第 6 章 优化算法
6.1 介绍
上一章讨论的是求根问题:给定一个函数 \(g(x)\),寻找使 \(g(x)=0\) 的位置。这个问题在统计计算中很重要,因为很多估计方程、分位数方程和置信区间端点都可以写成求根形式。本章要处理的问题更进一步:我们不只是要让某个函数等于 0,而是要在许多可能的参数中,找到使目标函数最大或最小的那一个。
在统计建模中,我们经常说“估计一个参数”“拟合一个模型”或“训练一个预测器”。从计算的角度看,这些说法背后常常是同一件事:在一组候选参数中,寻找使某个目标函数最好的一点。这个过程就是优化。一般地,优化问题可以写成
\[ \hat{\theta}=\arg\min_{\theta\in\Theta} Q(\theta), \]
其中 \(\theta\) 表示待估计的参数,\(\Theta\) 表示参数允许取值的范围,\(Q(\theta)\) 是我们希望尽量小的目标函数。如果目标是最大化某个函数,例如最大化对数似然 \(\ell(\theta)\),也可以等价地写成最小化负对数似然 \(-\ell(\theta)\)。
为什么统计计算需要优化算法?一个最直接的原因是,很多统计方法本来就是通过“最优”定义的。最小二乘估计是让残差平方和最小,极大似然估计是让观测数据出现的可能性最大,贝叶斯方法中的后验众数是让后验密度最大,机器学习中的经验风险最小化则是在训练集上寻找损失函数较小的模型。也就是说,优化不是某个额外的计算技巧,而是许多统计方法的基本语言。
在简单问题中,我们有时可以通过代数推导得到闭式解。例如,线性回归的最小二乘估计可以写成矩阵公式。但是,一旦模型稍微复杂,闭式解往往就不存在,或者即使存在也不适合直接计算。逻辑回归的极大似然估计通常没有显式公式,混合模型和隐变量模型的似然函数可能形状复杂,带有惩罚项的模型会引入不可导或约束条件,高维数据下还要考虑计算速度和数值稳定性。此时,我们不能只问“答案是什么公式”,还要问“怎样一步一步把答案算出来”。
这个联系也解释了为什么本章先从牛顿法讲起。上一章的牛顿法用于求解 \(g(x)=0\);如果令\(g(x)=f'(x)\),它就成为优化 \(f(x)\) 的方法。若一元函数 \(f(x)\) 可导,那么求 \(f(x)\) 的极值常常可以转化为求
\[ f'(x)=0. \]
在多元参数问题中,类似地,我们会寻找梯度为零的点。然而,统计建模中的目标函数不一定光滑,也不一定只有一个极值点;参数还可能受到非负性、概率和为 1、预算约束或正则化惩罚的限制。更重要的是,实际数据分析还关心初始值如何选、步长如何定、算法何时停止、结果是否稳定、是否只是局部最优。这些问题共同构成了优化算法的实践部分。
本章关注统计计算中最常用的优化思想。我们先从牛顿法出发,理解如何利用导数和曲率信息加快迭代;然后讨论多元优化问题中的梯度、海塞矩阵和收敛判据;接着介绍不依赖导数的 Nelder–Mead 算法,以及在大样本和机器学习中十分重要的梯度下降和随机梯度下降。最后,我们会通过比较不同算法的表现,并结合真实建模案例,理解优化算法在统计模型计算实现中的作用。
6.2 牛顿优化算法
先考虑一元函数的无约束优化问题。为了叙述方便,本节主要讨论最小化问题:
\[ \min_x f(x). \]
如果要最大化 \(f(x)\),可以等价地最小化 \(-f(x)\)。假设 \(f(x)\) 在感兴趣的区域内二阶可导,并且最优点位于区间内部。若 \(x^\ast\) 是局部极小点,那么通常需要满足一阶条件
\[ f'(x^\ast)=0. \]
这里要注意,“\(f'(x)=0\)”只是内部极值点的必要条件,不是充分条件。它也可能对应局部极大点、拐点,或者在多个驻点中只找到其中一个。因此,牛顿优化算法的核心不是简单地把导数设为 0,而是从一个初始值出发,利用局部导数信息逐步逼近一个合适的驻点。
牛顿法的更新公式可以从二次近似看出来。在当前点 \(x_n\) 附近,用二阶泰勒展开近似 \(f(x)\):
\[ f(x)\approx f(x_n)+f'(x_n)(x-x_n)+\frac{1}{2}f''(x_n)(x-x_n)^2. \]
这个二次函数的极值点满足
\[ f'(x_n)+f''(x_n)(x-x_n)=0. \]
解出 \(x\),就得到牛顿优化算法的迭代公式:
\[ x_{n+1}=x_n-\frac{f'(x_n)}{f''(x_n)}. \]
这个公式有一个直观解释:\(f'(x_n)\) 告诉我们当前位置的斜率,\(f''(x_n)\) 告诉我们函数在当前位置附近弯曲得有多厉害。牛顿法不是只沿着斜率方向走一步,而是利用曲率信息估计“如果局部形状近似为二次函数,极值点应该在哪里”。
牛顿优化算法的基本过程如下。
牛顿优化算法
- 选择初始值 \(x_0\),容忍误差 \(\epsilon\) 和最大迭代次数,设置 \(n=0\)。
- 在当前点计算 \(f'(x_n)\) 和 \(f''(x_n)\)。如果 \(f''(x_n)\) 非常接近 0,需要停止或改用其他方法。
- 按照以下公式更新:
\[ x_{n+1}=x_n-\frac{f'(x_n)}{f''(x_n)}. \]
- 如果 \(|f'(x_{n+1})|\leq \epsilon\),或者迭代已经很少改变结果,则停止;否则令 \(n=n+1\),返回第 2 步。
常见的停止条件包括:
梯度已经足够接近 0:\(|f'(x_n)|<\epsilon\);
相邻两次迭代的参数变化很小:\(|x_n-x_{n-1}|<\epsilon\);
相邻两次迭代的目标函数变化很小:\(|f(x_n)-f(x_{n-1})|<\epsilon\)。
下面用一个简单的极大似然问题说明牛顿优化算法如何出现在统计计算中。设~\(Y_1,\ldots,Y_n\) 来自 Poisson 分布,均值为 \(\lambda\)。为了保证 \(\lambda>0\),令\(\eta=\log\lambda\),即 \(\lambda=\exp(\eta)\)。忽略与参数无关的常数,负对数似然可以写成
\[ Q(\eta)=n\exp(\eta)-\left(\sum_{i=1}^n y_i\right)\eta. \]
对 \(\eta\) 求导得
\[ Q'(\eta)=n\exp(\eta)-\sum_{i=1}^n y_i,\qquad Q''(\eta)=n\exp(\eta). \]
因此,牛顿法可以用来最小化 \(Q(\eta)\),从而得到 \(\lambda\) 的估计。
set.seed(123)
y <- rpois(50, lambda = 3)
n <- length(y)
s <- sum(y)
eta <- log(1)
trace <- data.frame(
iter = 0,
eta = eta,
lambda = exp(eta),
gradient = n * exp(eta) - s
)
for (iter in 1:6) {
grad <- n * exp(eta) - s
hess <- n * exp(eta)
