图解:全要素 多领域 高效益 天津智能科技军民融合发展 |
| D06 | finance | 区块链投资心得,能做到就不会亏钱 |
| D07 | house | 你家拆迁,要钱还是要房?答案一目了然 |
| D08 | house | 军嫂探亲拧包入住,部队家属临时来队房标准有了规定,全面落实! |
| D09 | education | 你好,武汉理工大学国旗仪仗队! |
| D10 | house | 海口的限购区域有哪些? |
| D11 | tech | “你们的产品让人们越来越懒”——农行董事长为何如此评价? |
| D12 | education | 美术生去北京画室参加集训会不会影响联考成绩? |
| D13 | entertainment | 心直口快马苏没有选择沉默,疑再回应戛纳风波 |
| D14 | car | 国产新力量,领克02这个价位你能接受? |
| D15 | car | 「曝光台」安塞区这些驾驶员,您的驾驶证违法未处理已经逾期未换证了,赶快去车管所办理相关业务去吧!(第十期) |
| D16 | travel | 瑟图|走走停停,看不够五渔村浪漫风情 |
| D17 | military | 全球最大飞机墓地:6千架被埋葬的飞机,可随便装备一个军事强国 |
| D18 | tech | 如何解读蚂蚁金服首季亏损? |
| D19 | finance | 为什么现在超市购物车要用硬币才能使用,之前都不用的呢,这背后有什么利益吗? |
| D20 | sports | 霍福德定胜负,凯尔特人客胜76人彩带抢镜,史蒂文斯太强了 |
构造词语–文档矩阵
下面把每条新闻的关键词拆开,构造词语–文档矩阵。矩阵的行是关键词,列是新闻标题。
split_keywords <- function(x) {
z <- unlist(strsplit(x, ",", fixed = TRUE))
z <- trimws(z)
z[nzchar(z)]
}
tokens <- lapply(tnews$keywords, split_keywords)
vocab <- sort(unique(unlist(tokens)))
tdm <- matrix(
0,
nrow = length(vocab),
ncol = nrow(tnews),
dimnames = list(vocab, tnews$id)
)
for (j in seq_along(tokens)) {
tab <- table(tokens[[j]])
tdm[names(tab), j] <- as.integer(tab)
}
dim(tdm)
#> [1] 92 20
tdm[1:8, 1:6]
#> D01 D02 D03 D04 D05 D06
#> 76人 0 0 0 0 0 0
#> b52 0 0 0 0 0 0
#> 三四线城市 0 0 0 0 0 0
#> 中国农业银行 0 0 0 0 0 0
#> 中国哲学 0 0 0 1 0 0
#> 买房 0 0 0 0 0 0
#> 二手房 0 0 0 0 0 0
#> 五渔村 0 0 0 0 0 0在真实文本数据中,词语–文档矩阵通常非常稀疏:绝大多数词只出现在少数文档中。为了让更有区分度的词获得更高权重,常使用 TF–IDF 加权。这里的样本很小,但仍可以展示基本做法。
SVD 降维
对 TF–IDF 矩阵做 SVD:
\[ A \approx U_kD_kV_k^\top. \]
其中 \(U_k\) 描述关键词方向,\(D_kV_k^\top\) 描述文档在低维语义空间中的坐标。
s_tnews <- svd(tdm_tfidf)
k <- 4
U_k <- s_tnews$u[, 1:k, drop = FALSE]
D_k <- diag(s_tnews$d[1:k], nrow = k)
V_k <- s_tnews$v[, 1:k, drop = FALSE]
doc_coord <- V_k %*% D_k
rownames(doc_coord) <- tnews$id
round(s_tnews$d[1:8], 3)
#> [1] 8.209 8.209 7.892 7.494 7.494 7.494 7.494 7.494前几个奇异值反映了文本集合中最主要的共同变化方向。若奇异值下降较快,说明少数几个潜在维度已经概括了相当多的信息。
查询与排序
假设用户查询的是“买房 房价 海口 二手房”。我们先把查询转化成与词语–文档矩阵相同长度的向量,然后投影到 SVD 得到的低维空间中:
make_query <- function(words, vocab, idf) {
q <- numeric(length(vocab))
names(q) <- vocab
hit <- intersect(words, vocab)
q[hit] <- 1
