第 13 章 线性模型与广义线性模型的计算
线性模型和广义线性模型是经济统计中最常用的建模工具。学生在计量经济学课程中已经学习过普通最小二乘、极大似然、显著性检验和预测等内容。本章不重复这些理论,而是从计算角度重新看这些模型:估计公式如何变成稳定算法?什么时候不能直接求逆?广义线性模型为什么需要迭代?计算诊断在模型解释中扮演什么角色?
13.1 线性模型的矩阵形式
线性回归模型写作
\[ \mathbf y=\mathbf X\boldsymbol\beta+\boldsymbol\varepsilon, \]
其中 \(\mathbf y\) 是 \(n\times 1\) 的因变量向量,\(\mathbf X\) 是 \(n\times p\) 的设计矩阵,\(\boldsymbol\beta\) 是 \(p\times 1\) 的回归系数,\(\boldsymbol\varepsilon\) 是误差向量。普通最小二乘估计定义为
\[ \hat{\boldsymbol\beta} = \arg\min_{\boldsymbol\beta} (\mathbf y-\mathbf X\boldsymbol\beta)^\top (\mathbf y-\mathbf X\boldsymbol\beta). \]
一阶条件给出正规方程
\[ \mathbf X^\top\mathbf X\hat{\boldsymbol\beta} = \mathbf X^\top\mathbf y. \]
在教材中常写成
\[ \hat{\boldsymbol\beta} = (\mathbf X^\top\mathbf X)^{-1}\mathbf X^\top\mathbf y. \]
这个公式帮助我们理解估计量结构,但在程序中通常不应显式计算逆矩阵。更稳妥的做法是解线性方程组,或者使用 QR 分解。R 的 lm() 和 lm.fit() 背后主要使用的就是这类矩阵分解思想。
13.2 正规方程、QR 分解与数值稳定性
当解释变量高度相关时,\(\mathbf X^\top\mathbf X\) 的条件数可能很大,直接求逆会放大舍入误差。下面用模拟消费数据说明。
set.seed(2026)
n <- 300
income_lm <- rlnorm(n, meanlog = log(8), sdlog = 0.5)
income_lm2 <- income_lm + rnorm(n, sd = 0.001)
consumption_lm <- 1 + 0.55 * income_lm + rnorm(n, sd = 1.5)
X <- cbind(1, income_lm, income_lm2)
y <- consumption_lm
kappa(crossprod(X))
#> [1] 389449061
beta_normal <- solve(crossprod(X), crossprod(X, y))
beta_qr <- qr.coef(qr(X), y)
cbind(normal_equation = beta_normal, qr = beta_qr)
#> qr
#> 1.007 1.007
#> income_lm -152.802 -152.802
#> income_lm2 153.343 153.343两个收入变量几乎相同,单个系数会变得非常不稳定。此时问题不只是“算法不好”,也说明数据中没有足够信息区分两个变量的独立作用。计算诊断和统计解释在这里是连在一起的。
在实际建模中,可以使用以下习惯:
- 用
lm()或lm.fit(),不要手动写solve(t(X) %*% X) %*% t(X) %*% y; - 检查设计矩阵条件数、变量尺度和共线性;
- 对尺度差异很大的变量进行中心化或标准化;
- 对无法稳定识别的模型,优先重新思考变量选择和研究问题。
13.3 极大似然与广义线性模型
线性模型假设因变量在给定解释变量下服从正态分布。广义线性模型(generalized linear model, GLM)把这个框架扩展到二项、Poisson 等分布。GLM 包含三个部分:
- 随机部分:\(Y_i\) 的条件分布属于指数族;
- 系统部分:线性预测子 \(\eta_i=\mathbf x_i^\top\boldsymbol\beta\);
- 连接函数:\(g(\mu_i)=\eta_i\),其中 \(\mu_i=E(Y_i\mid\mathbf x_i)\)。
例如,逻辑回归用于二元响应变量:
\[ P(Y_i=1\mid\mathbf x_i)=p_i, \]
\[ \log\frac{p_i}{1-p_i} = \mathbf x_i^\top\boldsymbol\beta. \]
Poisson 回归用于计数变量:
\[ Y_i\mid\mathbf x_i\sim \operatorname{Poisson}(\mu_i), \]
\[ \log \mu_i=\mathbf x_i^\top\boldsymbol\beta. \]
这些模型的极大似然估计通常没有闭式解,需要通过迭代优化完成。
13.4 迭代加权最小二乘