eta <- eta - grad / hess
trace <- rbind(
trace,
data.frame(
iter = iter,
eta = eta,
lambda = exp(eta),
gradient = n * exp(eta) - s
)
)
}
round(trace, 4)
#> iter eta lambda gradient
#> 1 0 0.000 1.000 -105.0000
#> 2 1 2.100 8.166 253.3085
#> 3 2 1.480 4.391 64.5627
#> 4 3 1.186 3.272 8.6265
#> 5 4 1.133 3.104 0.2235
#> 6 5 1.131 3.100 0.0002
#> 7 6 1.131 3.100 0.0000
mean(y)
#> [1] 3.1在这个例子中,\(\exp(\eta)\) 会逐渐接近样本均值。我们当然知道 Poisson 均值的极大似然估计有闭式解 \(\hat\lambda=\bar y\),但这个例子有助于看清牛顿法的计算逻辑:每一步都用当前点的一阶导数和二阶导数修正参数。当模型更复杂、闭式解不存在时,同样的思想仍然可以使用。
牛顿法通常在最优点附近收敛很快,但它也有明显的限制。第一,它依赖初始值;初始值离目标点太远时,迭代可能走向不合适的驻点,甚至发散。第二,它需要二阶导数;在高维问题中,计算和求解海塞矩阵可能很昂贵。第三,如果目标函数不是凸函数,牛顿法找到的往往只是局部最优或某个驻点。因此,实际使用时通常要结合图形检查、多个初始值、步长控制和收敛诊断来判断结果是否可靠。
6.3 多元优化算法
真实统计模型的参数通常不是一个数,而是一个向量。例如,线性回归中有截距和多个回归系数,逻辑回归中每个解释变量都有一个系数,混合模型和层次模型中还会同时包含均值、方差、权重等多类参数。因此,很多统计计算问题都可以写成
\[ \min_{\mathbf{x}\in\mathbb{R}^d} f(\mathbf{x}), \]
其中 \(\mathbf{x}=(x_1,\ldots,x_d)^T\) 是 \(d\) 维参数向量,\(f(\mathbf{x})\) 是目标函数。与一元优化相比,多元优化的困难在于:我们不仅要判断“往左还是往右”,还要判断在高维空间中朝哪个方向移动。
多元优化中最重要的两个对象是梯度和海塞矩阵。梯度向量为
\[ \nabla f(\mathbf{x})= \left( \frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_d} \right)^T. \]
梯度可以理解为目标函数在当前位置上升最快的方向;如果要最小化函数,负梯度方向通常是首先想到的下降方向。海塞矩阵收集了所有二阶偏导数:
\[ \mathbf{H}(\mathbf{x}) =\left[ \frac{\partial^2 f(\mathbf{x})}{\partial x_i\partial x_j} \right]_{i,j=1}^d. \]
它描述的是目标函数在当前位置附近的弯曲程度。若 \(\mathbf{x}^\ast\) 是内部局部极小点,通常需要
\[ \nabla f(\mathbf{x}^\ast)=\mathbf{0}. \]
如果在该点附近海塞矩阵是正定的,即对任意非零向量 \(\mathbf{v}\) 都有\(\mathbf{v}^T\mathbf{H}(\mathbf{x}^\ast)\mathbf{v}>0\),那么目标函数在该点附近呈现“碗形”,这为局部极小提供了更强的证据。
多元牛顿法是上一节一元牛顿法的自然推广。在当前点 \(\mathbf{x}_n\) 附近,用二阶泰勒展开近似\(f(\mathbf{x})\)。令 \(\mathbf{p}=\mathbf{x}-\mathbf{x}_n\),则有
\[ f(\mathbf{x}_n+\mathbf{p}) \approx f(\mathbf{x}_n) +\nabla f(\mathbf{x}_n)^T\mathbf{p} +\frac{1}{2}\mathbf{p}^T\mathbf{H}(\mathbf{x}_n)\mathbf{p}. \]
如果这个二次近似是一个凸的碗形函数,它的最小点满足
\[ \mathbf{H}(\mathbf{x}_n)\mathbf{p}_n=-\nabla f(\mathbf{x}_n). \]
于是我们得到更新公式
\[ \mathbf{x}_{n+1}=\mathbf{x}_n+\mathbf{p}_n. \]
这也是第 4 章线性代数方法在统计计算中的一个典型应用:实际编程时通常不显式计算\(\mathbf{H}^{-1}\),而是求解线性方程组\(\mathbf{H}(\mathbf{x}_n)\mathbf{p}_n=-\nabla f(\mathbf{x}_n)\)。
多元牛顿优化算法
- 选择初始值 \(\mathbf{x}_0\),容忍误差 \(\epsilon\) 和最大迭代次数,设置 \(n=0\)。
- 计算梯度 \(\mathbf{g}_n=\nabla f(\mathbf{x}_n)\) 和海塞矩阵\(\mathbf{H}_n=\mathbf{H}(\mathbf{x}_n)\)。
- 求解线性方程组 \(\mathbf{H}_n\mathbf{p}_n=-\mathbf{g}_n\)。
- 更新 \(\mathbf{x}_{n+1}=\mathbf{x}_n+\mathbf{p}_n\)。
- 若 \(\lVert\mathbf{g}_{n+1}\rVert<\epsilon\) 或\(\lVert\mathbf{x}_{n+1}-\mathbf{x}_n\rVert<\epsilon\),停止;否则令 \(n=n+1\),返回第 2 步。
常见的停止条件包括:
\(\lVert\nabla f(\mathbf{x}_n)\rVert<\epsilon\);
\(\lVert\mathbf{x}_n-\mathbf{x}_{n-1}\rVert<\epsilon\);
\(|f(\mathbf{x}_n)-f(\mathbf{x}_{n-1})|<\epsilon\)。
例6.1 用多元牛顿法最小化
\[ f(x_1,x_2)=x_1^2-x_1x_2+x_2^2+\exp(x_2). \]
这个函数的梯度和海塞矩阵分别为
\[ \nabla f(x_1,x_2)= \begin{pmatrix} 2x_1-x_2\\ -x_1+2x_2+\exp(x_2) \end{pmatrix}, \qquad \mathbf{H}(x_1,x_2)= \begin{pmatrix} 2 & -1\\ -1 & 2+\exp(x_2) \end{pmatrix}. \]
在这个例子中,海塞矩阵始终正定,因此目标函数只有一个局部极小点,也就是全局极小点。下面的 R代码从初始点 \((5,5)\) 出发,记录每次迭代的位置、目标函数值和梯度范数。