q * idf
}
query_words <- c("买房", "房价", "海口", "二手房")
q <- make_query(query_words, vocab, idf)
query_coord <- matrix(q, nrow = 1) %*% U_k %*% solve(D_k)
round(query_coord, 3)
#> [,1] [,2] [,3] [,4]
#> [1,] 0 0 -0.58 0最后计算查询和各新闻标题在低维空间中的余弦相似度:
cosine <- function(a, b) {
denom <- sqrt(sum(a^2)) * sqrt(sum(b^2))
if (denom == 0) return(NA_real_)
sum(a * b) / denom
}
scores <- apply(doc_coord, 1, function(z) {
cosine(z, as.numeric(query_coord))
})
result <- data.frame(
id = names(scores),
score = as.numeric(scores),
label_desc = tnews$label_desc[match(names(scores), tnews$id)],
sentence = tnews$sentence[match(names(scores), tnews$id)],
row.names = NULL
)
result <- result[order(result$score, decreasing = TRUE), ]
knitr::kable(head(result, 6), digits = 3)| id | score | label_desc | sentence | |
|---|---|---|---|---|
| 7 | D07 | 1 | house | 你家拆迁,要钱还是要房?答案一目了然 |
| 10 | D10 | 1 | house | 海口的限购区域有哪些? |
| 4 | D04 | 0 | culture | 走进荀子的世界 触摸二千年前的心灵温度 |
| 18 | D18 | 0 | tech | 如何解读蚂蚁金服首季亏损? |
| 20 | D20 | 0 | sports | 霍福德定胜负,凯尔特人客胜76人彩带抢镜,史蒂文斯太强了 |
| 1 | D01 | NA | entertainment | 江疏影甜甜圈自拍,迷之角度竟这么好看,美吸引一切事物 |
从结果可以看到,与“买房、房价、海口、二手房”相关的房产类新闻排在前面。这个例子当然还很小,但它已经包含了真实搜索问题中的几个核心环节:文本表示、稀疏矩阵、TF–IDF 加权、SVD 降维和相似度排序。
需要注意,LSA 不是现代搜索引擎的全部。真实系统通常还会使用更好的中文分词、停用词处理、倒排索引、点击反馈、机器学习排序模型,甚至深度学习语义向量。但从计算统计的角度看,LSA 非常适合作为入门案例:它清楚展示了如何把非结构化文本转化为矩阵,再用 SVD 提取主要结构。
4.8 本章小结
本章从计算统计的角度介绍了线性代数方法。特征分解帮助我们理解矩阵在关键方向上的作用,也解释了长期状态、稳定分布和 PageRank 等问题。SVD 则把任意矩阵分解为若干个秩为 1 的成分,是低秩近似、图像压缩、伪逆、曲线拟合和文本搜索的重要工具。幂方法和 QR 算法说明,在真实计算中,我们常常依靠稳定的迭代算法,而不是手工求特征多项式。
学习本章时,最重要的不是记住每一个证明细节,而是形成三种计算意识:第一,矩阵公式背后要选择合适的数值算法;第二,奇异值和特征值可以帮助判断问题是否稳定、是否可压缩;第三,很多统计建模任务都可以通过矩阵表示、矩阵分解和迭代计算来完成。
4.9 练习
对矩阵\[ A=\begin{pmatrix} 2 & 1\\ 1 & 2 \end{pmatrix} \]手动求出其特征值和特征向量,并与 R 中
eigen(A)的结果比较。构造一个 \(4\times 3\) 的矩阵,使用
svd()对其进行分解,并验证 \(A=UDV^\top\)。注意 R 默认返回的是紧凑 SVD。对本章图像压缩例子,分别计算 \(k=32,116,200\) 时需要存储的数值个数,并与原图像的 \(mn\) 个数比较。
修改 PageRank 例子中的链接关系,观察最终排序如何变化。哪些页面更容易获得较高排名?
在 TNEWS 的 LSA 例子中,把查询改为“比特币 区块链 投资”或“军事强国 飞机 美国”,重新计算相似度排序,并解释结果。
在 TNEWS 的 LSA 例子中,分别取 \(k=2,4,8\) 个奇异值,比较同一查询下排名前 5 的新闻标题是否发生变化。结合奇异值大小,说明保留维度 \(k\) 如何影响搜索结果。