GLM 中最常用的计算算法是迭代加权最小二乘(iteratively reweighted least squares, IRLS)。它可以理解为 Newton 方法在 GLM 中的具体实现。每一步根据当前参数计算工作响应变量 \(z_i\) 和权重 \(w_i\),然后拟合一个加权最小二乘问题。
以逻辑回归为例,当前线性预测子为
\[ \eta_i^{(t)}=\mathbf x_i^\top\boldsymbol\beta^{(t)}, \]
当前概率为
\[ p_i^{(t)}=\frac{\exp(\eta_i^{(t)})}{1+\exp(\eta_i^{(t)})}. \]
工作响应变量和权重为
\[ z_i^{(t)} = \eta_i^{(t)} + \frac{y_i-p_i^{(t)}}{p_i^{(t)}(1-p_i^{(t)})}, \]
\[ w_i^{(t)}=p_i^{(t)}(1-p_i^{(t)}). \]
然后求解
\[ \boldsymbol\beta^{(t+1)} = \arg\min_{\boldsymbol\beta} \sum_{i=1}^n w_i^{(t)}(z_i^{(t)}-\mathbf x_i^\top\boldsymbol\beta)^2. \]
下面手写一个简单 IRLS,与 glm() 结果比较。数据是模拟的信用违约数据。
set.seed(1)
n <- 400
income <- as.numeric(scale(rlnorm(n, log(8), 0.55)))
debt_ratio <- rnorm(n)
eta <- -1.2 - 0.9 * income + 0.8 * debt_ratio
default <- rbinom(n, size = 1, prob = plogis(eta))
X <- cbind(1, income, debt_ratio)
y <- default
beta <- rep(0, ncol(X))
for (iter in 1:30) {
eta_hat <- drop(X %*% beta)
p_hat <- plogis(eta_hat)
w <- pmax(p_hat * (1 - p_hat), 1e-8)
z <- eta_hat + (y - p_hat) / w
Xw <- X * sqrt(w)
zw <- z * sqrt(w)
beta_new <- qr.coef(qr(Xw), zw)
if (max(abs(beta_new - beta)) < 1e-8) break
beta <- beta_new
}
beta
#> income debt_ratio
#> -1.0587 -0.9975 0.5788
coef(glm(default ~ income + debt_ratio, family = binomial()))
#> (Intercept) income debt_ratio
#> -1.0587 -0.9975 0.5788实际使用中,我们通常调用 glm()。手写 IRLS 的目的,是理解 GLM 估计为什么是一个迭代计算问题,以及为什么收敛、权重和变量尺度会影响估计结果。
13.5 计算诊断
模型拟合后,至少应检查以下计算和统计诊断:
- 收敛信息。GLM 是否达到收敛?迭代次数是否异常多?
- 条件数和共线性。设计矩阵是否病态?变量是否高度相关?
- 残差与异常点。少数观测是否对估计产生过大影响?
- 拟合与预测。模型是否只是在训练样本内拟合得好?
- 解释稳定性。变量加入或删除后,核心系数是否大幅改变?
下面查看一个线性模型的基本诊断量。
fit_lm <- lm(consumption_lm ~ income_lm)
c(kappa = kappa(model.matrix(fit_lm)),
sigma = summary(fit_lm)$sigma,
max_hat = max(hatvalues(fit_lm)),
max_cooks = max(cooks.distance(fit_lm)))
#> kappa sigma max_hat max_cooks
#> 25.17789 1.46361 0.07154 0.04664这些数字本身不是结论,而是提示我们是否需要进一步检查数据、模型或变量定义。
13.6 案例:共享单车日租赁量的完整计算流程
下面用一个真实数据案例展示本章的计算流程。UCI Machine Learning Repository 的 Bike Sharing 数据集记录了美国华盛顿特区 Capital Bikeshare 系统在 2011–2012 年的租赁量,并加入天气、季节和日历变量。本书使用其中的日度数据 day.csv,共 731 天。数据说明见https://archive.ics.uci.edu/dataset/275/bike+sharing+dataset。
研究问题是:天气、季节、工作日和年份信息如何与日租赁量相关?这里的因变量 cnt 是一天内总租赁次数,属于非负计数。为了连接线性模型和广义线性模型,我们同时拟合两个模型:
- 对 \(\log(\texttt{cnt})\) 拟合普通线性回归;
- 对