optim_f2 <- function(x) {
x[1]^2 - x[1] * x[2] + x[2]^2 + exp(x[2])
}
optim_grad2 <- function(x) {
c(2 * x[1] - x[2],
-x[1] + 2 * x[2] + exp(x[2]))
}
optim_hess2 <- function(x) {
matrix(c(2, -1,
-1, 2 + exp(x[2])),
nrow = 2, byrow = TRUE)
}
newton2d <- function(x0, tol = 1e-8, max_iter = 20) {
x <- x0
path <- data.frame(
iter = 0,
x1 = x[1],
x2 = x[2],
value = optim_f2(x),
grad_norm = sqrt(sum(optim_grad2(x)^2))
)
for (iter in seq_len(max_iter)) {
grad <- optim_grad2(x)
hess <- optim_hess2(x)
step <- solve(hess, -grad)
x <- x + step
grad_new <- optim_grad2(x)
path <- rbind(
path,
data.frame(
iter = iter,
x1 = x[1],
x2 = x[2],
value = optim_f2(x),
grad_norm = sqrt(sum(grad_new^2))
)
)
if (sqrt(sum(grad_new^2)) < tol || sqrt(sum(step^2)) < tol) break
}
path
}
newton_path <- newton2d(c(5, 5))
round(newton_path, 4)
#> iter x1 x2 value grad_norm
#> 1 0 5.0000 5.0000 173.4132 153.4946
#> 2 1 1.9800 3.9600 64.2172 58.3961
#> 3 2 1.4388 2.8777 23.9840 22.0897
#> 4 3 0.8658 1.7316 7.8981 8.2467
#> 5 4 0.2890 0.5781 2.0332 2.6497
#> 6 5 -0.1146 -0.2291 0.8346 0.4515
#> 7 6 -0.2129 -0.4259 0.7892 0.0144
#> 8 7 -0.2163 -0.4326 0.7892 0.0000
#> 9 8 -0.2163 -0.4326 0.7892 0.0000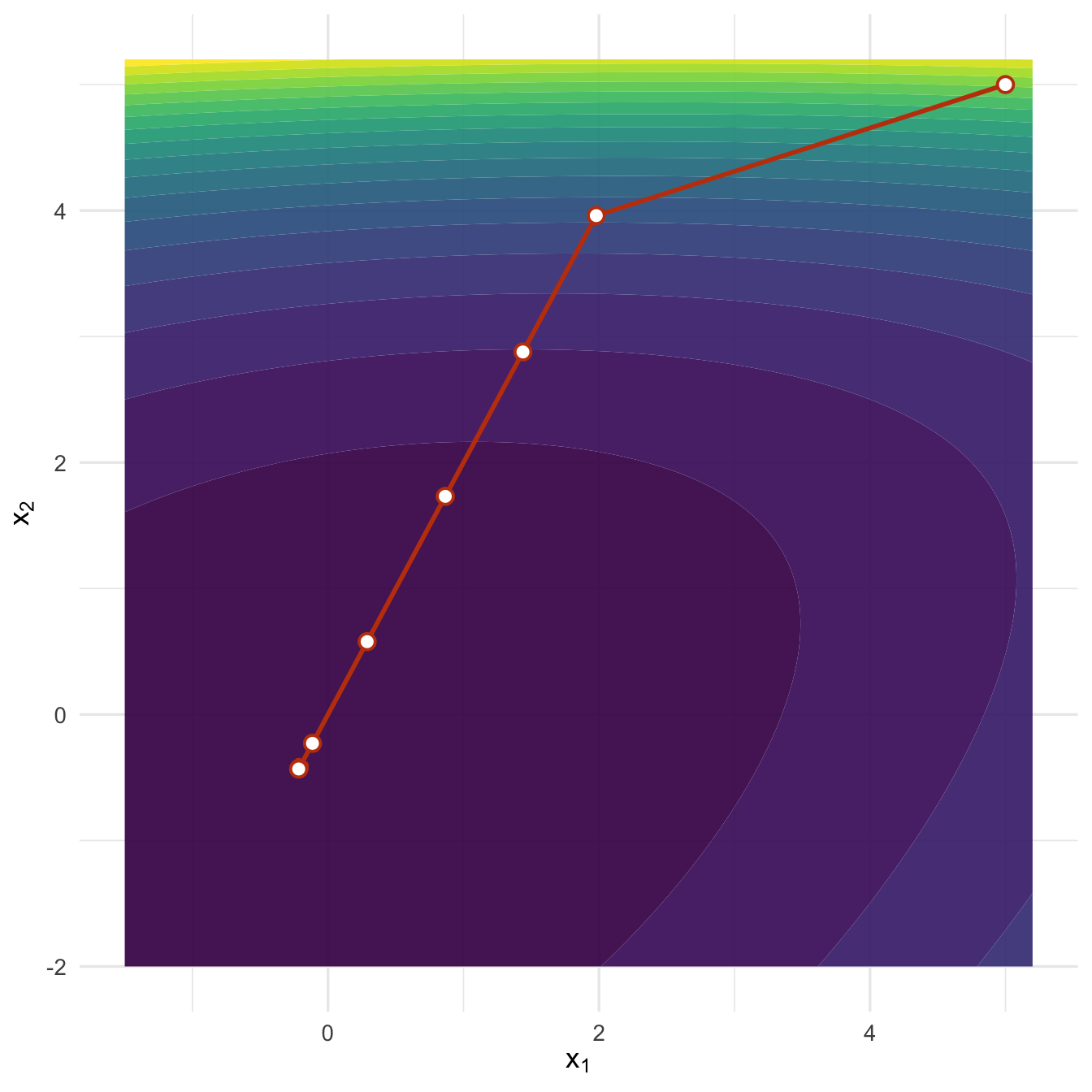
图6.1: 二维牛顿法的迭代路径:红色点从初始值出发,逐步靠近目标函数的极小点。
从表格和图形可以看到,牛顿法前几步移动幅度较大,随后迅速稳定到极小点附近。它之所以快,是因为每一步都使用了梯度和海塞矩阵提供的局部形状信息。
不过,多元牛顿法也需要谨慎使用。若海塞矩阵接近奇异,方程组可能不稳定;若海塞矩阵不是正定的,牛顿方向甚至可能不是下降方向。实际软件中常会加入步长控制,例如使用
\[ \mathbf{x}_{n+1}=\mathbf{x}_n+\alpha_n\mathbf{p}_n,\qquad 0<\alpha_n\leq 1, \]
并通过线搜索选择合适的 \(\alpha_n\)。当梯度或海塞矩阵难以计算时,就需要考虑下一节介绍的不依赖导数的优化方法。
6.4 Nelder–Mead 算法
前两节介绍的牛顿法很有效,但它依赖梯度和海塞矩阵。在实际统计计算中,我们有时只能计算目标函数的值,却很难写出导数。例如,目标函数可能来自一个模拟程序,可能包含排序、中位数、截断规则,也可能把数值积分、内层优化或外部黑箱程序包在里面。此时,仍然希望通过不断试探参数值来降低目标函数,这就需要不依赖导数的优化方法。
Nelder–Mead 算法就是最常用的无导数局部优化算法之一。R 中的 optim() 在没有特别指定方法时,默认使用的也是 Nelder–Mead 方法。需要注意的是,这里的“单纯形”不是线性规划中的单纯形法;它指的是由若干个点构成的几何形状。二维空间中的单纯形是三角形,三维空间中的单纯形是四面体;一般地,在 \(d\) 维空间中,一个单纯形由 \(d+1\) 个顶点构成。
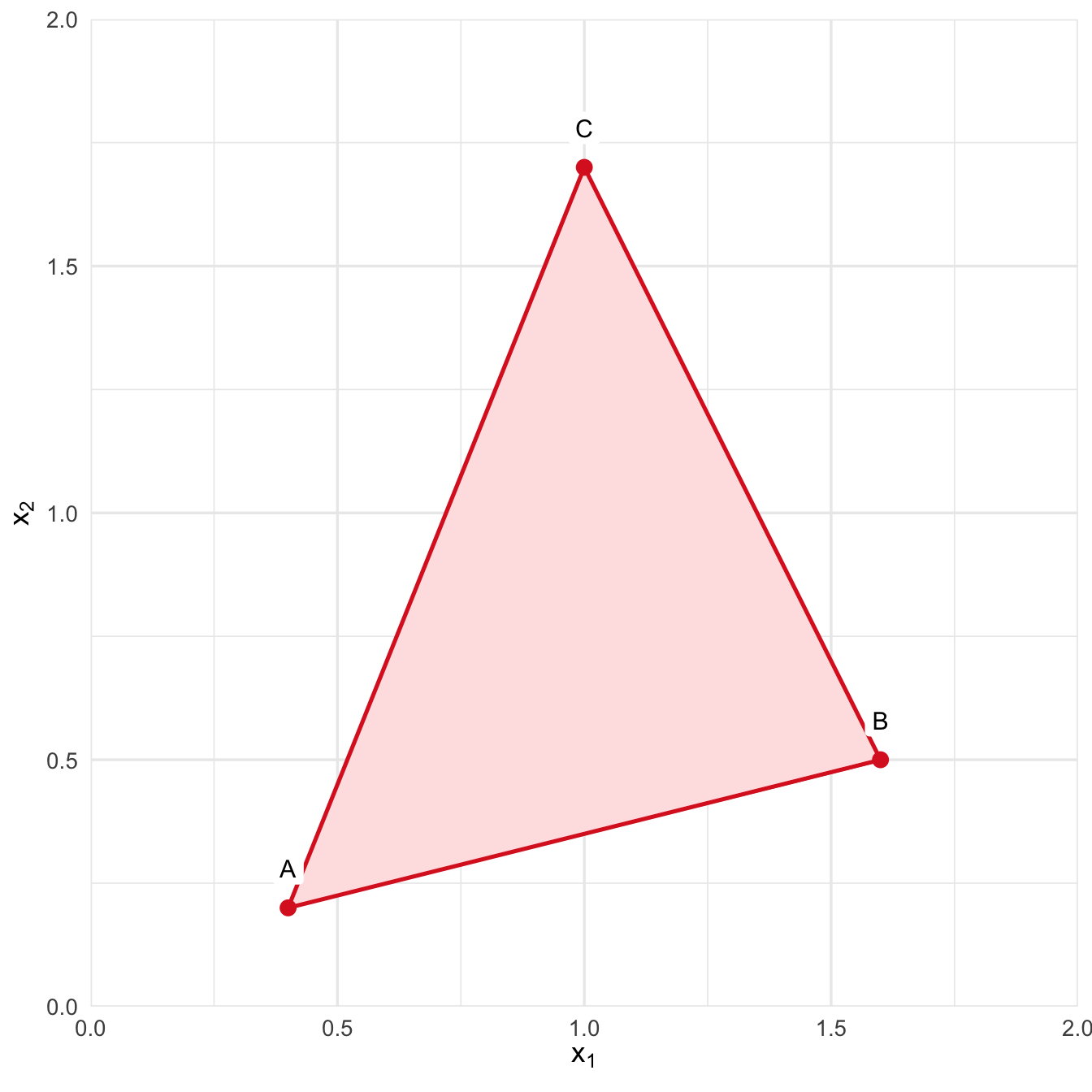
图6.2: 二维单纯形示例:三个顶点构成一个三角形。
Nelder–Mead 算法维护一个单纯形,并在每一步比较这些顶点上的函数值。假设我们要最小化\(f(\mathbf{x})\),当前单纯形的顶点按函数值从小到大排序为
\[ f(\mathbf{v}_1)\leq f(\mathbf{v}_2)\leq \cdots \leq f(\mathbf{v}_{d+1}). \]
其中 \(\mathbf{v}_1\) 是当前最好的点,\(\mathbf{v}_{d+1}\) 是当前最差的点。算法的基本想法很朴素:保留好的点,替换差的点,让单纯形逐渐向函数值更小的区域移动。
Nelder–Mead 算法
- 从 \(d+1\) 个初始顶点构造一个单纯形,并计算每个顶点的函数值。
- 按函数值排序,记最好的点为 \(\mathbf{v}_1\),最差的点为 \(\mathbf{v}_{d+1}\)。
- 去掉最差点,计算其余 \(d\) 个点的中心
\[ \mathbf{c}=\frac{1}{d}\sum_{j=1}^{d}\mathbf{v}_j. \]
- 通过反射、扩张、收缩或压缩来产生新的单纯形。
- 若单纯形已经足够小,或各顶点函数值差异已经足够小,则停止;否则返回第 2 步。
下面说明第 4 步中的几个基本动作。首先把最差点沿着中心 \(\mathbf{c}\) 的另一侧反射出去:
\[ \mathbf{v}_r=\mathbf{c}+\alpha(\mathbf{c}-\mathbf{v}_{d+1}),\qquad \alpha>0. \]
通常取 \(\alpha=1\)。如果反射点比当前最差点好,就可以考虑用它替换最差点。如果反射点甚至比当前最好点还好,算法会沿这个方向继续扩张:
\[ \mathbf{v}_e=\mathbf{c}+\gamma(\mathbf{v}_r-\mathbf{c}),\qquad \gamma>1. \]
常用取值是 \(\gamma=2\)。如果反射没有带来改善,说明这个方向可能走过头了,算法会向中心收缩:
\[ \mathbf{v}_c=\mathbf{c}+\rho(\mathbf{v}_{d+1}-\mathbf{c}),\qquad 0<\rho<1. \]
常用取值是 \(\rho=0.5\)。如果收缩仍然没有改善,说明当前单纯形可能太大或方向不合适,于是把除最好点以外的顶点都向最好点靠拢:
\[ \mathbf{v}_j \leftarrow \mathbf{v}_1+\sigma(\mathbf{v}_j-\mathbf{v}_1),\qquad j=2,\ldots,d+1,\quad 0<\sigma<1. \]
通常取 \(\sigma=0.5\)。这一步称为压缩,它会让搜索范围变小。
图 6.3 展示了 Nelder–Mead 算法优化函数\(f(x_1, x_2) = x_1^2 + x_2^2 + x_1\sin(x_2) + x_2\sin(x_1)\) 的过程。
图6.3: 单纯形法优化动图
图 6.3 展示了二维情形下单纯形如何逐步移动和缩小。和牛顿法不同,Nelder–Mead不需要知道梯度方向;它只是不断比较函数值,并根据“最好点”和“最差点”的相对位置调整单纯形。
实际使用时,停止条件通常不只看迭代次数,还会看两个方面:一是单纯形顶点之间的距离是否已经很小,二是各顶点对应的目标函数值是否已经非常接近。可以写成
\[ \max_j\lVert\mathbf{v}_j-\mathbf{v}_1\rVert<\epsilon_x, \qquad \max_j|f(\mathbf{v}_j)-f(\mathbf{v}_1)|<\epsilon_f. \]
这两个条件分别对应“参数位置变化不大”和“目标函数值变化不大”。
下面用 optim() 演示 Nelder–Mead 算法。我们选择经典的 Rosenbrock 函数:
\[ f(x_1,x_2)=(1-x_1)^2+100(x_2-x_1^2)^2. \]
这个函数的全局最小点是 \((1,1)\),但它的等高线呈狭长弯曲的谷地,因此常用来测试优化算法。
rosenbrock <- function(par) {
x1 <- par[1]
x2 <- par[2]
(1 - x1)^2 + 100 * (x2 - x1^2)^2
}
nm_fit <- optim(
par = c(-1.2, 1),
fn = rosenbrock,
method = "Nelder-Mead",
control = list(maxit = 1000)
)
nm_fit$par
#> [1] 1.000 1.001
nm_fit$value
#> [1] 8.825e-08
nm_fit$convergence
#> [1] 0convergence 等于 0 通常表示算法按软件设定的标准正常结束。这个例子也提醒我们,Nelder–Mead虽然使用方便,但并不保证找到全局最优。它对初始值和参数尺度比较敏感;如果不同参数的量纲差异很大,最好先做标准化,或在 optim() 中通过 control = list(parscale = ...) 调整参数尺度。对维度较高的问题,Nelder–Mead 往往会变慢,后面介绍的梯度下降和随机梯度下降更常用于大规模统计学习问题。
6.5 梯度下降与随机梯度下降算法
6.5.1 梯度下降算法
牛顿法利用二阶信息,Nelder–Mead 只利用函数值。梯度下降算法介于二者之间:它不需要海塞矩阵,但需要知道目标函数的一阶导数。对于许多统计模型,尤其是线性模型、逻辑回归和神经网络,目标函数的梯度相对容易计算,因此梯度下降成为统计计算和机器学习中非常重要的一类方法。
设 \(f(\mathbf{x})\) 是一个可微函数,我们希望最小化它。在当前位置 \(\mathbf{x}_n\),梯度\(\nabla f(\mathbf{x}_n)\) 指向函数值上升最快的方向;因此,负梯度方向\(-\nabla f(\mathbf{x}_n)\) 是最自然的下降方向。梯度下降算法的基本更新为
\[\begin{equation} \mathbf{x}_{n+1}=\mathbf{x}_n-\alpha_n\nabla f(\mathbf{x}_n), \tag{6.1} \end{equation}\]
其中 \(\alpha_n>0\) 称为学习率或步长。学习率太小,算法会走得很慢;学习率太大,目标函数值可能来回震荡,甚至发散。一个常见做法是在当前下降方向上寻找合适的步长,即
\[\begin{equation} \alpha_n=\arg\min_{\alpha>0} f\left(\mathbf{x}_n-\alpha\nabla f(\mathbf{x}_n)\right). \tag{6.2} \end{equation}\]
这称为线搜索。实际应用中也经常使用固定学习率,或者让学习率随着迭代逐渐变小。
梯度下降算法
- 选择初始值 \(\mathbf{x}_0\)、学习率规则和停止阈值,设置 \(n=0\)。
- 计算当前梯度 \(\nabla f(\mathbf{x}_n)\)。
- 按公式 (6.1) 更新参数。
- 若梯度范数、参数变化或目标函数变化已经足够小,则停止;否则令 \(n=n+1\),返回第 2 步。
梯度下降的停止条件可以参考牛顿法,例如\(\lVert\nabla f(\mathbf{x}_n)\rVert<\epsilon\)、\(\lVert\mathbf{x}_{n+1}-\mathbf{x}_n\rVert<\epsilon\),或\(|f(\mathbf{x}_{n+1})-f(\mathbf{x}_n)|<\epsilon\)。需要强调的是,只有在步长选择合适时,目标函数值才会稳定下降;公式本身并不自动保证每一步都变好。
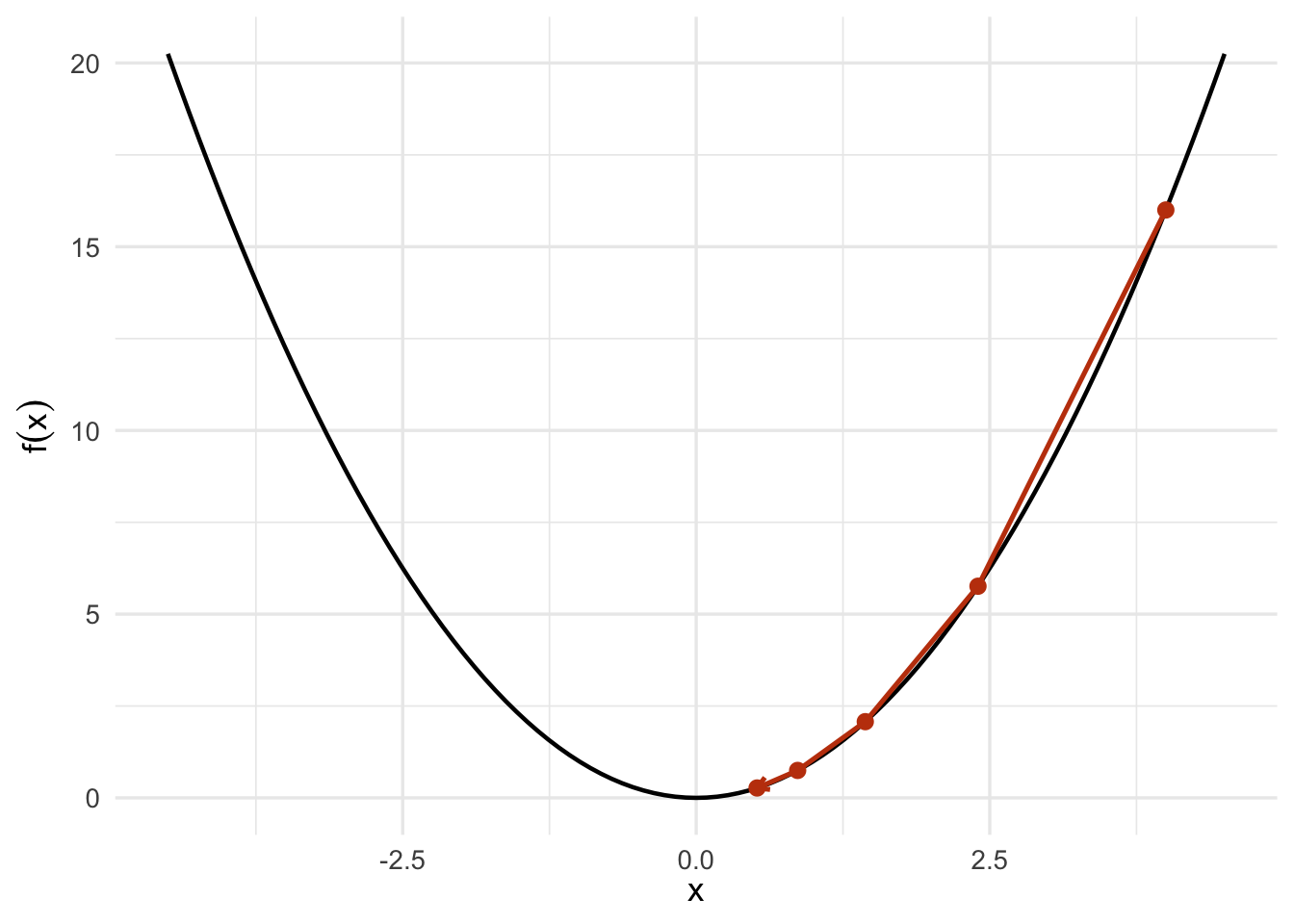
图6.4: 一元函数中的梯度下降:从右侧初始点出发,沿负梯度方向逐步靠近极小点。
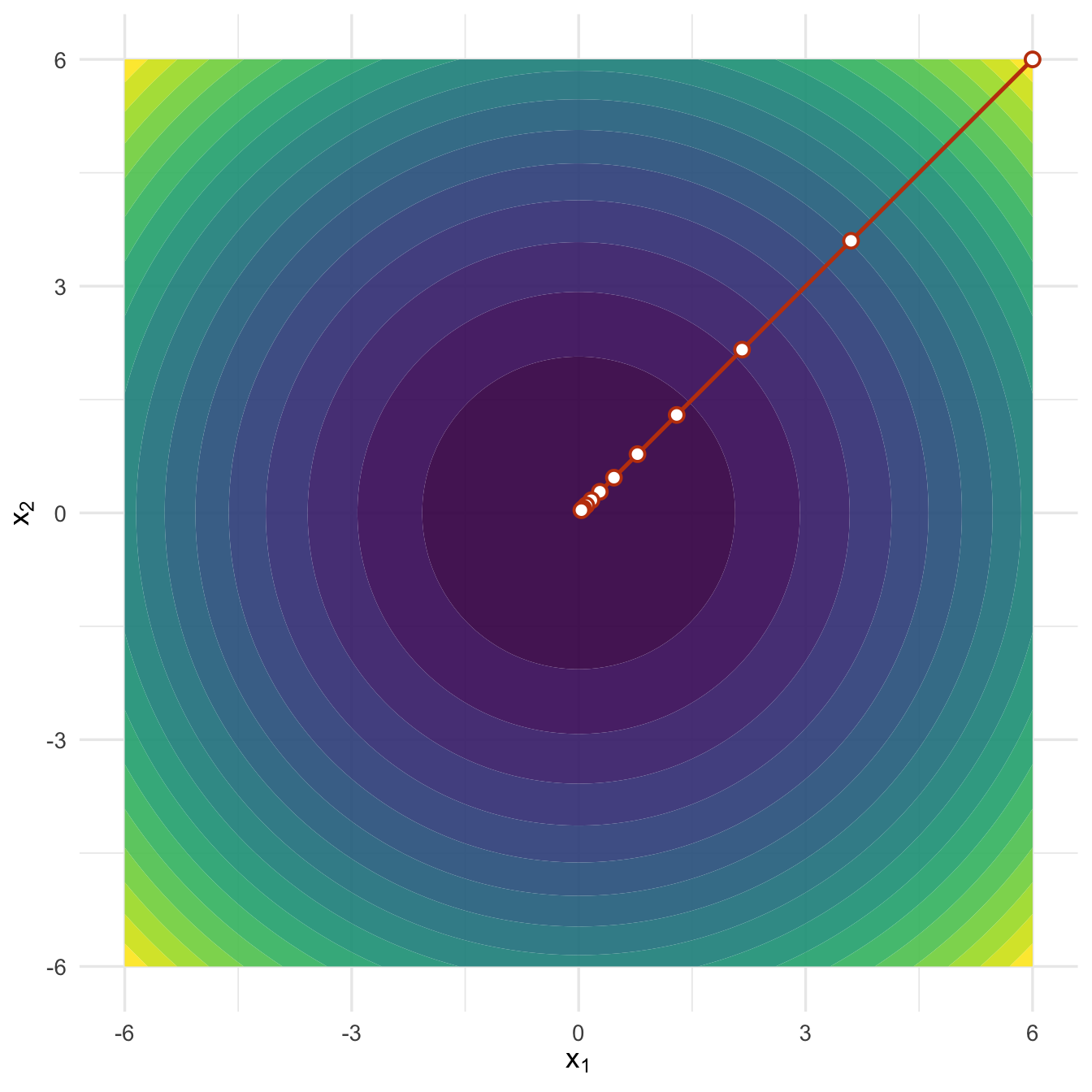
图6.5: 二元函数中的梯度下降:红色路径沿等高线的法线方向向中心移动。
在这个圆形等高线的例子中,负梯度方向几乎直接指向极小点,因此收敛很快。但实际统计模型中,参数之间常常存在相关关系,目标函数的等高线会变得狭长。此时负梯度方向可能在谷地两侧来回摆动,导致算法前进缓慢。这和第 3 章讨论的病态问题有相通之处:目标函数在不同方向上的曲率差异越大,优化越容易变慢。
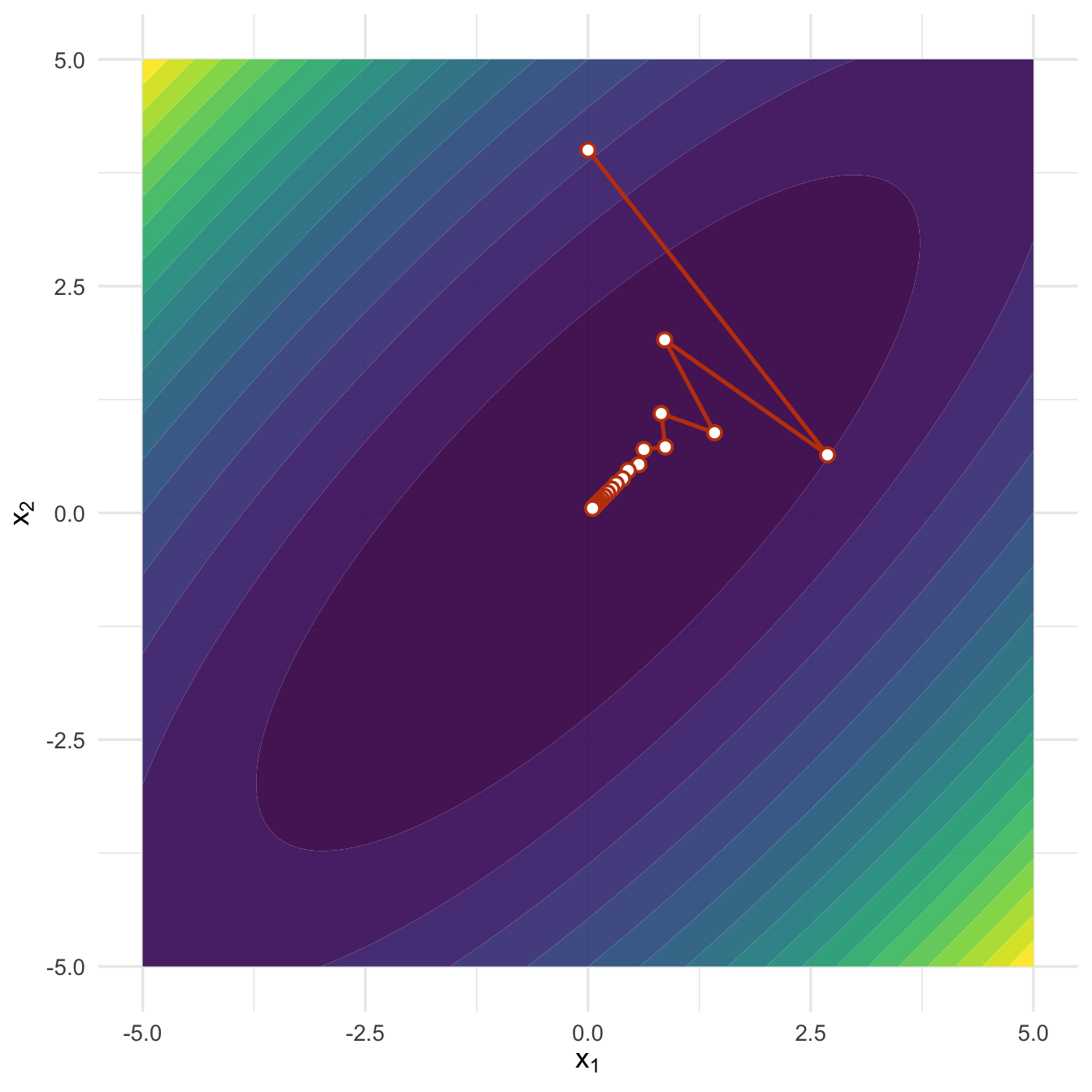
图6.6: 当参数方向高度相关时,梯度下降路径可能出现明显的来回摆动。
例6.2 用梯度下降算法估计线性回归模型。
设线性回归模型为
\[ \mathbf{y}=\mathbf{X}\beta+\eta. \]
给定 \(n\) 个观测样本,最小二乘损失可以写成
\[ J(\beta)=\frac{1}{2n}(\mathbf{X}\beta-\mathbf{y})^T(\mathbf{X}\beta-\mathbf{y}). \]
对应的梯度为
\[ \nabla J(\beta)=\frac{1}{n}\mathbf{X}^T(\mathbf{X}\beta-\mathbf{y}). \]
下面先定义线性回归的损失函数、梯度和一个简单的梯度下降函数。为了让“自动选择步长”的例子运行更快,代码中使用了二次损失函数在线搜索方向上的解析最优步长。