cnt拟合 Poisson 和准 Poisson 回归。
bike <- read.csv("data/bike_sharing_day.csv")
bike$season <- factor(
bike$season,
levels = 1:4,
labels = c("spring", "summer", "fall", "winter")
)
bike$workingday <- factor(
bike$workingday,
levels = c(0, 1),
labels = c("nonworking", "working")
)
bike$year <- factor(
bike$yr,
levels = c(0, 1),
labels = c("2011", "2012")
)
bike$weathersit <- factor(
bike$weathersit,
levels = sort(unique(bike$weathersit)),
labels = c("clear", "mist", "light_rain")
)
bike$log_cnt <- log(bike$cnt)
bike_info <- data.frame(
days = nrow(bike),
start = min(bike$dteday),
end = max(bike$dteday),
mean_count = mean(bike$cnt)
)
knitr::kable(bike_info, row.names = FALSE, digits = 1)| days | start | end | mean_count |
|---|---|---|---|
| 731 | 2011-01-01 | 2012-12-31 | 4504 |
线性模型使用的形式为
\[ \log(y_i)=\mathbf x_i^\top\boldsymbol\beta+\varepsilon_i, \]
其中 \(y_i\) 是第 \(i\) 天的租赁次数,\(\mathbf x_i\) 包含温度、湿度、风速、工作日、季节、天气状况和年份等解释变量。Poisson GLM 使用
\[ Y_i\mid \mathbf x_i\sim \operatorname{Poisson}(\mu_i),\qquad \log\mu_i=\mathbf x_i^\top\boldsymbol\beta. \]
这里 \(\mu_i=E(Y_i\mid\mathbf x_i)\),表示给定当天条件下的期望租赁次数。准 Poisson 回归使用相同的均值结构,但允许
\[ \operatorname{Var}(Y_i\mid\mathbf x_i)=\phi\mu_i, \]
其中 \(\phi\) 是离散度参数。若 \(\phi>1\),说明数据比 Poisson 模型允许的波动更大。
lm_formula <- log_cnt ~ temp + hum + windspeed + workingday +
season + weathersit + year
glm_formula <- cnt ~ temp + hum + windspeed + workingday +
season + weathersit + year
fit_bike_lm <- lm(lm_formula, data = bike)
fit_bike_pois <- glm(glm_formula, data = bike, family = poisson())
fit_bike_qpois <- glm(glm_formula, data = bike, family = quasipoisson())
bike_model_diag <- data.frame(
model = c("log-linear LM", "Poisson GLM", "quasi-Poisson GLM"),
irls_iter = c(NA, fit_bike_pois$iter, fit_bike_qpois$iter),
kappa = c(
kappa(model.matrix(fit_bike_lm)),
kappa(model.matrix(fit_bike_pois)),
kappa(model.matrix(fit_bike_qpois))
),
dispersion = c(
summary(fit_bike_lm)$sigma^2,
fit_bike_pois$deviance / fit_bike_pois$df.residual,
summary(fit_bike_qpois)$dispersion
)
)
knitr::kable(bike_model_diag, row.names = FALSE, digits = 3)| model | irls_iter | kappa | dispersion |
|---|---|---|---|
| log-linear LM | NA | 14.76 | 0.09 |
| Poisson GLM | 4 | 14.76 | 187.11 |
| quasi-Poisson GLM | 4 | 14.76 | 174.20 |