lm.cost <- function(X, y, beta) {
n <- length(y)
sum((X %*% beta - y)^2) / (2 * n)
}
lm.cost.grad <- function(X, y, beta) {
n <- length(y)
as.vector(t(X) %*% (X %*% beta - y) / n)
}
lm.step.size <- function(X, y, beta) {
grad <- lm.cost.grad(X, y, beta)
Xgrad <- X %*% grad
denom <- sum(Xgrad^2)
if (denom <= .Machine$double.eps) return(0)
length(y) * sum(grad^2) / denom
}
gd.lm <- function(X, y, beta.init, alpha, tol = 1e-5,
max.iter = 100) {
use_line_search <- identical(alpha, "auto")
beta <- beta.init
betas <- list(beta)
J <- list(lm.cost(X, y, beta))
converged <- FALSE
iter_done <- 0
for (iter in seq_len(max.iter)) {
grad <- lm.cost.grad(X, y, beta)
step_alpha <- if (use_line_search) lm.step.size(X, y, beta) else alpha
beta_new <- beta - step_alpha * grad
betas[[iter + 1]] <- beta_new
J[[iter + 1]] <- lm.cost(X, y, beta_new)
iter_done <- iter
if (sqrt(sum((beta_new - beta)^2)) < tol ||
abs(J[[iter + 1]] - J[[iter]]) < tol) {
converged <- TRUE
beta <- beta_new
break
}
beta <- beta_new
}
if (converged) {
cat("算法收敛\n")
} else {
cat("达到最大迭代次数\n")
}
cat("共迭代", iter_done, "次\n")
cat("系数估计为:", round(beta, 4), "\n")
list(coef = betas, cost = J, niter = iter_done,
converged = converged)
}set.seed(123)
beta0 <- 1
beta1 <- 3
sigma <- 1
n <- 10000
x <- rnorm(n, 0, 1)
y <- beta0 + x * beta1 + rnorm(n, mean = 0, sd = sigma)
X <- cbind(1, x)
gd.auto <- gd.lm(X, y, beta.init = c(-4, -5), alpha = "auto",
tol = 1e-5, max.iter = 10000)
#> 算法收敛
#> 共迭代 2 次
#> 系数估计为: 0.9909 3.006
gd1 <- gd.lm(X, y, beta.init = c(-4, -5), alpha = 0.1,
tol = 1e-5, max.iter = 10000)
#> 算法收敛
#> 共迭代 67 次
#> 系数估计为: 0.9865 2.999
gd2 <- gd.lm(X, y, beta.init = c(-4, -5), alpha = 0.01,
tol = 1e-5, max.iter = 10000)
#> 算法收敛
#> 共迭代 570 次
#> 系数估计为: 0.9743 2.979niter <- data.frame(alpha = c("auto", 0.1, 0.01),
niter = c(gd.auto$niter, gd1$niter,
gd2$niter))
knitr::kable(
niter, caption = '不同 $\\alpha$ 对应的梯度下降算法的迭代次数',
booktabs = TRUE, col.names = c("$\\alpha$", '迭代次数')
)| \(\alpha\) | 迭代次数 |
|---|---|
| auto | 2 |
| 0.1 | 67 |
| 0.01 | 570 |
从表 6.1 可以看到,步长会显著影响梯度下降的效率。自动线搜索通常能减少迭代次数;固定步长较小时,算法更稳,但移动较慢;固定步长过大时,算法则可能震荡或发散。图 6.7比较了两种固定步长下回归系数的收敛过程。
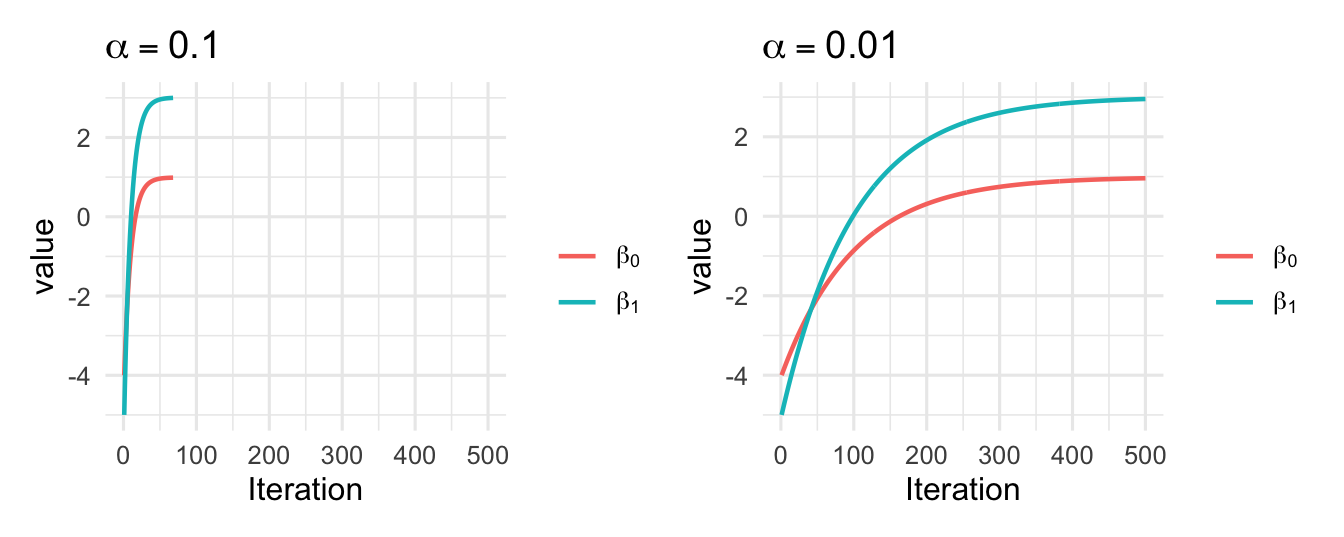
图6.7: 不同学习率下梯度下降算法的收敛过程。
6.5.2 随机梯度下降算法
普通梯度下降每一步都要使用全部样本计算梯度。当样本量很大时,这一步可能非常昂贵。随机梯度下降(Stochastic Gradient Descent,SGD)的思想是:每次只用一个样本,或一小批样本,近似完整梯度,然后马上更新参数。以线性回归为例,完整梯度为
\[ \nabla J(\beta)=\frac{1}{n}\sum_{i=1}^n \mathbf{x}_i(\mathbf{x}_i^T\beta-y_i). \]
SGD 在每次迭代中只抽取一个样本 \(i\),用
\[ \nabla J_i(\beta)=\mathbf{x}_i(\mathbf{x}_i^T\beta-y_i) \]
近似完整梯度。如果一次抽取 \(m\) 个样本,则称为小批量梯度下降,或 mini-batch gradient descent。
随机梯度下降算法
选择初始值 \(\beta_0\)、学习率 \(\alpha\)、批量大小 \(m\) 和最大迭代次数。
随机抽取一个样本或一小批样本。
用抽取到的样本计算近似梯度。
按照 \(\beta\leftarrow \beta-\alpha \widehat{\nabla J}(\beta)\) 更新参数。
重复第 2 到第 4 步,直到达到停止条件。
SGD 的单步计算成本低,特别适合大数据和在线学习。但它的路径通常比较 noisy,因为每一步看到的只是总体目标函数的一小部分。实际应用中常用的技巧包括:打乱数据顺序、使用 mini-batch、逐渐减小学习率,以及对变量做标准化。
下面给出一个用于线性回归的小批量 SGD 实现。为了便于比较,函数仍然用完整样本上的损失函数记录每次迭代后的表现。
sgd.lm <- function(X, y, beta.init,
alpha = 0.5, n.samples = 1,
tol = 1e-5, max.iter = 100) {
n <- length(y)
beta <- beta.init
betas <- list(beta)
J <- list(lm.cost(X, y, beta))
converged <- FALSE
for (iter in seq_len(max.iter)) {
batch_id <- sample.int(n, n.samples, replace = n.samples > n)
grad <- sgd.lm.cost.grad(
X[batch_id, , drop = FALSE],
y[batch_id],
beta
)
beta_new <- beta - alpha * grad
betas[[iter + 1]] <- beta_new
J[[iter + 1]] <- lm.cost(X, y, beta_new)
if (iter > 20 && abs(J[[iter + 1]] - J[[iter]]) < tol) {
converged <- TRUE
beta <- beta_new
break
}
beta <- beta_new
}
cat(ifelse(converged, "算法收敛\n", "达到最大迭代次数\n"))
cat("共迭代", length(betas) - 1, "次\n")
cat("系数估计为:", round(beta, 4), "\n")
list(coef = betas, cost = J, niter = length(betas) - 1,
converged = converged)
}
sgd.lm.cost <- function(X, y, beta) {
n <- length(y)
if (!is.matrix(X)) {
X <- matrix(X, nrow = 1)
}
sum((X %*% beta - y)^2) / (2 * n)
}
sgd.lm.cost.grad <- function(X, y, beta) {
n <- length(y)
if (!is.matrix(X)) {
X <- matrix(X, nrow = 1)
}
as.vector(t(X) %*% (X %*% beta - y) / n)
}现在在前面模拟的线性回归数据上运行 SGD。因为每次只用一个样本,参数轨迹会比普通梯度下降更抖动,但整体仍然朝着最小二乘解附近移动。
#> 算法收敛
#> 共迭代 397 次
#> 系数估计为: 1.157 2.867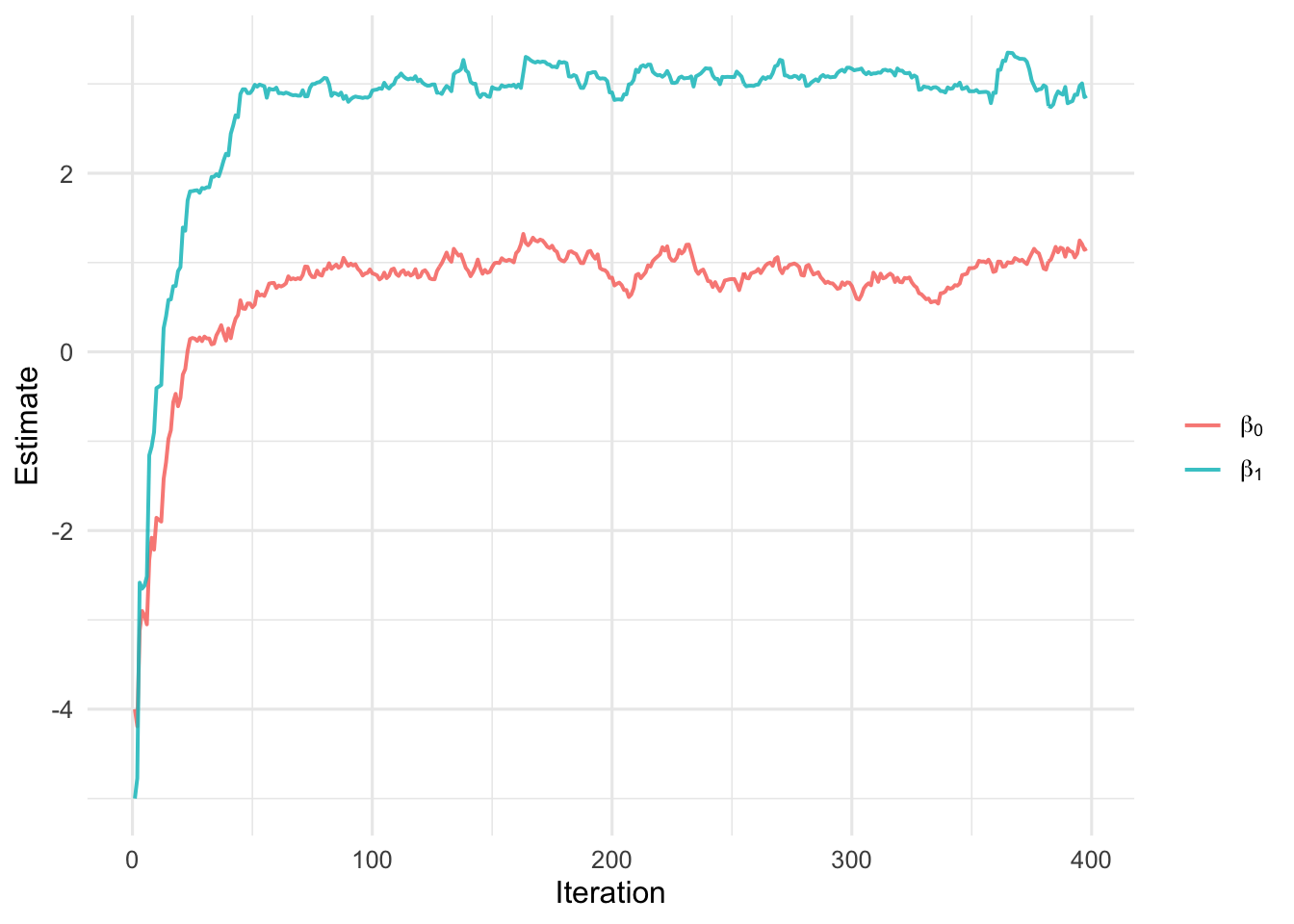
图6.8: 随机梯度下降算法的收敛过程。
SGD 的优势不在于每一步都比梯度下降更准确,而在于每一步更便宜。当样本量很大时,完整梯度下降可能要等很久才能更新一次参数;SGD 可以频繁更新,在相同计算预算下更早看到目标函数下降。它的代价是结果带有随机波动,因此通常需要配合学习率衰减、mini-batch 和多轮遍历数据来提高稳定性。
6.6 不可导优化与近端思想
前面介绍的 Newton 法、梯度下降和 SGD 都默认目标函数比较光滑,至少可以计算梯度。但在统计建模中,很多重要目标函数并不处处可导。例如,Lasso 的惩罚项包含 \(|\beta_j|\),在 \(\beta_j=0\) 处不可导;约束优化也可以写成带有指标函数的优化问题,而指标函数通常不可导。对这类问题,与其强行求梯度,不如把目标函数拆成两个部分:
\[ \min_{\mathbf{x}} f(\mathbf{x})+g(\mathbf{x}), \]
其中 \(f\) 是光滑、容易求梯度的部分,\(g\) 是不可导但结构简单的部分。近端算法的核心思想是:对\(f\) 做普通梯度步,对 \(g\) 做一个“带二次惩罚的小优化”。给定步长 \(\alpha>0\),函数 \(g\) 的近端算子定义为
\[\begin{equation} \operatorname{prox}_{\alpha g}(\mathbf{v}) = \arg\min_{\mathbf{x}} \left\{ g(\mathbf{x})+\frac{1}{2\alpha} \lVert \mathbf{x}-\mathbf{v}\rVert_2^2 \right\}. \tag{6.3} \end{equation}\]
这里的二次项要求新点不要离 \(\mathbf{v}\) 太远。如果 \(g\) 是某个集合的指标函数,近端算子就退化为向这个集合的投影;如果 \(g\) 是一范数惩罚,近端算子就是后面 Lasso 小节会用到的软阈值函数。近端梯度法可以写成
\[\begin{equation} \mathbf{x}_{k+1} = \operatorname{prox}_{\alpha_k g} \left(\mathbf{x}_k-\alpha_k\nabla f(\mathbf{x}_k)\right). \tag{6.4} \end{equation}\]
公式 (6.4) 可以理解为“先沿着光滑部分下降一步,再用近端算子处理不可导部分”。在 Lasso 中,第一步处理最小二乘损失,第二步用软阈值函数把小系数压到 0。
另一个常用思想是变量分裂。若直接处理 \(f(\mathbf{x})+g(\mathbf{x})\) 不方便,可以引入一个新变量,写成
\[ \min_{\mathbf{x},\mathbf{z}} f(\mathbf{x})+g(\mathbf{z}), \qquad \mathbf{x}=\mathbf{z}. \]
交替方向乘子法(alternating direction method of multipliers,ADMM)就是这类问题的代表算法之一。在一个简化的缩放形式下,它反复执行
\[\begin{align} \mathbf{x}_{k+1} &= \operatorname{prox}_{\alpha f}(\mathbf{z}_k-\mathbf{u}_k),\\ \mathbf{z}_{k+1} &= \operatorname{prox}_{\alpha g}(\mathbf{x}_{k+1}+\mathbf{u}_k),\\ \mathbf{u}_{k+1} &= \mathbf{u}_k+\mathbf{x}_{k+1}-\mathbf{z}_{k+1}. \end{align}\]
其中 \(\mathbf{u}\) 可以看作约束误差的累计量。ADMM 的优点是把一个复杂目标分成两个更容易处理的子问题;当其中一个子问题是二次损失、另一个是一范数惩罚时,就会得到很适合 Lasso 的迭代结构。近端算法和 ADMM 的系统介绍可见 Parikh and Boyd (2014)。
6.7 优化算法比较
到这里,我们已经看到几种不同类型的优化算法。它们没有绝对的优劣之分,关键是看问题本身:目标函数是否光滑?导数是否容易计算?样本量和参数维度有多大?我们是否更关心单步精确,还是更关心能否快速处理大规模数据?