表中的 irls_iter 显示 Poisson 和准 Poisson 模型都是通过 IRLS 完成的。设计矩阵条件数不高,说明这个例子中的数值病态并不严重。更值得注意的是离散度:Poisson 模型要求条件方差等于条件均值,但这里残差离散度远大于 1,说明日租赁量的波动明显超过简单 Poisson 模型。因此,在解释标准误和置信区间时,准 Poisson 模型更稳妥。
下面查看准 Poisson 模型的部分系数。由于使用对数连接函数,系数指数化后可以解释为期望租赁量的乘数变化。
qpois_coef <- coef(fit_bike_qpois)
bike_coef_table <- data.frame(
term = names(qpois_coef),
estimate = qpois_coef,
rate_ratio = exp(qpois_coef)
)
knitr::kable(bike_coef_table, row.names = FALSE, digits = 3)| term | estimate | rate_ratio |
|---|---|---|
| (Intercept) | 7.522 | 1848.298 |
| temp | 1.215 | 3.371 |
| hum | -0.255 | 0.775 |
| windspeed | -0.575 | 0.563 |
| workingdayworking | 0.039 | 1.040 |
| seasonsummer | 0.348 | 1.416 |
| seasonfall | 0.257 | 1.294 |
| seasonwinter | 0.465 | 1.592 |
| weathersitmist | -0.099 | 0.905 |
| weathersitlight_rain | -0.726 | 0.484 |
| year2012 | 0.459 | 1.582 |
例如,year2012 的系数若为正,表示控制天气、季节和工作日后,2012 年的日租赁期望量高于 2011 年。天气变量的解释也类似:温度系数为正表示较高温度通常对应更高租赁量,weathersitlight_rain 的系数为负则表示轻雨或小雪天气下租赁量更低。
最后构造两个天气和季节画像,比较线性模型和准 Poisson 模型给出的预测。这里的目的不是给出运营决策中的最终预测系统,而是展示模型设定会如何影响计算结果。
bike_profile <- data.frame(
temp = c(0.25, 0.65),
hum = c(0.70, 0.55),
windspeed = c(0.25, 0.15),
workingday = factor(c("working", "working"),
levels = levels(bike$workingday)),
season = factor(c("spring", "fall"), levels = levels(bike$season)),
weathersit = factor(c("mist", "clear"),
levels = levels(bike$weathersit)),
year = factor(c("2012", "2012"), levels = levels(bike$year))
)
bike_prediction <- data.frame(
profile = c("cool misty workday", "warm clear workday"),
lm_prediction = exp(predict(fit_bike_lm, newdata = bike_profile)),
qpois_prediction = predict(
fit_bike_qpois,
newdata = bike_profile,
type = "response"
)
)
knitr::kable(bike_prediction, row.names = FALSE, digits = 1)| profile | lm_prediction | qpois_prediction |
|---|---|---|
| cool misty workday | 2392 | 2705 |
| warm clear workday | 7088 | 6913 |
plot(bike$cnt, fitted(fit_bike_qpois),
xlab = "Observed daily rentals",
ylab = "Fitted daily rentals",
pch = 20, col = "#0072B255")
abline(0, 1, col = "red", lwd = 2)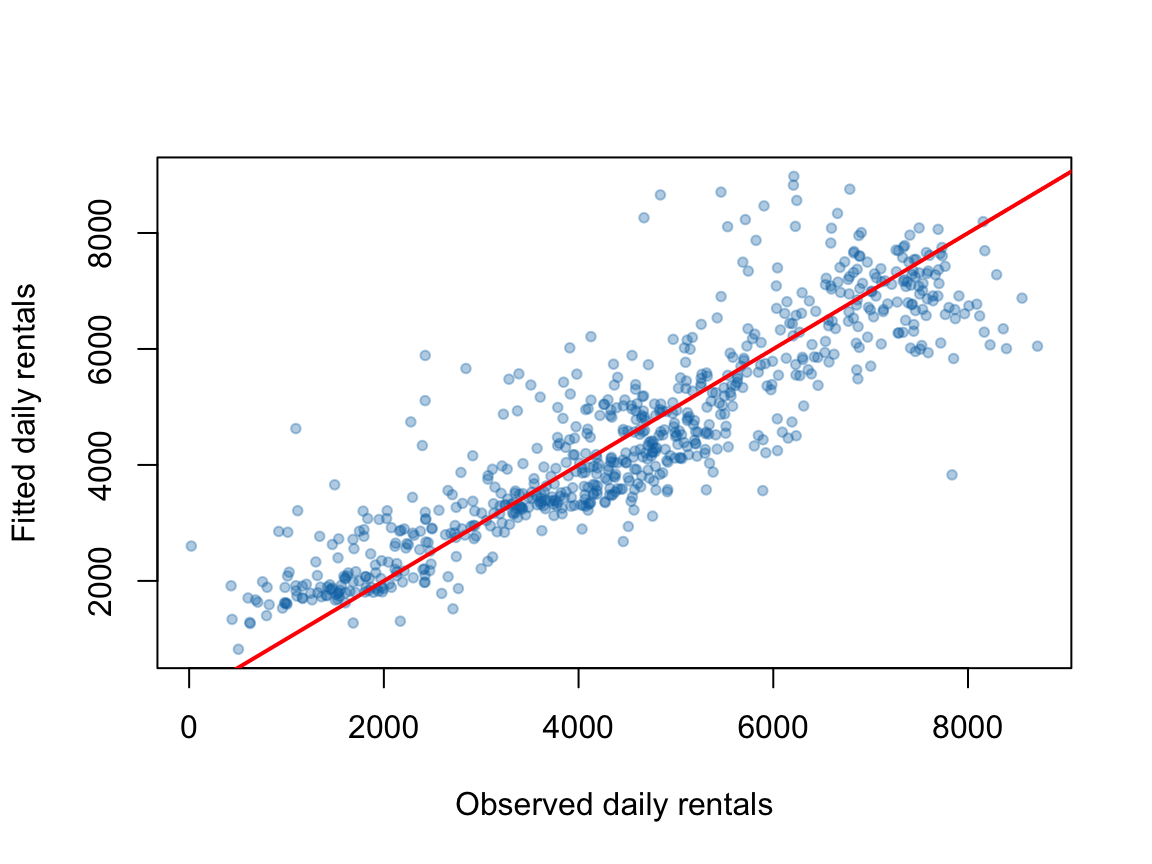
图13.1: 共享单车日租赁量的观测值与准 Poisson 拟合值。
这个案例把本章的几个计算主题连在一起:线性模型中使用 QR 分解避免显式求逆;GLM 通过 IRLS 迭代求解;真实计数数据可能存在过度离散;模型诊断不仅服务于程序是否收敛,也直接影响经济统计解释。