| 算法 | 使用的信息 | 主要优点 | 主要限制 | 常见场景 |
|---|---|---|---|---|
| 牛顿法 | 梯度和海塞矩阵 | 在最优点附近通常收敛很快 | 需要二阶导数;海塞矩阵可能难算或不稳定 | 中低维、光滑、导数容易计算的问题 |
| Nelder–Mead | 只使用函数值 | 不需要导数,适合黑箱目标函数 | 高维问题较慢;不保证全局最优 | 小维度、导数不可用的局部优化 |
| 梯度下降 | 梯度 | 实现简单,适合很多可微模型 | 对学习率敏感;病态问题中可能很慢 | 中大规模可微目标函数 |
| 随机梯度下降 | 单个样本或小批量梯度 | 单步成本低,适合大数据和在线更新 | 路径有随机波动;需要调学习率 | 大样本机器学习、在线学习 |
| 近端梯度与 ADMM | 梯度、近端算子和变量分裂 | 适合光滑损失加不可导惩罚;容易利用问题结构 | 需要能快速求近端子问题;需要调步长或惩罚参数 | Lasso、稀疏模型和带约束凸优化 |
这个表只是一个经验性的选择指南。实际建模时,我们还要考虑参数尺度、初始值、停止条件和数值稳定性。有些软件会把这些思想结合起来,例如拟牛顿法、带线搜索的梯度法、带动量或自适应学习率的SGD,以及近端梯度和 ADMM 中的 warm start、因子分解缓存等,都是在基本算法上加入稳定化和加速机制。
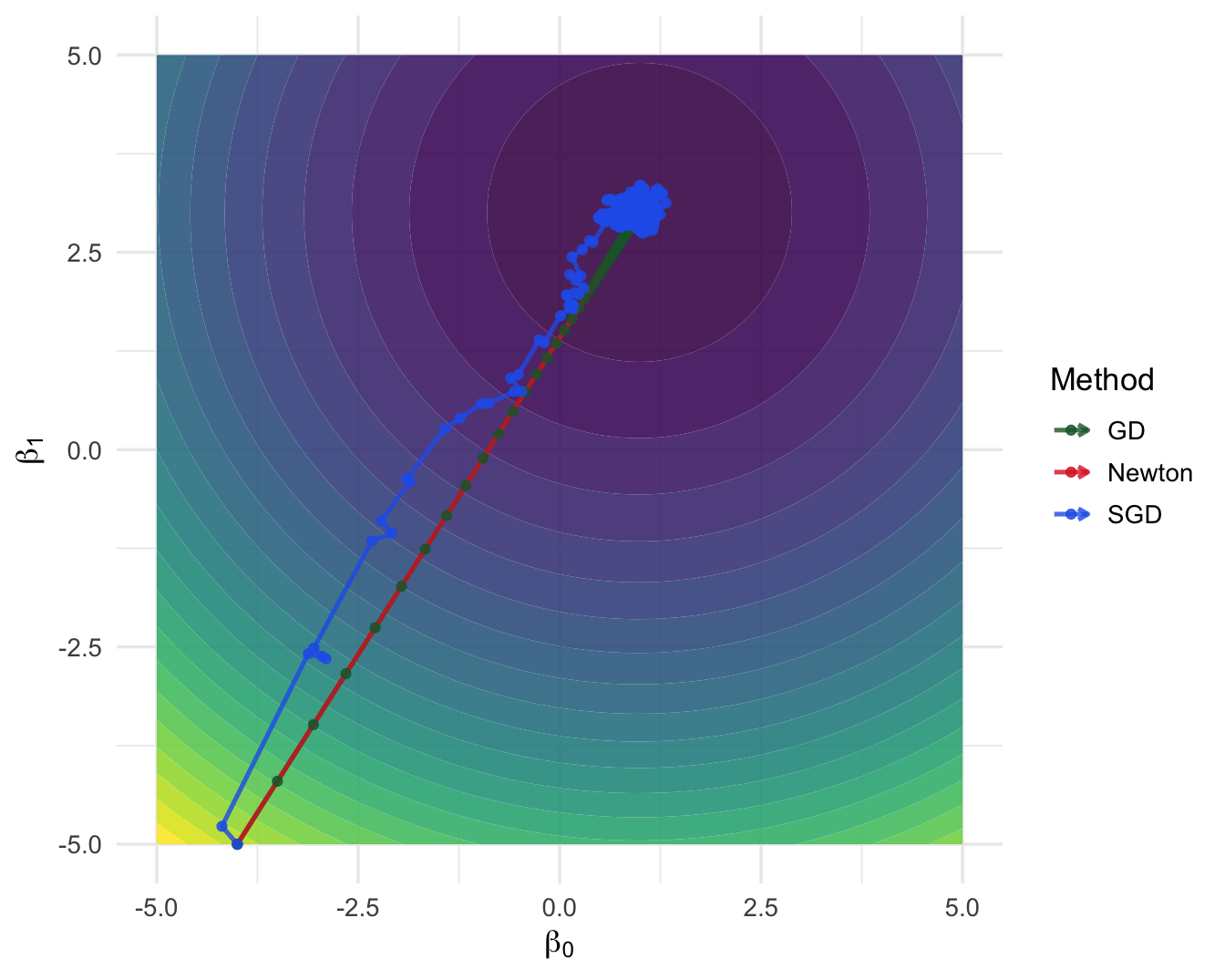
图6.9: 同一个线性回归损失函数下,牛顿法、梯度下降和随机梯度下降的迭代路径比较。
图 6.9 基于第 6.5.1 节模拟的线性回归数据,比较了三种可微优化算法在同一损失函数上的路径。这个例子是一个凸二次问题,对牛顿法非常有利;因此它不是所有优化问题的代表,而是用来帮助我们看清不同算法的计算风格。
牛顿法几乎直接到达最小点附近,因为线性回归的二次损失具有固定海塞矩阵。在这类问题中,二阶信息非常有价值。
梯度下降每一步只使用一阶信息,路径更长,但每一步的计算和实现都比较简单。它的表现很依赖步长和变量尺度。
随机梯度下降的路径带有明显波动,因为每次更新只使用一个样本。它牺牲单步精度,换取更低的单步计算成本。使用 mini-batch 可以在稳定性和速度之间取得折中。
Nelder–Mead 没有放在这张图里直接比较,因为它不利用可微结构。在小维度黑箱问题中它很有用;但对这种有明确梯度和海塞矩阵的二次损失,使用导数信息通常更高效。
在实际统计建模中,一个朴素但实用的选择顺序是:如果问题维度不高且二阶导数可靠,可以考虑牛顿法或拟牛顿法;如果目标函数可微但样本量很大,优先考虑 GD、SGD 或 mini-batch 方法;如果目标函数不可导或只能作为黑箱计算,则考虑 Nelder–Mead 这样的无导数方法。无论选择哪种算法,都应检查目标函数值、参数路径、梯度大小和对初始值的敏感性。
6.8 案例:客户流失预测
前面几节分别介绍了牛顿法、Nelder–Mead、梯度下降和随机梯度下降。现在我们用一个客户流失预测问题把这些思想放到同一个建模流程中:给定客户的服务时长、费用、合同类型和支付方式等信息,预测客户是否已经流失。本节关注的核心问题是:怎样把 Logistic 回归写成一个可优化的目标函数,并用小批量随机梯度下降计算模型参数。
Logistic 回归模型
Logistic 回归常用于二分类问题。设 \(y_i\in\{0,1\}\),\(\mathbf{x}_i\) 是第 \(i\) 个样本的解释变量向量。模型假定
\[ \Pr(y_i=1\mid \mathbf{x}_i)=p_i,\qquad p_i=\frac{1}{1+\exp(-\eta_i)},\qquad \eta_i=\mathbf{x}_i^T\beta. \]
其中 \(p_i\) 是客户流失的概率,\(\eta_i\) 是线性预测值。若 \(p_i\) 大于某个阈值,例如 0.5,就可以把样本判为 1;否则判为 0。在本节中,\(y_i=1\) 表示客户流失,\(y_i=0\) 表示客户未流失。
Logistic 回归通常通过极大似然估计参数。把极大化对数似然转化为最小化平均负对数似然,可写为
\[ J(\beta)=\frac{1}{n}\sum_{i=1}^n \left\{\log(1+\exp(\eta_i))-y_i\eta_i\right\}. \]
令 \(\mathbf{p}=(p_1,\ldots,p_n)^T\),则梯度为
\[ \nabla J(\beta)=\frac{1}{n}\mathbf{X}^T(\mathbf{p}-\mathbf{y}). \]
这个形式与线性回归中的梯度非常相似,只是线性预测值先经过了 Logistic 函数。下面用小批量随机梯度下降来最小化 \(J(\beta)\)。
SGD 实现
为了避免数值上溢,本节使用 plogis() 计算 Logistic 函数,并用稳定形式计算~\(\log(1+\exp(\eta))\)。
log1pexp <- function(z) {
pmax(z, 0) + log1p(exp(-abs(z)))
}
logistic_loss <- function(X, y, beta) {
eta <- drop(X %*% beta)
mean(log1pexp(eta) - y * eta)
}
logistic_grad <- function(X, y, beta) {
eta <- drop(X %*% beta)
p <- plogis(eta)
as.vector(crossprod(X, p - y) / length(y))
}
sgd.logisticReg <- function(X, y, beta.init, alpha = 0.2,
n.samples = 64, tol = 1e-8,
max.iter = 3000) {
n <- length(y)
beta <- beta.init
betas <- list(beta)
cost <- numeric(max.iter + 1)
cost[1] <- logistic_loss(X, y, beta)
converged <- FALSE
for (iter in seq_len(max.iter)) {
batch_id <- sample.int(n, n.samples, replace = n.samples > n)
grad <- logistic_grad(X[batch_id, , drop = FALSE], y[batch_id], beta)
step_size <- alpha / sqrt(iter)
beta_new <- beta - step_size * grad
betas[[iter + 1]] <- beta_new
cost[iter + 1] <- logistic_loss(X, y, beta_new)
if (iter > 50 && abs(cost[iter + 1] - cost[iter]) < tol) {
converged <- TRUE
beta <- beta_new
cost <- cost[seq_len(iter + 1)]
break
}
beta <- beta_new
}
if (!converged) {
cost <- cost[seq_len(max.iter + 1)]
}
cat(ifelse(converged, "算法收敛\n", "达到最大迭代次数\n"))
cat("共迭代", length(cost) - 1, "次\n")
cat("最终训练损失:", round(tail(cost, 1), 4), "\n")
list(coef = betas, cost = cost, niter = length(cost) - 1,
converged = converged)
}数据准备
本案例使用 Hugging Face 上的 scikit-learn/churn-prediction 数据集(https://huggingface.co/datasets/scikit-learn/churn-prediction)。该数据记录了电信客户的账户信息和服务使用情况。原始数据中 TotalCharges 有少量空白值,本地文件data/telco_churn_hf.csv 保留了该变量可转为数值的 7032 条记录。
churn <- read.csv("data/telco_churn_hf.csv")
churn$churn01 <- as.integer(churn$Churn == "Yes")
churn_summary <- data.frame(
指标 = c("样本量", "解释变量个数", "流失客户比例"),
数值 = c(
nrow(churn),
8,
round(mean(churn$churn01), 3)
)
)
knitr::kable(churn_summary, caption = "客户流失数据的基本情况", row.names = FALSE)| 指标 | 数值 |
|---|---|
| 样本量 | 7032.000 |
| 解释变量个数 | 8.000 |
| 流失客户比例 | 0.266 |
variable_table <- data.frame(
变量 = c(
"tenure", "MonthlyCharges", "TotalCharges", "SeniorCitizen",
"Contract", "InternetService", "PaperlessBilling", "PaymentMethod", "Churn"
),
含义 = c(
"客户使用服务的月数",
"每月费用",
"累计费用",
"是否为老年客户",
"合同类型",
"互联网服务类型",
"是否使用无纸化账单",
"支付方式",
"是否流失"
)
)
knitr::kable(variable_table, caption = "本节使用的变量", row.names = FALSE)| 变量 | 含义 |
|---|---|
| tenure | 客户使用服务的月数 |
| MonthlyCharges | 每月费用 |
| TotalCharges | 累计费用 |
| SeniorCitizen | 是否为老年客户 |
| Contract | 合同类型 |
| InternetService | 互联网服务类型 |
| PaperlessBilling | 是否使用无纸化账单 |
| PaymentMethod | 支付方式 |
| Churn | 是否流失 |
这个数据同时包含数值变量和分类变量。数值变量需要标准化,以免尺度差异影响梯度下降;分类变量则需要转换为哑变量。本节使用 R 中的 model.matrix() 完成哑变量编码。
为了避免信息泄漏,标准化只使用训练集的均值和标准差,再把同样的变换应用到测试集。
set.seed(2024)
categorical_cols <- c("Contract", "InternetService", "PaperlessBilling", "PaymentMethod")
for (nm in categorical_cols) {
churn[[nm]] <- factor(churn[[nm]], levels = sort(unique(churn[[nm]])))
}
train_id <- unlist(tapply(
seq_len(nrow(churn)),
churn$churn01,
function(idx) sample(idx, size = round(0.7 * length(idx)))
))
train_data <- churn[train_id, ]
test_data <- churn[-train_id, ]
scale_numeric_by_train <- function(train_df, test_df, cols) {
train_scaled <- train_df
test_scaled <- test_df
for (nm in cols) {
mu <- mean(train_scaled[[nm]])
sig <- sd(train_scaled[[nm]])
if (sig == 0) sig <- 1
train_scaled[[nm]] <- (train_scaled[[nm]] - mu) / sig
test_scaled[[nm]] <- (test_scaled[[nm]] - mu) / sig
}
list(train = train_scaled, test = test_scaled)
}
numeric_cols <- c("tenure", "MonthlyCharges", "TotalCharges")
scaled_data <- scale_numeric_by_train(train_data, test_data, numeric_cols)
train_data <- scaled_data$train
test_data <- scaled_data$test
design_formula <- ~ tenure + MonthlyCharges + TotalCharges +
SeniorCitizen + Contract + InternetService + PaperlessBilling + PaymentMethod
X_train <- model.matrix(design_formula, data = train_data)
y_train <- train_data$churn01
X_test <- model.matrix(design_formula, data = test_data)
y_test <- test_data$churn01模型拟合
下面用小批量 SGD 拟合 Logistic 回归。这里每次抽取 128 个样本计算近似梯度,并让学习率随迭代次数逐渐减小。由于每一步只使用一部分训练样本,所以损失曲线会有轻微波动;这正是随机梯度方法的典型特征。
set.seed(2025)
beta.init <- rep(0, ncol(X_train))
res <- sgd.logisticReg(
X_train, y_train,
beta.init = beta.init,
alpha = 0.25,
n.samples = 128,
max.iter = 3000,
tol = 1e-8
)
#> 算法收敛
#> 共迭代 1297 次
#> 最终训练损失: 0.4334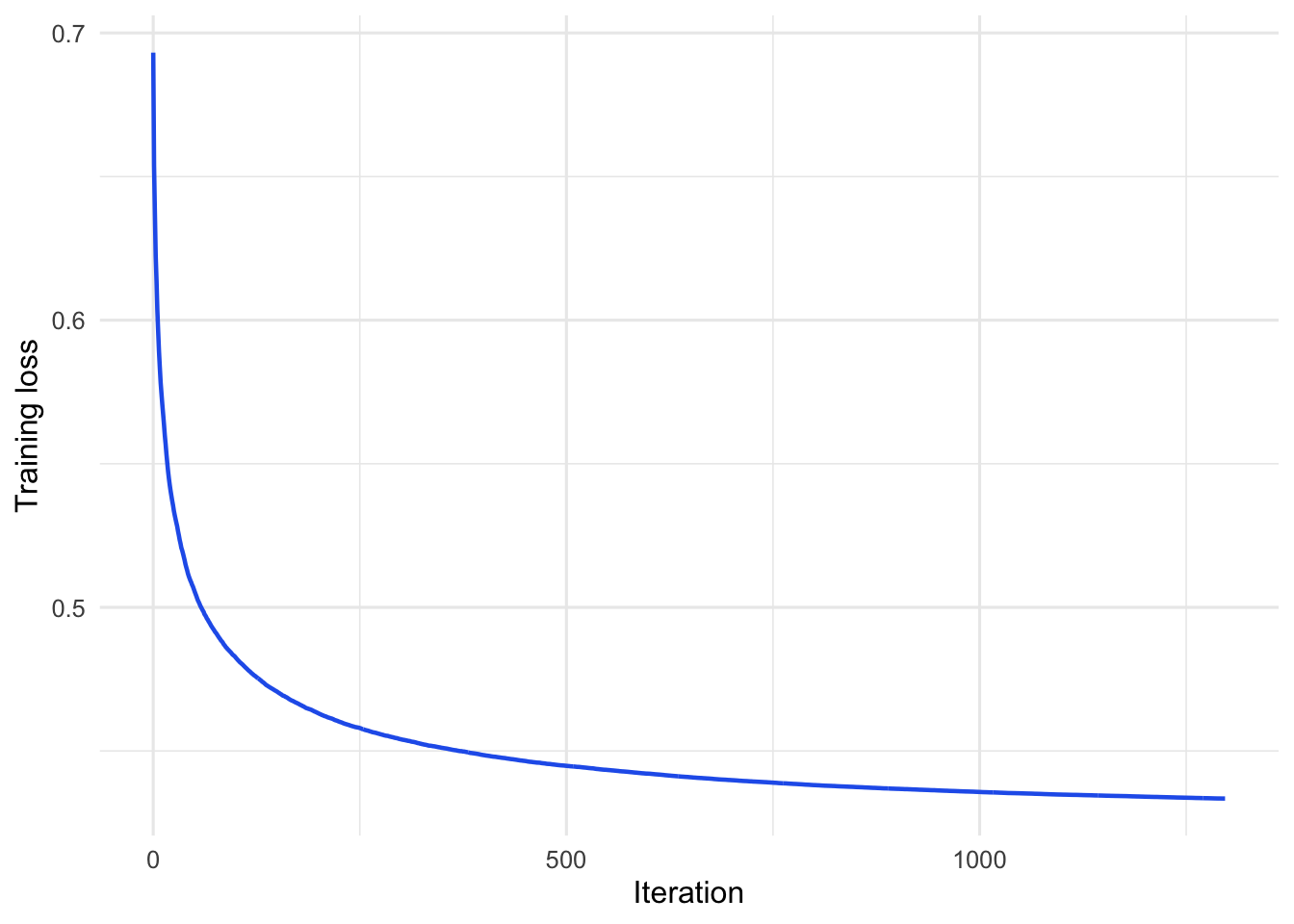
图6.10: 小批量 SGD 训练 Logistic 回归时的训练损失变化。
由于所有解释变量都已经标准化,系数绝对值较大的变量可以粗略反映模型更依赖哪些方向。这里的系数只表示预测关联,不应解释为因果效应。比如,合同类型对应的系数反映的是在其他变量进入模型后,该类别相对于基准类别的差异。
beta_hat <- res$coef[[length(res$coef)]]
coef_table <- data.frame(
variable = colnames(X_train),
coefficient = as.numeric(beta_hat)
)
coef_table <- coef_table[coef_table$variable != "(Intercept)", ]
coef_table <- coef_table[order(abs(coef_table$coefficient), decreasing = TRUE), ]
coef_table$coefficient <- round(coef_table$coefficient, 3)
coef_labels <- c(
tenure = "服务时长",
MonthlyCharges = "每月费用",
TotalCharges = "累计费用",
SeniorCitizen = "老年客户",
"ContractOne year" = "合同:一年",
"ContractTwo year" = "合同:两年",
"InternetServiceFiber optic" = "互联网服务:光纤",
InternetServiceNo = "无互联网服务",
PaperlessBillingYes = "无纸化账单",
"PaymentMethodCredit card (automatic)" = "支付:信用卡自动扣款",
"PaymentMethodElectronic check" = "支付:电子支票",
"PaymentMethodMailed check" = "支付:邮寄支票"
)
coef_table$variable <- ifelse(
coef_table$variable %in% names(coef_labels),
coef_labels[coef_table$variable],
coef_table$variable
)
knitr::kable(
head(coef_table, 8),
caption = "Logistic 回归中的标准化系数",
col.names = c("变量", "系数"),
row.names = FALSE
)| 变量 | 系数 |
|---|---|
| 服务时长 | -0.677 |
| 每月费用 | 0.601 |
| 合同:两年 | -0.511 |
| 无互联网服务 | -0.451 |
| 合同:一年 | -0.441 |
| 支付:邮寄支票 | -0.357 |
| 支付:信用卡自动扣款 | -0.306 |
| 累计费用 | -0.288 |
预测与评价
最后在测试集上计算预测概率。由于流失客户在数据中所占比例低于未流失客户,若直接采用 0.5 作为分类阈值,模型往往更容易把客户判为“未流失”。这里把阈值设为 0.35,以提高对流失客户的识别能力。准确率本身并不足以完整评价模型,因此下面同时报告灵敏度、特异度、精确率和 AUC。
prob_test <- plogis(drop(X_test %*% beta_hat))
threshold <- 0.35
y_predicted <- ifelse(prob_test >= threshold, 1, 0)
confusion <- table(
factor(y_predicted, levels = c(0, 1), labels = c("未流失", "流失")),
factor(y_test, levels = c(0, 1), labels = c("未流失", "流失"))
)
names(dimnames(confusion)) <- c("预测值", "真实值")
knitr::kable(confusion, caption = "测试集混淆矩阵")| 未流失 | 流失 | |
|---|---|---|
| 未流失 | 1188 | 188 |
| 流失 | 361 | 373 |
error_table <- data.frame(
type = c("误报:真实未流失,预测为流失", "漏判:真实流失,预测为未流失"),
count = c(confusion["流失", "未流失"], confusion["未流失", "流失"])
)
names(error_table) <- c("类型", "数量")
knitr::kable(error_table, caption = "两类错误的数量", row.names = FALSE)| 类型 | 数量 |
|---|---|
| 误报:真实未流失,预测为流失 | 361 |
| 漏判:真实流失,预测为未流失 | 188 |
auc_rank <- function(prob, y) {
r <- rank(prob)
n1 <- sum(y == 1)
n0 <- sum(y == 0)
(sum(r[y == 1]) - n1 * (n1 + 1) / 2) / (n1 * n0)
}
accuracy <- mean(y_predicted == y_test)
sensitivity <- confusion["流失", "流失"] / sum(confusion[, "流失"])
specificity <- confusion["未流失", "未流失"] / sum(confusion[, "未流失"])
precision <- confusion["流失", "流失"] / sum(confusion["流失", ])
auc <- auc_rank(prob_test, y_test)
metric_table <- data.frame(
metric = c("阈值", "准确率", "灵敏度", "特异度", "精确率", "AUC"),
value = round(c(threshold, accuracy, sensitivity, specificity, precision, auc), 3)
)
names(metric_table) <- c("指标", "数值")
knitr::kable(metric_table, caption = "测试集预测表现", row.names = FALSE)| 指标 | 数值 |
|---|---|
| 阈值 | 0.350 |
| 准确率 | 0.740 |
| 灵敏度 | 0.665 |
| 特异度 | 0.767 |
| 精确率 | 0.508 |
| AUC | 0.807 |
从这个例子可以看到,优化算法负责降低 Logistic 损失,但模型评价还需要回到预测任务本身。降低分类阈值后,模型会更容易把客户判为“流失”,通常能减少漏判,但也会增加误报。阈值选择和错误成本会影响模型在不同应用场景中的使用方式。就本章而言,关键在于理解从模型设定到计算实现的路径:先将参数估计问题写成目标函数,再推导相应的梯度,最后通过 SGD 等优化算法逐步求得参数估计值。